Version 2.10.1-alpha Jul 03, 2026
1. Format Overview
1.1. Namespace – NWB core
Description: NWB namespace
Name: core
Full Name: NWB core
Version: 2.10.1-alpha
- Authors:
Andrew Tritt
Oliver Ruebel
Ryan Ly
Ben Dichter
Keith Godfrey
Jeff Teeters
- Schema:
namespace: hdmf-common
doc: This source module contains base data types used throughout the NWB data format.
source: nwb.base.yaml
title: Base data types
doc: This source module contains neurodata_types for device data.
source: nwb.device.yaml
title: Devices
doc: This source module contains neurodata_types for epoch data.
source: nwb.epoch.yaml
title: Epochs
doc: This source module contains neurodata_types for event data.
source: nwb.event.yaml
title: Events
doc: This source module contains neurodata_types for image data.
source: nwb.image.yaml
title: Image data
doc: Main NWB file specification.
source: nwb.file.yaml
title: NWB file
doc: Miscellaneous types.
source: nwb.misc.yaml
title: Miscellaneous neurodata_types.
doc: This source module contains neurodata_types for behavior data.
source: nwb.behavior.yaml
title: Behavior
doc: This source module contains neurodata_types for extracellular electrophysiology data.
source: nwb.ecephys.yaml
title: Extracellular electrophysiology
doc: This source module contains neurodata_types for intracellular electrophysiology data.
source: nwb.icephys.yaml
title: Intracellular electrophysiology
doc: This source module contains neurodata_types for optogenetics data.
source: nwb.ogen.yaml
title: Optogenetics
doc: This source module contains neurodata_types for optical physiology data.
source: nwb.ophys.yaml
title: Optical physiology
doc: This source module contains neurodata_type for retinotopy data.
source: nwb.retinotopy.yaml
title: Retinotopy
1.2. Type Hierarchy
2. Type Specifications
2.1. Base data types
This source module contains base data types used throughout the NWB data format.
2.1.1. NWBData
Overview: An abstract data type for a dataset.
NWBData extends Data and includes all elements of Data with the following additions or changes.
Extends: Data
Primitive Type: Dataset
Inherits from: Data
Subtypes: Image, ExternalImage, BaseImage, ScratchData, ImageReferences, GrayscaleImage, RGBImage, RGBAImage
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.1
2.1.2. TimeSeriesReferenceVectorData
Overview: Column storing references into one or more TimeSeries objects. Each row of this column stores a start index and count into a referenced TimeSeries and an object reference to that TimeSeries.
TimeSeriesReferenceVectorData extends VectorData and includes all elements of VectorData with the following additions or changes.
Extends: VectorData
Primitive Type: Dataset
- Data Type: Compound data type with the following elements:
idx_start: Start index into the TimeSeries ‘data’ and ‘timestamp’ datasets of the referenced TimeSeries. The first dimension of those arrays is always time. (dtype= int32 )
count: Number of data samples available in this time series, during this epoch. (dtype= int32 )
timeseries: The TimeSeries object that this reference refers to. (dtype= object reference to TimeSeries )
Default Name: timeseries
Inherits from: VectorData, Data
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.2
2.1.3. BaseImage
Overview: An abstract base type for image data. Parent type for Image and ExternalImage types.
BaseImage extends NWBData and includes all elements of NWBData with the following additions or changes.
Extends: NWBData
Primitive Type: Dataset
Subtypes: Image, ExternalImage, GrayscaleImage, RGBImage, RGBAImage
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.3
Id |
Type |
Description |
|---|---|---|
<BaseImage> |
Dataset |
Top level Dataset for <BaseImage>
|
—description |
Attribute |
Description of the image.
|
2.1.4. Image
Overview: A type for storing image data directly. Shape can be 2-D (x, y), or 3-D where the third dimension can have three or four elements, e.g., (x, y, (r, g, b)) or (x, y, (r, g, b, a)).
Image extends BaseImage and includes all elements of BaseImage with the following additions or changes.
Extends: BaseImage
Primitive Type: Dataset
Data Type: numeric
Dimensions: [[‘x’, ‘y’], [‘x’, ‘y’, ‘r, g, b’], [‘x’, ‘y’, ‘r, g, b, a’]]
Shape: [[None, None], [None, None, 3], [None, None, 4]]
Subtypes: GrayscaleImage, RGBAImage, RGBImage
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.4
Id |
Type |
Description |
|---|---|---|
<Image> |
Dataset |
Top level Dataset for <Image>
|
—resolution |
Attribute |
Pixel resolution of the image, in pixels per centimeter.
|
2.1.5. ExternalImage
Overview: A type for referencing an external image file. The single file path or URI to the external image file should be stored in the dataset. This type should NOT be used if the image is stored in another NWB file and that file is linked to this file.
ExternalImage extends BaseImage and includes all elements of BaseImage with the following additions or changes.
Extends: BaseImage
Primitive Type: Dataset
Data Type: text
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.5

Id |
Type |
Description |
|---|---|---|
<ExternalImage> |
Dataset |
Top level Dataset for <ExternalImage>
|
—image_mode |
Attribute |
Image mode (color mode) of the image, e.g., “RGB”, “RGBA”, “grayscale”, and “LA”.
|
—image_format |
Attribute |
Common name of the image file format. Only widely readable, open file formats are allowed. Allowed values are “PNG”, “JPEG”, and “GIF”.
|
2.1.6. ImageReferences
Overview: Ordered dataset of references to BaseImage (e.g., Image or ExternalImage) objects.
ImageReferences extends NWBData and includes all elements of NWBData with the following additions or changes.
Extends: NWBData
Primitive Type: Dataset
Data Type: object reference to BaseImage
Dimensions: [‘num_images’]
Shape: [None]
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.6
2.1.7. NWBContainer
Overview: An abstract data type for a generic container storing collections of data and metadata. Base type for all data and metadata containers.
NWBContainer extends Container and includes all elements of Container with the following additions or changes.
Extends: Container
Primitive Type: Group
Inherits from: Container
Subtypes: RoiResponseSeries, LabMetaData, Position, OptogeneticStimulusSite, ImageSeries, BehavioralEvents, DeviceModel, OpticalSeries, BehavioralEpochs, IZeroClampSeries, Fluorescence, Device, FeatureExtraction, Subject, OptogeneticSeries, CurrentClampStimulusSeries, FilteredEphys, CompassDirection, PupilTracking, VoltageClampStimulusSeries, DecompositionSeries, EyeTracking, IntracellularElectrode, TimeSeries, EventWaveform, ImageSegmentation, CorrectedImageStack, IntervalSeries, CurrentClampSeries, ElectrodeGroup, ImagingPlane, NWBDataInterface, VoltageClampSeries, ImageMaskSeries, SpikeEventSeries, EventDetection, OnePhotonSeries, ProcessingModule, BehavioralTimeSeries, ClusterWaveforms, SpatialSeries, DfOverF, IndexSeries, NWBFile, ElectricalSeries, TwoPhotonSeries, AbstractFeatureSeries, AnnotationSeries, Images, LFP, Clustering, OpticalChannel, MotionCorrection, ImagingRetinotopy, PatchClampSeries
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.7
2.1.8. NWBDataInterface
Overview: An abstract data type for a generic container storing collections of data, as opposed to metadata.
NWBDataInterface extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Subtypes: RoiResponseSeries, Position, ImageSeries, BehavioralEvents, OpticalSeries, BehavioralEpochs, IZeroClampSeries, Fluorescence, FeatureExtraction, OptogeneticSeries, CurrentClampStimulusSeries, FilteredEphys, CompassDirection, PupilTracking, VoltageClampStimulusSeries, DecompositionSeries, EyeTracking, TimeSeries, EventWaveform, ImageSegmentation, CorrectedImageStack, IntervalSeries, CurrentClampSeries, VoltageClampSeries, ImageMaskSeries, SpikeEventSeries, EventDetection, OnePhotonSeries, BehavioralTimeSeries, ClusterWaveforms, SpatialSeries, DfOverF, IndexSeries, ElectricalSeries, TwoPhotonSeries, AbstractFeatureSeries, AnnotationSeries, Images, LFP, Clustering, MotionCorrection, ImagingRetinotopy, PatchClampSeries
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.8
2.1.9. TimeSeries
Overview: General purpose time series.
TimeSeries extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Inherits from: NWBDataInterface, NWBContainer, Container
Subtypes: RoiResponseSeries, ImageSeries, OpticalSeries, IZeroClampSeries, OptogeneticSeries, CurrentClampStimulusSeries, VoltageClampStimulusSeries, DecompositionSeries, IntervalSeries, CurrentClampSeries, VoltageClampSeries, ImageMaskSeries, SpikeEventSeries, OnePhotonSeries, SpatialSeries, IndexSeries, ElectricalSeries, TwoPhotonSeries, AbstractFeatureSeries, AnnotationSeries, PatchClampSeries
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.9
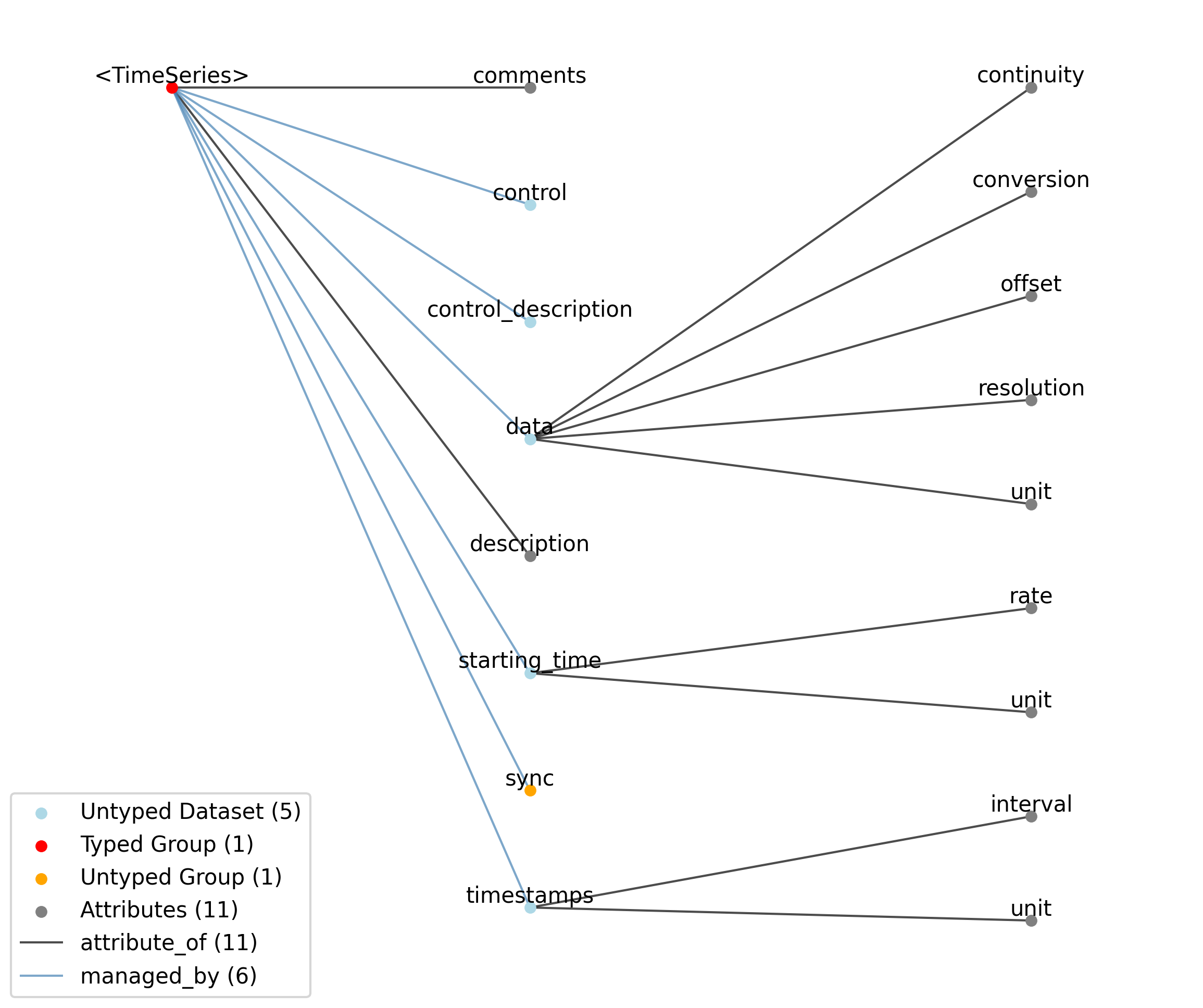
Id |
Type |
Description |
|---|---|---|
<TimeSeries> |
Group |
Top level Group for <TimeSeries>
|
—description |
Attribute |
Description of the time series.
|
—comments |
Attribute |
Human-readable comments about the TimeSeries. This second descriptive field can be used to store additional information, or descriptive information if the primary description field is populated with a computer-readable string.
|
—data |
Dataset |
Data values. Data can be in 1-D, 2-D, 3-D, or 4-D. The first dimension should always represent time. This can also be used to store binary data (e.g., image frames). This can also be a link to data stored in an external file.
|
——conversion |
Attribute |
Scalar to multiply each element in data to convert it to the specified ‘unit’. If the data are stored in acquisition system units or other units that require a conversion to be interpretable, multiply the data by ‘conversion’ to convert the data to the specified ‘unit’. For example, if the data acquisition system stores values in this object as signed 16-bit integers (int16 range -32,768 to 32,767) that correspond to a 5V range (-2.5V to 2.5V), and the data acquisition system gain is 8000X, then the ‘conversion’ multiplier to get from raw data acquisition values to recorded volts is 2.5/32768/8000 = 9.5367e-9.
|
——offset |
Attribute |
Scalar to add to the data after scaling by ‘conversion’ to finalize its coercion to the specified ‘unit’. Two common examples of this include (a) data stored in an unsigned type that requires a shift after scaling to re-center the data, and (b) specialized recording devices that naturally cause a scalar offset with respect to the true units.
|
——resolution |
Attribute |
Smallest meaningful difference between values in data, stored in the specified unit, e.g., the change in value of the least significant bit, or a larger number if signal noise is known to be present. If unknown, use -1.0.
|
——unit |
Attribute |
Base unit of measurement for working with the data. Actual stored values are not necessarily stored in these units. To access the data in these units, multiply ‘data’ by ‘conversion’ and add ‘offset’.
|
——continuity |
Attribute |
Optionally describe the continuity of the data. Can be “continuous”, “instantaneous”, or “step”. For example, a voltage trace would be “continuous”, because samples are recorded from a continuous process. An array of lick times would be “instantaneous”, because the data represents distinct moments in time. Times of image presentations would be “step” because the picture remains the same until the next timepoint. This field is optional, but is useful in providing information about the underlying data. It may inform the way this data is interpreted, the way it is visualized, and what analysis methods are applicable. For storing instantaneous event information, it is recommended to use an EventsTable instead of a TimeSeries with continuity set to “instantaneous”.
|
—starting_time |
Dataset |
Timestamp of the first sample in seconds. When timestamps are uniformly spaced, the timestamp of the first sample can be specified and all subsequent ones calculated from the sampling rate attribute.
|
——rate |
Attribute |
Sampling rate, in Hz.
|
——unit |
Attribute |
Unit of measurement for time, which is fixed to ‘seconds’.
|
—timestamps |
Dataset |
Timestamps for samples stored in data, in seconds, relative to the common experiment master clock stored in NWBFile.timestamps_reference_time.
|
——interval |
Attribute |
Value is ‘1’
|
——unit |
Attribute |
Unit of measurement for timestamps, which is fixed to ‘seconds’.
|
—control |
Dataset |
Numerical labels that apply to each time point in data for the purpose of querying and slicing data by these values. If present, the length of this array should be the same as the length of the first dimension of data.
|
—control_description |
Dataset |
Description of each control value. Must be present if control is present. If present, control_description[0] should describe time points where control == 0.
|
Id |
Type |
Description |
|---|---|---|
<TimeSeries> |
Group |
Top level Group for <TimeSeries>
|
—sync |
Group |
Lab-specific time and sync information as provided directly from hardware devices and that is necessary for aligning all acquired time information to a common timebase. The timestamp array stores time in the common timebase. This group will usually only be populated in TimeSeries that are stored external to the NWB file, in files storing raw data. Once timestamp data is calculated, the contents of ‘sync’ are mostly for archival purposes.
|
2.1.9.1. Groups: sync
Lab-specific time and sync information as provided directly from hardware devices and that is necessary for aligning all acquired time information to a common timebase. The timestamp array stores time in the common timebase. This group will usually only be populated in TimeSeries that are stored external to the NWB file, in files storing raw data. Once timestamp data is calculated, the contents of ‘sync’ are mostly for archival purposes.
Quantity: 0 or 1
Name: sync
2.1.10. ProcessingModule
Overview: A collection of processed data.
ProcessingModule extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.10
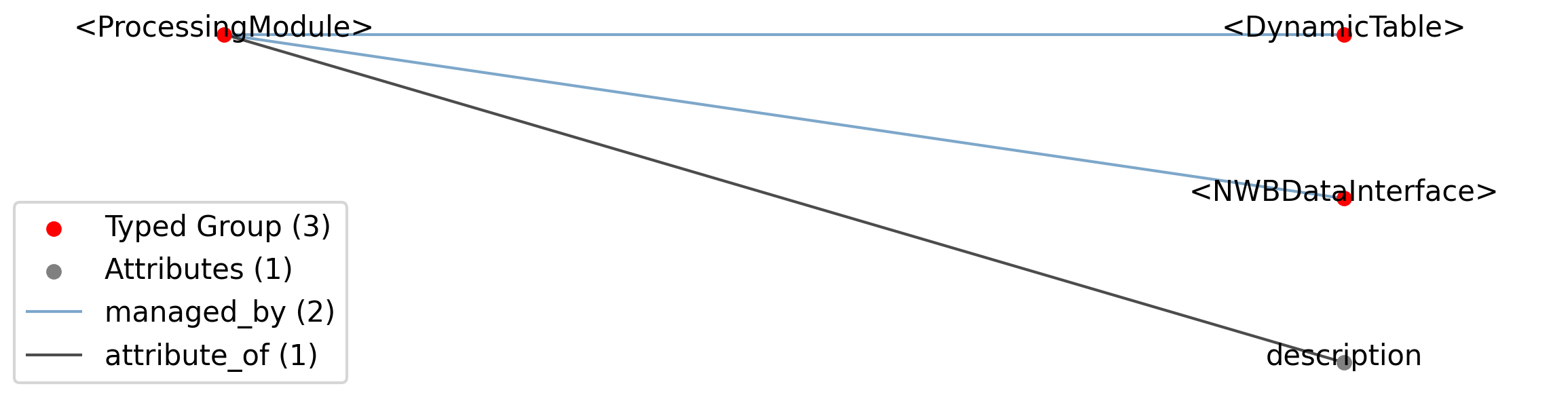
Id |
Type |
Description |
|---|---|---|
<ProcessingModule> |
Group |
Top level Group for <ProcessingModule>
|
—description |
Attribute |
Description of this collection of processed data.
|
Id |
Type |
Description |
|---|---|---|
<ProcessingModule> |
Group |
Top level Group for <ProcessingModule>
|
Group |
Data objects stored in this collection.
|
|
—<DynamicTable> |
Group |
Tables stored in this collection.
|
2.1.10.1. Groups: <NWBDataInterface>
Data objects stored in this collection.
Extends: NWBDataInterface
Quantity: 0 or more
2.1.10.2. Groups: <DynamicTable>
Tables stored in this collection.
Extends: DynamicTable
Quantity: 0 or more
2.1.11. Images
Overview: A collection of images with an optional way to specify the order of the images using the “order_of_images” dataset. An order must be specified if the images are referenced by index, e.g., from an IndexSeries.
Images extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: Images
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.base.yaml
Source Specification: see Section 3.2.11
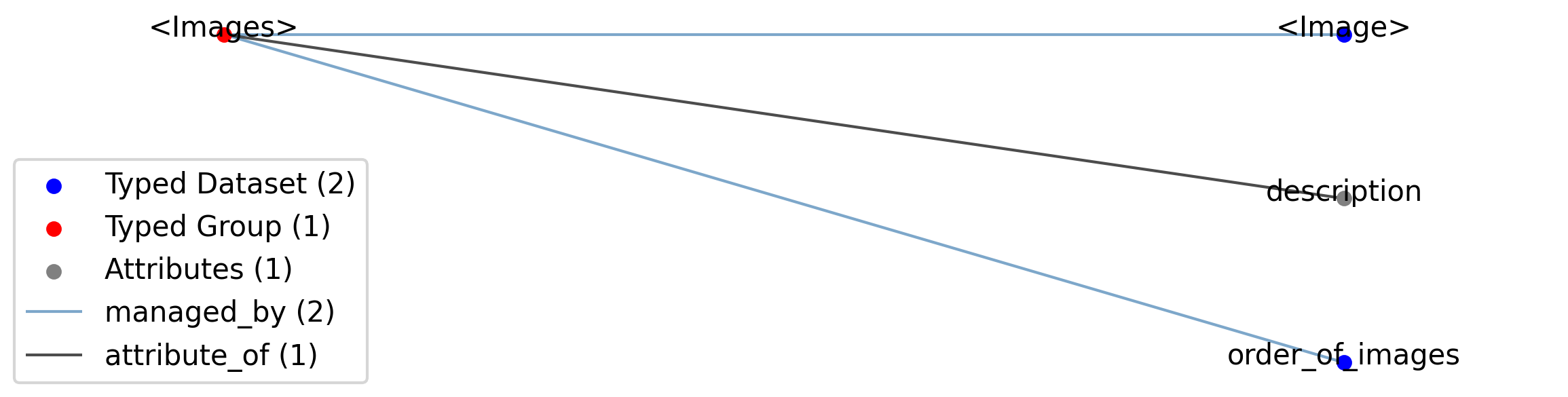
Id |
Type |
Description |
|---|---|---|
<Images> |
Group |
Top level Group for <Images>
|
—description |
Attribute |
Description of this collection of images.
|
—<BaseImage> |
Dataset |
Images stored in this collection.
|
—order_of_images |
Dataset |
Ordered dataset of references to BaseImage objects stored in the parent group. Each object in the Images group should be stored once and only once, so the dataset should have the same length as the number of images.
|
2.2. Devices
This source module contains neurodata_types for device data.
2.2.1. Device
Overview: Metadata about a specific instance of a data acquisition device, e.g., recording system, electrode, microscope. Link to a DeviceModel.model to represent information about the model of the device.
Device extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.device.yaml
Source Specification: see Section 3.3.1

Id |
Type |
Description |
|---|---|---|
<Device> |
Group |
Top level Group for <Device>
|
—description |
Attribute |
Description of the device as free-form text. If there is any software/firmware associated with the device, the names and versions of those can be added to NWBFile.was_generated_by.
|
—manufacturer |
Attribute |
DEPRECATED. The name of the manufacturer of the device, e.g., Imec, Plexon, Thorlabs. Instead of using this field, store the value in DeviceModel.manufacturer and link to that DeviceModel from this Device.
|
—model_number |
Attribute |
DEPRECATED. The model number (or part/product number) of the device, e.g., PRB_1_4_0480_1, PLX-VP-32-15SE(75)-(260-80)(460-10)-300-(1)CON/32m-V, BERGAMO. Instead of using this field, store the value in DeviceModel.model_number and link to that DeviceModel from this Device.
|
—model_name |
Attribute |
DEPRECATED. The model name of the device, e.g., Neuropixels 1.0, V-Probe, Bergamo III. Instead of using this field, create and add a new DeviceModel named the model name and link to that DeviceModel from this Device.
|
—serial_number |
Attribute |
The serial number of the device.
|
—model |
Link |
The model of the device.
|
Id |
Type |
Description |
|---|---|---|
<Device> |
Group |
Top level Group for <Device>
|
—model |
Link |
The model of the device.
|
2.2.2. DeviceModel
Overview: Model properties of a data acquisition device, e.g., recording system, electrode, microscope. This should be extended for specific types of device models to include additional attributes specific to each type. The name of the DeviceModel should be the most common representation of the model name, e.g., Neuropixels 1.0, V-Probe, Bergamo III.
DeviceModel extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.device.yaml
Source Specification: see Section 3.3.2
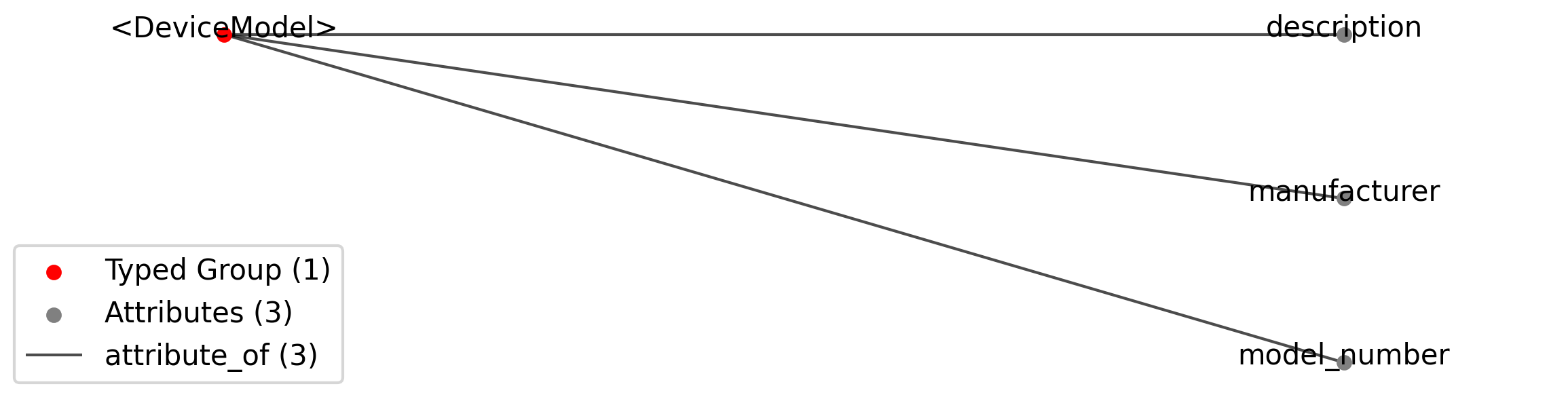
Id |
Type |
Description |
|---|---|---|
<DeviceModel> |
Group |
Top level Group for <DeviceModel>
|
—manufacturer |
Attribute |
The name of the manufacturer of the device model, e.g., Imec, Plexon, Thorlabs.
|
—model_number |
Attribute |
The model number (or part/product number) of the device, e.g., PRB_1_4_0480_1, PLX-VP-32-15SE(75)-(260-80)(460-10)-300-(1)CON/32m-V, BERGAMO.
|
—description |
Attribute |
Description of the device model as free-form text.
|
2.3. Epochs
This source module contains neurodata_types for epoch data.
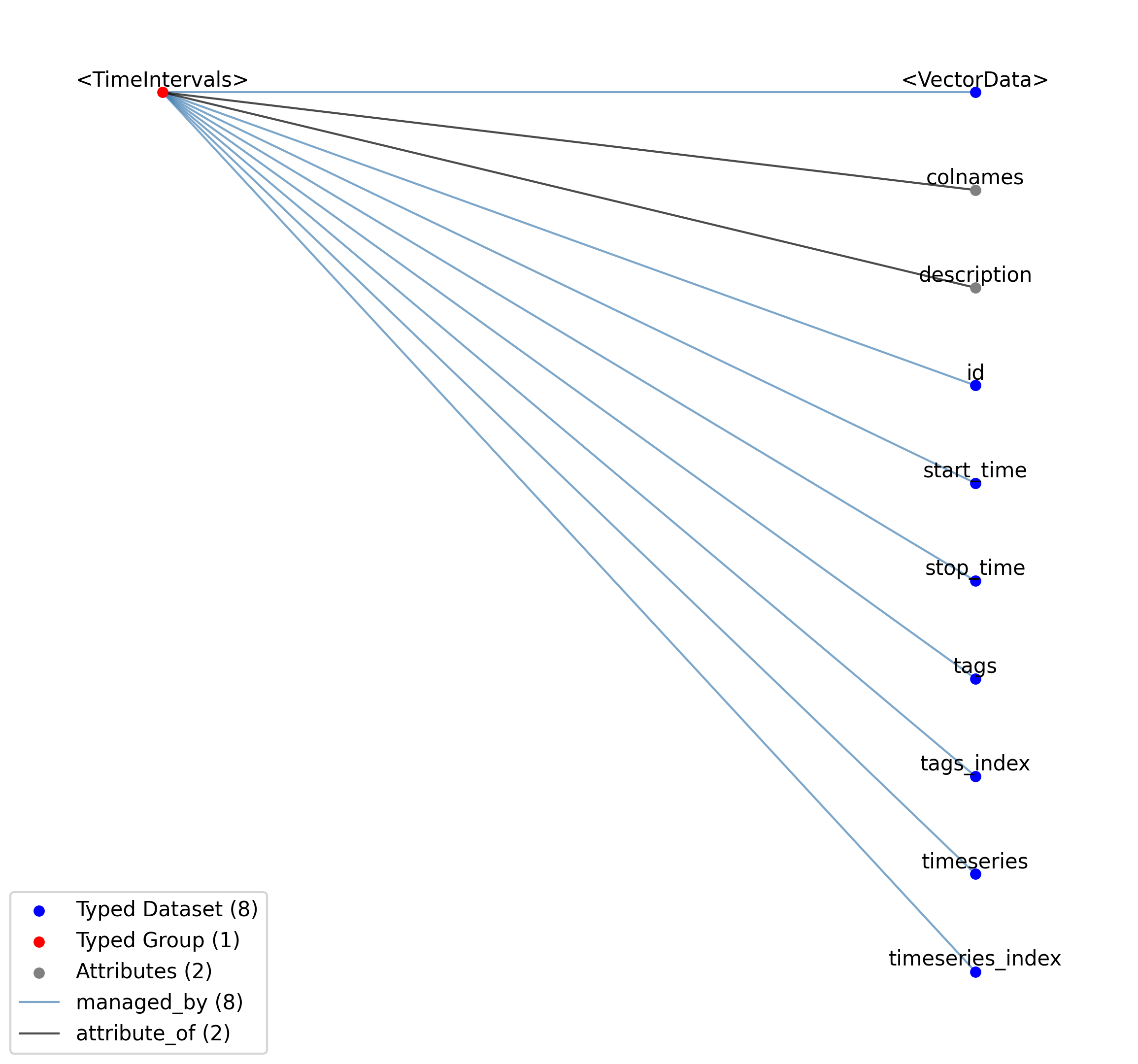
2.3.1. TimeIntervals
Overview: A column-based table to store information about time intervals, one interval per row. Use TimeIntervals when each row naturally has a start and stop time and represents a contiguous period of time, often encompassing an experimental condition. Rows can optionally reference TimeSeries data via the timeseries column. Examples include trials, epochs, behavioral states (e.g., “running”, “resting”), and invalid recording windows.
TimeIntervals extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Inherits from: DynamicTable, Container
Source filename: nwb.epoch.yaml
Source Specification: see Section 3.4.1
Id |
Type |
Description |
|---|---|---|
<TimeIntervals> |
Group |
Top level Group for <TimeIntervals>
|
—start_time |
Dataset |
Start time of epoch, in seconds.
|
—stop_time |
Dataset |
Stop time of epoch, in seconds.
|
—tags |
Dataset |
User-defined tags that identify or categorize events.
|
—tags_index |
Dataset |
Index for tags.
|
—timeseries |
Dataset |
An index into a TimeSeries object.
|
—timeseries_index |
Dataset |
Index for timeseries.
|
2.4. Events
This source module contains neurodata_types for event data.
2.4.1. TimestampVectorData
Overview: A 1-D VectorData that stores timestamps in seconds from the session start time. Timestamps are not required to be sorted in time.
TimestampVectorData extends VectorData and includes all elements of VectorData with the following additions or changes.
Extends: VectorData
Primitive Type: Dataset
Data Type: float
Dimensions: [‘num_times’]
Shape: [None]
Inherits from: VectorData, Data
Source filename: nwb.event.yaml
Source Specification: see Section 3.5.1

Id |
Type |
Description |
|---|---|---|
<TimestampVectorData> |
Dataset |
Top level Dataset for <TimestampVectorData>
|
—unit |
Attribute |
The unit of measurement for the timestamps, fixed to ‘seconds’.
|
—resolution |
Attribute |
The temporal resolution of the timestamps, in seconds. This is typically the sampling period (1 / sampling_rate), also known as the clock period, of the data acquisition system from which the timestamps were recorded or derived.
|
2.4.2. DurationVectorData
Overview: A 1-D VectorData that stores durations in seconds.
DurationVectorData extends VectorData and includes all elements of VectorData with the following additions or changes.
Extends: VectorData
Primitive Type: Dataset
Data Type: float
Dimensions: [‘num_times’]
Shape: [None]
Inherits from: VectorData, Data
Source filename: nwb.event.yaml
Source Specification: see Section 3.5.2

Id |
Type |
Description |
|---|---|---|
<DurationVectorData> |
Dataset |
Top level Dataset for <DurationVectorData>
|
—unit |
Attribute |
The unit of measurement for the durations, fixed to ‘seconds’.
|
—resolution |
Attribute |
The temporal resolution of the durations, in seconds. This is typically the sampling period (1 / sampling_rate), also known as the clock period, of the data acquisition system from which the durations were recorded or derived.
|
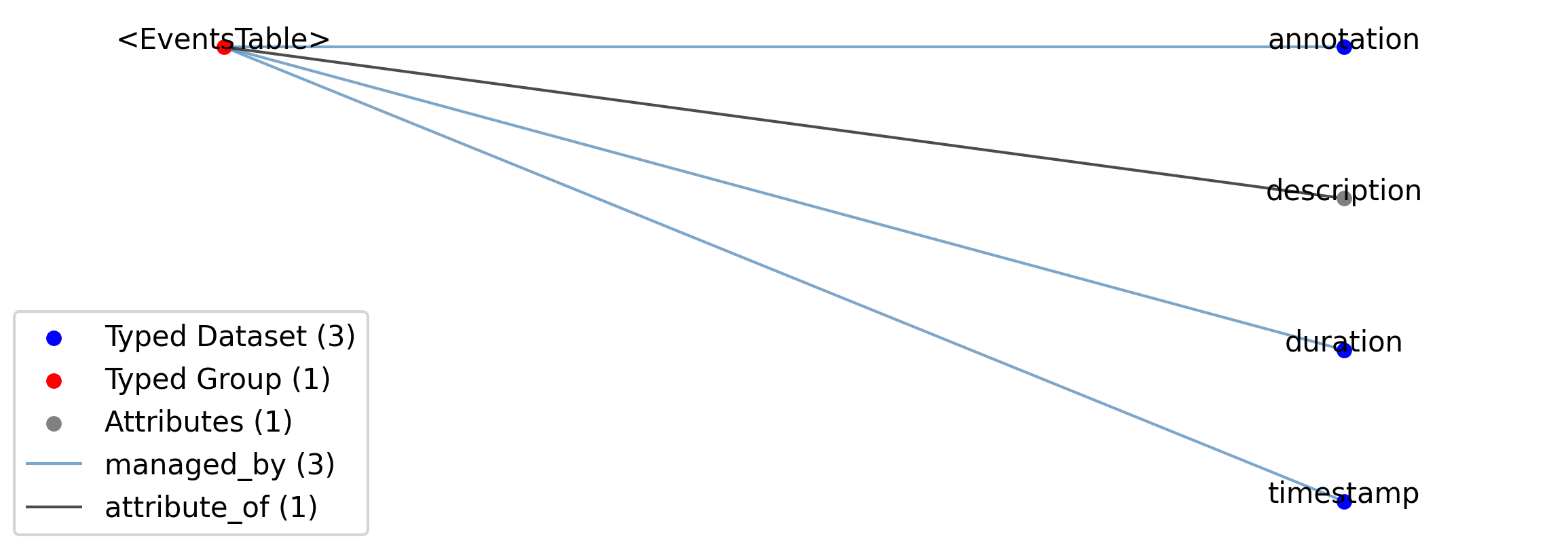
2.4.3. EventsTable
Overview: A column-based table to store information about events, one event per row. Use EventsTable when each row is anchored at a single timestamp and duration is absent, optional, or mixed across rows. Additional columns may be added to store metadata about each event, such as the duration of the event. Examples include TTL pulses, licks, rewards, stimulus onsets, and detected ripples. Each EventsTable should hold events of a single type, so that all rows share the same set of per-event metadata columns. Events of different types (e.g., licks and stimulus presentations) should be stored in separate EventsTable instances.
EventsTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Inherits from: DynamicTable, Container
Source filename: nwb.event.yaml
Source Specification: see Section 3.5.3
Id |
Type |
Description |
|---|---|---|
<EventsTable> |
Group |
Top level Group for <EventsTable>
|
—description |
Attribute |
A description of the events stored in the table, including information about how the event times were computed, especially if the times are the result of processing or filtering raw data. For example, if the experimenter is encoding different types of events using a strobed or N-bit encoding, then the description should describe which channels were used and how the event time is computed, e.g., as the rise time of the first bit.
|
—source_description |
Attribute |
Optional short text description of where the events came from, applying to every row in the table. For example, “Acquisition system” for events emitted directly by the acquisition system (e.g., TTL edges or hardware event channels); “Thresholding of analog signal ANALOG1 at 3 V” for events produced by a detection algorithm run on acquired data; or “Manual video review” for events added by a human annotator. This is a free-text label of origin only; use description for the longer narrative of how the event times were computed (channels used, encoding scheme, algorithm parameters, etc.).
|
—timestamp |
Dataset |
Column containing the time that each event occurred, in seconds, from the session start time.
|
—duration |
Dataset |
Optional column containing the duration of each event, in seconds. A value of NaN can be used for events without a duration or with a duration that is not yet specified.
|
—annotation |
Dataset |
Column containing user annotations about events.
|
2.5. Image data
This source module contains neurodata_types for image data.
2.5.1. GrayscaleImage
Overview: A grayscale image.
GrayscaleImage extends Image and includes all elements of Image with the following additions or changes.
2.5.2. RGBImage
Overview: A color image.
RGBImage extends Image and includes all elements of Image with the following additions or changes.
2.5.3. RGBAImage
Overview: A color image with transparency.
RGBAImage extends Image and includes all elements of Image with the following additions or changes.
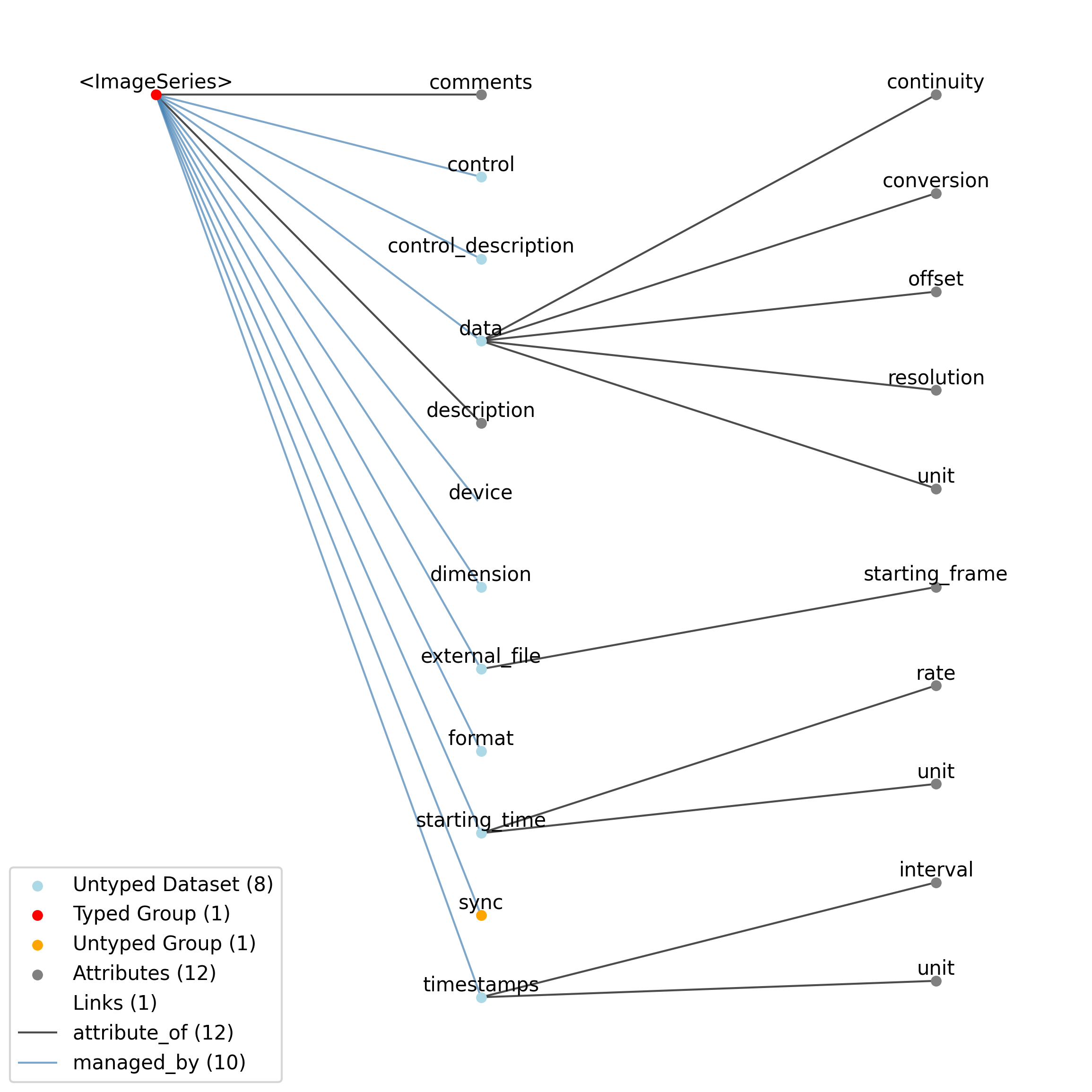
2.5.4. ImageSeries
Overview: General image data that is common between acquisition and stimulus time series. Sometimes the image data is stored in the file in a raw format while other times it will be stored as a series of external image files in the host file system. The data field will either be binary data, if the data is stored in the NWB file, or empty, if the data is stored in an external image stack. [frame][x][y] or [frame][x][y][z].
ImageSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Subtypes: ImageMaskSeries, OpticalSeries, TwoPhotonSeries, OnePhotonSeries
Source filename: nwb.image.yaml
Source Specification: see Section 3.6.4
Id |
Type |
Description |
|---|---|---|
<ImageSeries> |
Group |
Top level Group for <ImageSeries>
|
—data |
Dataset |
Binary data representing images across frames. If data are stored in an external file, this should be an empty 3-D array.
|
—dimension |
Dataset |
Number of pixels on x, y, (and z) axes.
|
—external_file |
Dataset |
Paths to one or more external file(s). The field is only present if format=’external’. This is only relevant if the image series is stored in the file system as one or more image file(s). This field should NOT be used if the image is stored in another NWB file and that file is linked to this file.
|
——starting_frame |
Attribute |
Each external image may contain one or more consecutive frames of the full ImageSeries. This attribute serves as an index to indicate which frames each file contains, to facilitate random access. The ‘starting_frame’ attribute, hence, contains a list of frame numbers within the full ImageSeries of the first frame of each file listed in the parent ‘external_file’ dataset. Zero-based indexing is used (hence, the first element will always be zero). For example, if the ‘external_file’ dataset has three paths to files and the first file has 5 frames, the second file has 10 frames, and the third file has 20 frames, then this attribute will have values [0, 5, 15]. If there is a single external file that holds all of the frames of the ImageSeries (and so there is a single element in the ‘external_file’ dataset), then this attribute should have value [0].
|
—num_samples |
Dataset |
Total number of frames across all external files. This is required when format=’external’ and timing is described using starting_time and rate, since data is empty and its first dimension cannot be used to determine the number of frames. When timestamps is provided, len(timestamps) already serves this purpose.
|
—format |
Dataset |
Format of image. If this is ‘external’, then the attribute ‘external_file’ contains the path information to the image files. If this is ‘raw’, then the raw (single-channel) binary data is stored in the ‘data’ dataset. If this attribute is not present, then the default format=’raw’ case is assumed.
|
—device |
Link |
Link to the Device object that was used to capture these images.
|
Id |
Type |
Description |
|---|---|---|
<ImageSeries> |
Group |
Top level Group for <ImageSeries>
|
—device |
Link |
Link to the Device object that was used to capture these images.
|
2.5.5. ImageMaskSeries
Overview: DEPRECATED. An alpha mask that is applied to a presented visual stimulus. The ‘data’ array contains an array of mask values that are applied to the displayed image. Mask values are stored as RGBA. Mask can vary with time. The timestamps array indicates the starting time of a mask, and that mask pattern continues until it is explicitly changed.
ImageMaskSeries extends ImageSeries and includes all elements of ImageSeries with the following additions or changes.
Extends: ImageSeries
Primitive Type: Group
Inherits from: ImageSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.image.yaml
Source Specification: see Section 3.6.5
Id |
Type |
Description |
|---|---|---|
<ImageMaskSeries> |
Group |
Top level Group for <ImageMaskSeries>
|
—masked_imageseries |
Link |
Link to ImageSeries object that this image mask is applied to.
|
Id |
Type |
Description |
|---|---|---|
<ImageMaskSeries> |
Group |
Top level Group for <ImageMaskSeries>
|
—masked_imageseries |
Link |
Link to ImageSeries object that this image mask is applied to.
|
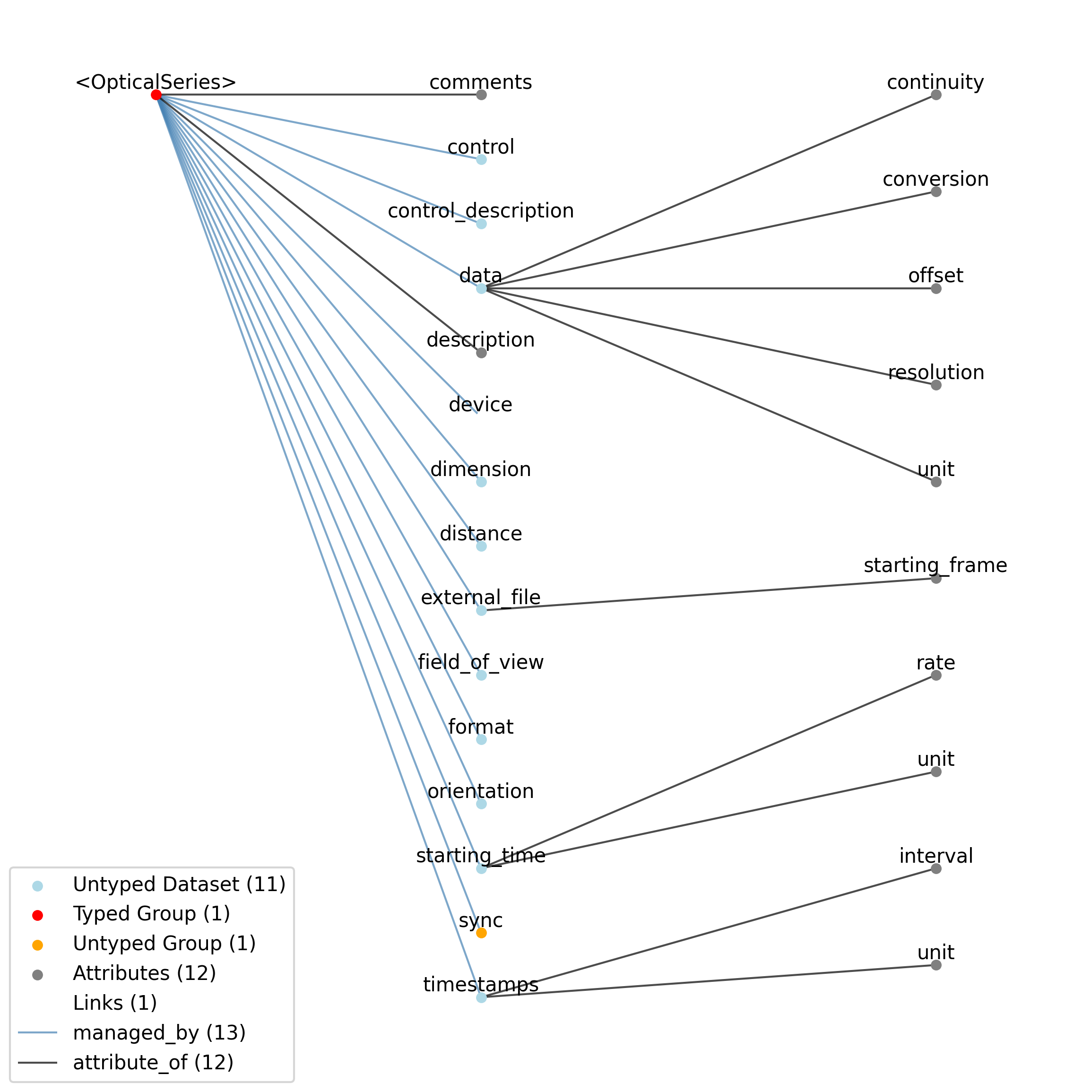
2.5.6. OpticalSeries
Overview: Image data that is presented or recorded. A stimulus template movie will be stored only as an image. When the image is presented as stimulus, additional data is required, such as field of view (e.g., how much of the visual field the image covers, or how large the imaged area of the target is). If the OpticalSeries represents acquired imaging data, orientation is also important.
OpticalSeries extends ImageSeries and includes all elements of ImageSeries with the following additions or changes.
Extends: ImageSeries
Primitive Type: Group
Inherits from: ImageSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.image.yaml
Source Specification: see Section 3.6.6
Id |
Type |
Description |
|---|---|---|
<OpticalSeries> |
Group |
Top level Group for <OpticalSeries>
|
—distance |
Dataset |
Distance from camera/monitor to target/eye.
|
—field_of_view |
Dataset |
Width, height and depth of image, or imaged area, in meters.
|
—data |
Dataset |
Images presented to subject, either grayscale or RGB
|
—orientation |
Dataset |
Description of image relative to some reference frame (e.g., which way is up). Must also specify frame of reference.
|
2.5.7. IndexSeries
Overview: Stores indices that reference images defined in other containers. The primary purpose of the IndexSeries is to allow images stored in an Images container to be referenced in a specific sequence through the ‘indexed_images’ link. This approach avoids duplicating image data when the same image needs to be presented multiple times or when images need to be shown in a different order than they are stored. Since images in an Images container do not have an inherent order, the Images container needs to include an ‘order_of_images’ dataset (of type ImageReferences) whenever it is referenced by an IndexSeries. This dataset establishes the ordered sequence that the indices in IndexSeries refer to. The ‘data’ field stores the index into this ordered sequence, and the ‘timestamps’ array indicates the precise presentation time of each indexed image during an experiment. This can be used for displaying individual images or creating movie segments by referencing a sequence of images with the appropriate timestamps. While IndexSeries can also reference frames from an ImageSeries through the ‘indexed_timeseries’ link, this usage is discouraged and will be deprecated in favor of using Images containers with ‘order_of_images’.
IndexSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.image.yaml
Source Specification: see Section 3.6.7
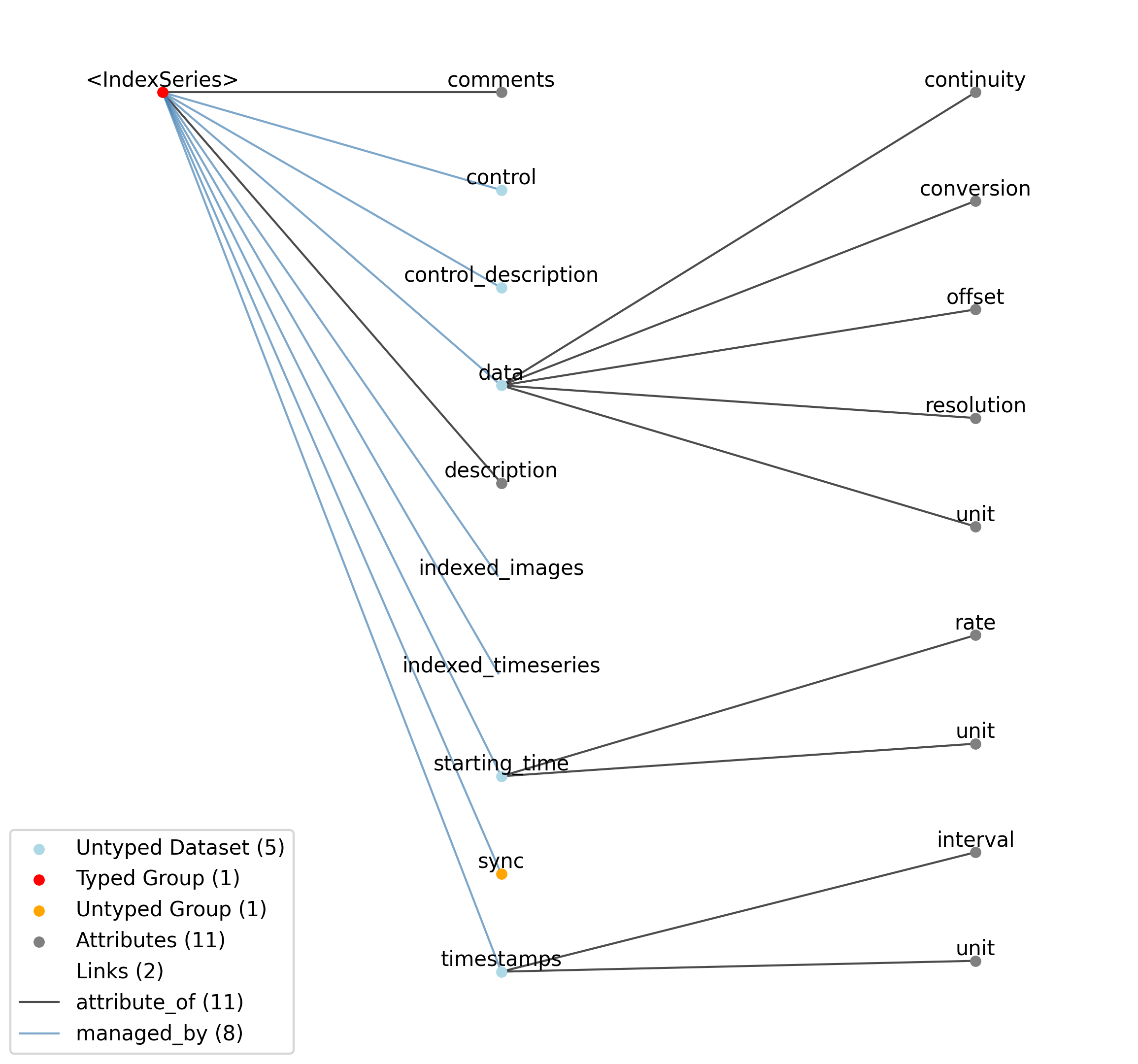
Id |
Type |
Description |
|---|---|---|
<IndexSeries> |
Group |
Top level Group for <IndexSeries>
|
—data |
Dataset |
Index of the image (using zero-indexing) in the linked Images object.
|
——conversion |
Attribute |
This field is unused by IndexSeries.
|
——resolution |
Attribute |
This field is unused by IndexSeries.
|
——offset |
Attribute |
This field is unused by IndexSeries.
|
——unit |
Attribute |
This field is unused by IndexSeries and has the value N/A.
|
—indexed_timeseries |
Link |
Link to ImageSeries object containing images that are indexed. Use of this link is discouraged and will be deprecated. Link to an Images type instead.
|
—indexed_images |
Link |
Link to Images object containing an ordered set of images that are indexed. The Images object must contain an ‘order_of_images’ dataset specifying the order of the images in the Images type.
|
Id |
Type |
Description |
|---|---|---|
<IndexSeries> |
Group |
Top level Group for <IndexSeries>
|
—indexed_timeseries |
Link |
Link to ImageSeries object containing images that are indexed. Use of this link is discouraged and will be deprecated. Link to an Images type instead.
|
—indexed_images |
Link |
Link to Images object containing an ordered set of images that are indexed. The Images object must contain an ‘order_of_images’ dataset specifying the order of the images in the Images type.
|
2.6. NWB file
Main NWB file specification.
2.6.1. ScratchData
Overview: Any one-off datasets
ScratchData extends NWBData and includes all elements of NWBData with the following additions or changes.
Extends: NWBData
Primitive Type: Dataset
Source filename: nwb.file.yaml
Source Specification: see Section 3.7.1
Id |
Type |
Description |
|---|---|---|
<ScratchData> |
Dataset |
Top level Dataset for <ScratchData>
|
—notes |
Attribute |
Any notes the user has about the dataset being stored
|
2.6.2. NWBFile
Overview: An NWB file storing cellular-based neurophysiology data from a single experimental session.
NWBFile extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Name: root
Inherits from: NWBContainer, Container
Source filename: nwb.file.yaml
Source Specification: see Section 3.7.2
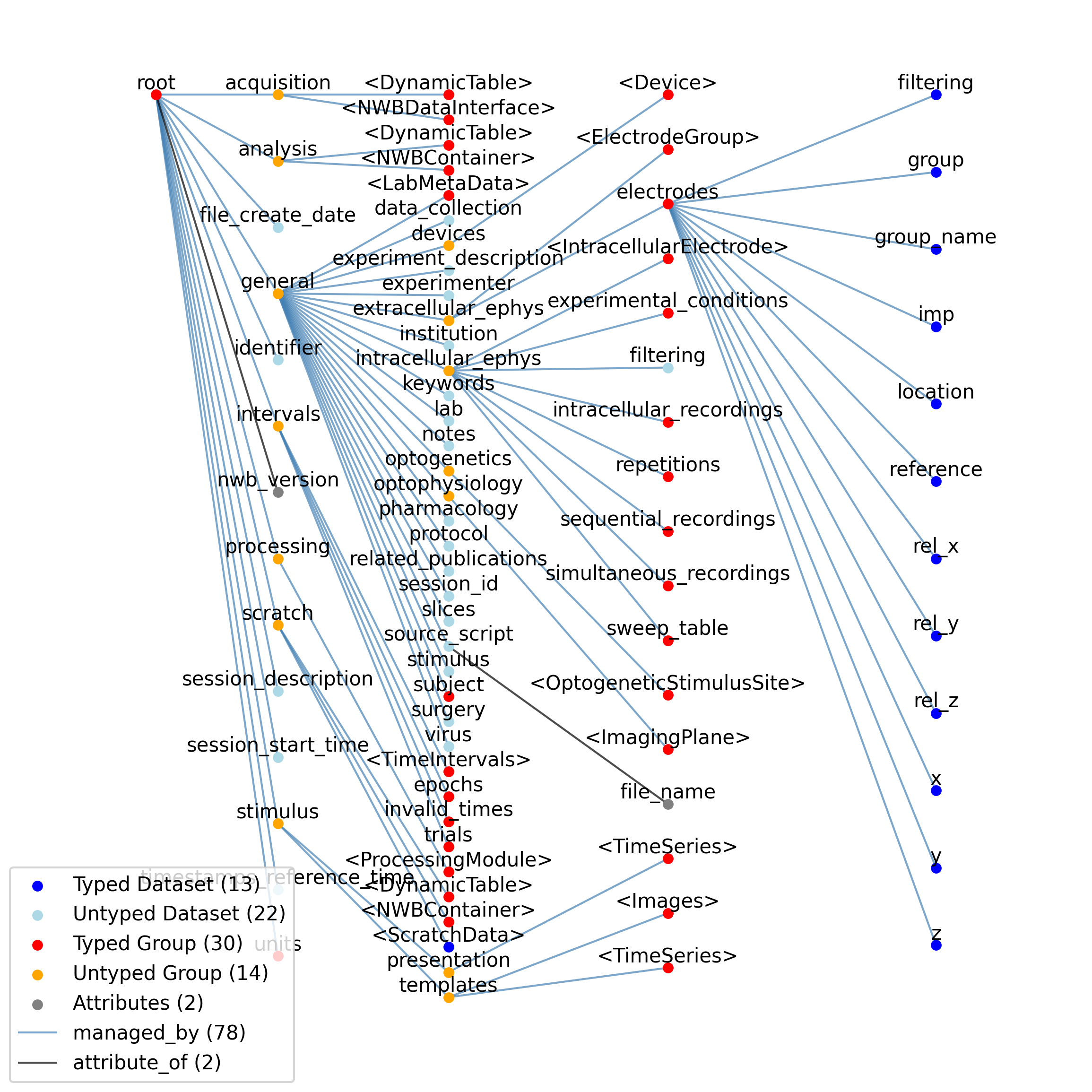
Id |
Type |
Description |
|---|---|---|
root |
Group |
Top level Group for root
|
—nwb_version |
Attribute |
File version string. Use semantic versioning, e.g., 1.2.1. This will be the name of the format with trailing major, minor and patch numbers.
|
—file_create_date |
Dataset |
A record of the date the file was created and of subsequent modifications. The date is stored in UTC with local timezone offset as ISO 8601 extended formatted strings: 2018-09-28T14:43:54.123+02:00. Dates stored in UTC end in “Z” with no timezone offset. Date accuracy is up to milliseconds. The file can be created after the experiment was run, so this may differ from the experiment start time. Each modification to the nwb file adds a new entry to the array.
|
—identifier |
Dataset |
A unique text identifier for the file. For example, concatenated lab name, file creation date/time and experimentalist, or a hash of these and/or other values. The goal is that the string should be unique to all other files.
|
—session_description |
Dataset |
A description of the experimental session and data in the file.
|
—session_start_time |
Dataset |
Date and time of the experiment/session start. The date is stored in UTC with local timezone offset as ISO 8601 extended formatted string: 2018-09-28T14:43:54.123+02:00. Dates stored in UTC end in “Z” with no timezone offset. Date accuracy is up to milliseconds.
|
—timestamps_reference_time |
Dataset |
Date and time corresponding to time zero of all timestamps. The date is stored in UTC with local timezone offset as ISO 8601 extended formatted string: 2018-09-28T14:43:54.123+02:00. Dates stored in UTC end in “Z” with no timezone offset. Date accuracy is up to milliseconds. All times stored in the file use this time as reference (i.e., time zero).
|
Id |
Type |
Description |
|---|---|---|
root |
Group |
Top level Group for root
|
—acquisition |
Group |
Data streams recorded from the system, including ephys, ophys, tracking, etc. This group should be read-only after the experiment is completed and timestamps are corrected to a common timebase. The data stored here may be links to raw data stored in external NWB files. This will allow keeping bulky raw data out of the file while preserving the option of keeping some/all in the file. Acquired data includes tracking and experimental data streams (i.e., everything measured from the system). If bulky data is stored in the /acquisition group, the data can exist in a separate NWB file that is linked to by the file being used for processing and analysis.
|
—analysis |
Group |
Lab-specific and custom scientific analysis of data. There is no defined format for the content of this group - the format is up to the individual user/lab. To facilitate sharing analysis data between labs, the contents here should be stored in standard types (e.g., neurodata_types) and appropriately documented. The file can store lab-specific and custom data analysis without restriction on its form or schema, reducing data formatting restrictions on end users. Such data should be placed in the analysis group. The analysis data should be documented so that it could be shared with other labs.
|
—scratch |
Group |
A place to store one-off analysis results. Data placed here is not intended for sharing. By placing data here, users acknowledge that there is no guarantee that their data meets any standard.
|
—processing |
Group |
The home for ProcessingModules. These modules perform intermediate analysis of data that is necessary to perform before scientific analysis. Examples include spike clustering, extracting position from tracking data, stitching together image slices. ProcessingModules can be large and express many data sets from relatively complex analysis (e.g., spike detection and clustering) or small, representing extraction of position information from tracking video, or even binary lick/no-lick decisions. Common software tools (e.g., klustakwik, MClust) are expected to read/write data here. ‘Processing’ refers to intermediate analysis of the acquired data to make it more amenable to scientific analysis.
|
—stimulus |
Group |
Data pushed into the system (e.g., video stimulus, sound, voltage, etc.) and secondary representations of that data (e.g., measurements of something used as a stimulus). This group should be made read-only after the experiment is complete and timestamps are corrected to a common timebase. Stores both presented stimuli and stimulus templates, the latter in case the same stimulus is presented multiple times, or is pulled from an external stimulus library. Stimuli are here defined as any signal that is pushed into the system as part of the experiment (e.g., sound, video, voltage, etc.). Many different experiments can use the same stimuli, and stimuli can be reused during an experiment. The stimulus group is organized so that one version of template stimuli can be stored and these can be used multiple times. These templates can exist in the present file or can be linked to a remote library file.
|
—general |
Group |
Experimental metadata, including protocol, notes and description of hardware device(s). The metadata stored in this section should be used to describe the experiment. Metadata necessary for interpreting the data is stored with the data. General experimental metadata, including animal strain, experimental protocols, experimenter, devices, etc. are stored under ‘general’. Core metadata (e.g., that required to interpret data fields) is stored with the data itself, and implicitly defined by the file specification (e.g., time is in seconds). The strategy used here for storing non-core metadata is to use free-form text fields, such as would appear in sentences or paragraphs from a Methods section. Metadata fields are text to enable them to be more general, for example to represent ranges instead of numerical values. Machine-readable metadata is stored as attributes to these free-form datasets. All entries in the below table are to be included when data is present. Unused groups (e.g., intracellular_ephys in an optophysiology experiment) should not be created unless there is data to store within them.
|
—intervals |
Group |
Experimental intervals, whether these are logically distinct sub-experiments having a particular scientific goal, trials (see trials subgroup) during an experiment, or epochs (see epochs subgroup) derived from analysis of data.
|
—events |
Group |
Experimental event tables for the session, stored as EventsTable instances. This is the recommended location for all event tables in the file, regardless of whether the events were emitted directly by the acquisition system (TTL edges, hardware event channels), derived by user processing (filtering, detection algorithms), or added as post-hoc annotations. The provenance of each table can be recorded in the source_description attribute of the EventsTable and described in more detail in its description. Each EventsTable should hold events of a single type (i.e., events sharing the same per-event metadata columns). For periods with required start and stop times, see /intervals/. For continuous acquired signals or stimulus templates from which events may have been derived, see /acquisition/ or /stimulus/.
|
—units |
Group |
Data about sorted spike units.
|
2.6.2.1. Groups: /acquisition
Data streams recorded from the system, including ephys, ophys, tracking, etc. This group should be read-only after the experiment is completed and timestamps are corrected to a common timebase. The data stored here may be links to raw data stored in external NWB files. This will allow keeping bulky raw data out of the file while preserving the option of keeping some/all in the file. Acquired data includes tracking and experimental data streams (i.e., everything measured from the system). If bulky data is stored in the /acquisition group, the data can exist in a separate NWB file that is linked to by the file being used for processing and analysis.
Name: acquisition
Id |
Type |
Description |
|---|---|---|
acquisition |
Group |
Top level Group for acquisition
|
Group |
Acquired, raw data.
|
|
—<DynamicTable> |
Group |
Tabular data that is relevant to acquisition
|
2.6.2.2. Groups: /acquisition/<NWBDataInterface>
Acquired, raw data.
Extends: NWBDataInterface
Quantity: 0 or more
2.6.2.3. Groups: /acquisition/<DynamicTable>
Tabular data that is relevant to acquisition
Extends: DynamicTable
Quantity: 0 or more
2.6.2.4. Groups: /analysis
Lab-specific and custom scientific analysis of data. There is no defined format for the content of this group - the format is up to the individual user/lab. To facilitate sharing analysis data between labs, the contents here should be stored in standard types (e.g., neurodata_types) and appropriately documented. The file can store lab-specific and custom data analysis without restriction on its form or schema, reducing data formatting restrictions on end users. Such data should be placed in the analysis group. The analysis data should be documented so that it could be shared with other labs.
Name: analysis
Id |
Type |
Description |
|---|---|---|
analysis |
Group |
Top level Group for analysis
|
—<NWBContainer> |
Group |
Custom analysis results.
|
—<DynamicTable> |
Group |
Tabular data that is relevant to data stored in analysis
|
2.6.2.5. Groups: /analysis/<NWBContainer>
Custom analysis results.
Extends: NWBContainer
Quantity: 0 or more
2.6.2.6. Groups: /analysis/<DynamicTable>
Tabular data that is relevant to data stored in analysis
Extends: DynamicTable
Quantity: 0 or more
2.6.2.7. Groups: /scratch
A place to store one-off analysis results. Data placed here is not intended for sharing. By placing data here, users acknowledge that there is no guarantee that their data meets any standard.
Quantity: 0 or 1
Name: scratch
Id |
Type |
Description |
|---|---|---|
scratch |
Group |
Top level Group for scratch
|
—<ScratchData> |
Dataset |
Any one-off datasets
|
Id |
Type |
Description |
|---|---|---|
scratch |
Group |
Top level Group for scratch
|
—<NWBContainer> |
Group |
Any one-off containers
|
—<DynamicTable> |
Group |
Any one-off tables
|
2.6.2.8. Groups: /scratch/<NWBContainer>
Any one-off containers
Extends: NWBContainer
Quantity: 0 or more
2.6.2.9. Groups: /scratch/<DynamicTable>
Any one-off tables
Extends: DynamicTable
Quantity: 0 or more
2.6.2.10. Groups: /processing
The home for ProcessingModules. These modules perform intermediate analysis of data that is necessary to perform before scientific analysis. Examples include spike clustering, extracting position from tracking data, stitching together image slices. ProcessingModules can be large and express many data sets from relatively complex analysis (e.g., spike detection and clustering) or small, representing extraction of position information from tracking video, or even binary lick/no-lick decisions. Common software tools (e.g., klustakwik, MClust) are expected to read/write data here. ‘Processing’ refers to intermediate analysis of the acquired data to make it more amenable to scientific analysis.
Name: processing
Id |
Type |
Description |
|---|---|---|
processing |
Group |
Top level Group for processing
|
Group |
Intermediate analysis of acquired data.
|
2.6.2.11. Groups: /processing/<ProcessingModule>
Intermediate analysis of acquired data.
Extends: ProcessingModule
Quantity: 0 or more
2.6.2.12. Groups: /stimulus
Data pushed into the system (e.g., video stimulus, sound, voltage, etc.) and secondary representations of that data (e.g., measurements of something used as a stimulus). This group should be made read-only after the experiment is complete and timestamps are corrected to a common timebase. Stores both presented stimuli and stimulus templates, the latter in case the same stimulus is presented multiple times, or is pulled from an external stimulus library. Stimuli are here defined as any signal that is pushed into the system as part of the experiment (e.g., sound, video, voltage, etc.). Many different experiments can use the same stimuli, and stimuli can be reused during an experiment. The stimulus group is organized so that one version of template stimuli can be stored and these can be used multiple times. These templates can exist in the present file or can be linked to a remote library file.
Name: stimulus
Id |
Type |
Description |
|---|---|---|
stimulus |
Group |
Top level Group for stimulus
|
—presentation |
Group |
Stimuli presented during the experiment.
|
—templates |
Group |
Template stimuli. Timestamps in templates are based on stimulus design and are relative to the beginning of the stimulus. When templates are used, the stimulus instances must convert presentation times to the experiment’s time reference frame.
|
2.6.2.13. Groups: /stimulus/presentation
Stimuli presented during the experiment.
Name: presentation
Id |
Type |
Description |
|---|---|---|
presentation |
Group |
Top level Group for presentation
|
—<TimeSeries> |
Group |
TimeSeries objects containing data of presented stimuli.
|
Group |
Generic NWB data interfaces, usually from an extension, containing data of presented stimuli.
|
|
—<DynamicTable> |
Group |
DynamicTable objects containing data of presented stimuli.
|
2.6.2.14. Groups: /stimulus/presentation/<TimeSeries>
TimeSeries objects containing data of presented stimuli.
Extends: TimeSeries
Quantity: 0 or more
2.6.2.15. Groups: /stimulus/presentation/<NWBDataInterface>
Generic NWB data interfaces, usually from an extension, containing data of presented stimuli.
Extends: NWBDataInterface
Quantity: 0 or more
2.6.2.16. Groups: /stimulus/presentation/<DynamicTable>
DynamicTable objects containing data of presented stimuli.
Extends: DynamicTable
Quantity: 0 or more
2.6.2.17. Groups: /stimulus/templates
Template stimuli. Timestamps in templates are based on stimulus design and are relative to the beginning of the stimulus. When templates are used, the stimulus instances must convert presentation times to the experiment’s time reference frame.
Name: templates
Id |
Type |
Description |
|---|---|---|
templates |
Group |
Top level Group for templates
|
—<TimeSeries> |
Group |
TimeSeries objects containing template data of presented stimuli.
|
—<Images> |
Group |
Images objects containing images of presented stimuli.
|
2.6.2.18. Groups: /stimulus/templates/<TimeSeries>
TimeSeries objects containing template data of presented stimuli.
Extends: TimeSeries
Quantity: 0 or more
2.6.2.19. Groups: /stimulus/templates/<Images>
Images objects containing images of presented stimuli.
Extends: Images
Quantity: 0 or more
2.6.2.20. Groups: /general
Experimental metadata, including protocol, notes and description of hardware device(s). The metadata stored in this section should be used to describe the experiment. Metadata necessary for interpreting the data is stored with the data. General experimental metadata, including animal strain, experimental protocols, experimenter, devices, etc. are stored under ‘general’. Core metadata (e.g., that required to interpret data fields) is stored with the data itself, and implicitly defined by the file specification (e.g., time is in seconds). The strategy used here for storing non-core metadata is to use free-form text fields, such as would appear in sentences or paragraphs from a Methods section. Metadata fields are text to enable them to be more general, for example to represent ranges instead of numerical values. Machine-readable metadata is stored as attributes to these free-form datasets. All entries in the below table are to be included when data is present. Unused groups (e.g., intracellular_ephys in an optophysiology experiment) should not be created unless there is data to store within them.
Name: general
Id |
Type |
Description |
|---|---|---|
general |
Group |
Top level Group for general
|
—data_collection |
Dataset |
Notes about data collection and analysis.
|
—experiment_description |
Dataset |
General description of the experiment.
|
—experimenter |
Dataset |
Name of person(s) who performed the experiment. Can also specify roles of different people involved.
|
—institution |
Dataset |
Institution(s) where experiment was performed.
|
—keywords |
Dataset |
Terms to search over.
|
—lab |
Dataset |
Laboratory where experiment was performed.
|
—notes |
Dataset |
Notes about the experiment.
|
—pharmacology |
Dataset |
Description of drugs used, including how and when they were administered. Anesthesia(s), painkiller(s), etc., plus dosage, concentration, etc.
|
—protocol |
Dataset |
Experimental protocol, if applicable. e.g., include IACUC protocol number.
|
—related_publications |
Dataset |
Publication information. PMID, DOI, URL, etc.
|
—session_id |
Dataset |
Lab-specific ID for the session.
|
—slices |
Dataset |
Description of slices, including information about preparation thickness, orientation, temperature, and bath solution.
|
—source_script |
Dataset |
Script file or link to public source code used to create this NWB file.
|
——file_name |
Attribute |
Name of script file.
|
—was_generated_by |
Dataset |
Name and version of software package(s) used to generate data contained in this NWB file. For each software package or library, include the name of the software as the first value and the version as the second value.
|
—stimulus |
Dataset |
Notes about stimuli, such as how and where they were presented.
|
—surgery |
Dataset |
Narrative description about surgery/surgeries, including date(s) and who performed surgery.
|
—virus |
Dataset |
Information about virus(es) used in experiments, including virus ID, source, date made, injection location, volume, etc.
|
Id |
Type |
Description |
|---|---|---|
general |
Group |
Top level Group for general
|
—external_resources |
Group |
This is the HERD structure for this specific NWBFile, storing the mapped external resources.
|
—<LabMetaData> |
Group |
Place-holder that can be extended so that lab-specific meta-data can be placed in /general.
|
—devices |
Group |
Description of hardware devices used during experiment, e.g., monitors, ADC boards, microscopes, etc.
|
—subject |
Group |
Information about the animal or person from which the data was measured.
|
—extracellular_ephys |
Group |
Metadata related to extracellular electrophysiology.
|
—intracellular_ephys |
Group |
Metadata related to intracellular electrophysiology.
|
—optogenetics |
Group |
Metadata describing optogenetic stimulation.
|
—optophysiology |
Group |
Metadata related to optophysiology.
|
2.6.2.21. Groups: /general/external_resources
This is the HERD structure for this specific NWBFile, storing the mapped external resources.
Extends: HERD
Quantity: 0 or 1
Name: external_resources
2.6.2.22. Groups: /general/<LabMetaData>
Place-holder that can be extended so that lab-specific meta-data can be placed in /general.
Extends: LabMetaData
Quantity: 0 or more
2.6.2.23. Groups: /general/devices
Description of hardware devices used during experiment, e.g., monitors, ADC boards, microscopes, etc.
Quantity: 0 or 1
Name: devices
Id |
Type |
Description |
|---|---|---|
devices |
Group |
Top level Group for devices
|
—<Device> |
Group |
Data acquisition devices.
|
—models |
Group |
Collection of data acquisition device models.
|
2.6.2.24. Groups: /general/devices/<Device>
Data acquisition devices.
Extends: Device
Quantity: 0 or more
2.6.2.25. Groups: /general/devices/models
Collection of data acquisition device models.
Quantity: 0 or 1
Name: models
Id |
Type |
Description |
|---|---|---|
models |
Group |
Top level Group for models
|
—<DeviceModel> |
Group |
Data acquisition device models.
|
2.6.2.26. Groups: /general/devices/models/<DeviceModel>
Data acquisition device models.
Extends: DeviceModel
Quantity: 0 or more
2.6.2.27. Groups: /general/subject
Information about the animal or person from which the data was measured.
Extends: Subject
Quantity: 0 or 1
Name: subject
2.6.2.28. Groups: /general/extracellular_ephys
Metadata related to extracellular electrophysiology.
Quantity: 0 or 1
Name: extracellular_ephys
Id |
Type |
Description |
|---|---|---|
extracellular_ephys |
Group |
Top level Group for extracellular_ephys
|
Group |
Physical group of electrodes.
|
|
—electrodes |
Group |
A table of all electrodes (i.e., channels) used for recording. Changed in NWB 2.9.0 to use the newly added ElectrodesTable neurodata type instead of a DynamicTable with added columns.
|
2.6.2.29. Groups: /general/extracellular_ephys/<ElectrodeGroup>
Physical group of electrodes.
Extends: ElectrodeGroup
Quantity: 0 or more
2.6.2.30. Groups: /general/extracellular_ephys/electrodes
A table of all electrodes (i.e., channels) used for recording. Changed in NWB 2.9.0 to use the newly added ElectrodesTable neurodata type instead of a DynamicTable with added columns.
Extends: ElectrodesTable
Quantity: 0 or 1
Name: electrodes
2.6.2.31. Groups: /general/intracellular_ephys
Metadata related to intracellular electrophysiology.
Quantity: 0 or 1
Name: intracellular_ephys
Id |
Type |
Description |
|---|---|---|
intracellular_ephys |
Group |
Top level Group for intracellular_ephys
|
—filtering |
Dataset |
[DEPRECATED] Use IntracellularElectrode.filtering instead. Description of filtering used. Includes filtering type and parameters, frequency fall-off, etc. If this changes between TimeSeries, filter description should be stored as a text attribute for each TimeSeries.
|
Id |
Type |
Description |
|---|---|---|
intracellular_ephys |
Group |
Top level Group for intracellular_ephys
|
Group |
An intracellular electrode.
|
|
—sweep_table |
Group |
[DEPRECATED] Table used to group different PatchClampSeries. SweepTable is being replaced by IntracellularRecordingsTable and SimultaneousRecordingsTable tables. Additional SequentialRecordingsTable, RepetitionsTable and ExperimentalConditions tables provide enhanced support for experiment metadata.
|
—intracellular_recordings |
Group |
A table to group together a stimulus and response from a single electrode and a single simultaneous recording. Each row in the table represents a single recording consisting typically of a stimulus and a corresponding response. In some cases, however, only a stimulus or a response are recorded as part of an experiment. In this case, both the stimulus and response will point to the same TimeSeries while the idx_start and count of the invalid column will be set to -1, thus, indicating that no values have been recorded for the stimulus or response, respectively. Note, a recording MUST contain at least a stimulus or a response. Typically the stimulus and response are PatchClampSeries. However, the use of AD/DA channels that are not associated to an electrode is also common in intracellular electrophysiology, in which case other TimeSeries may be used.
|
—simultaneous_recordings |
Group |
A table for grouping different intracellular recordings from the IntracellularRecordingsTable table together that were recorded simultaneously from different electrodes
|
—sequential_recordings |
Group |
A table for grouping different sequential recordings from the SimultaneousRecordingsTable table together. This is typically used to group together sequential recordings where a sequence of stimuli of the same type with varying parameters have been presented in a sequence.
|
—repetitions |
Group |
A table for grouping different sequential intracellular recordings together. With each SequentialRecording typically representing a particular type of stimulus, the RepetitionsTable table is typically used to group sets of stimuli applied in sequence.
|
—experimental_conditions |
Group |
A table for grouping different intracellular recording repetitions together that belong to the same experimental conditions.
|
2.6.2.32. Groups: /general/intracellular_ephys/<IntracellularElectrode>
An intracellular electrode.
Extends: IntracellularElectrode
Quantity: 0 or more
2.6.2.33. Groups: /general/intracellular_ephys/sweep_table
[DEPRECATED] Table used to group different PatchClampSeries. SweepTable is being replaced by IntracellularRecordingsTable and SimultaneousRecordingsTable tables. Additional SequentialRecordingsTable, RepetitionsTable and ExperimentalConditions tables provide enhanced support for experiment metadata.
Extends: SweepTable
Quantity: 0 or 1
Name: sweep_table
2.6.2.34. Groups: /general/intracellular_ephys/intracellular_recordings
A table to group together a stimulus and response from a single electrode and a single simultaneous recording. Each row in the table represents a single recording consisting typically of a stimulus and a corresponding response. In some cases, however, only a stimulus or a response are recorded as part of an experiment. In this case, both the stimulus and response will point to the same TimeSeries while the idx_start and count of the invalid column will be set to -1, thus, indicating that no values have been recorded for the stimulus or response, respectively. Note, a recording MUST contain at least a stimulus or a response. Typically the stimulus and response are PatchClampSeries. However, the use of AD/DA channels that are not associated to an electrode is also common in intracellular electrophysiology, in which case other TimeSeries may be used.
Extends: IntracellularRecordingsTable
Quantity: 0 or 1
Name: intracellular_recordings
2.6.2.35. Groups: /general/intracellular_ephys/simultaneous_recordings
A table for grouping different intracellular recordings from the IntracellularRecordingsTable table together that were recorded simultaneously from different electrodes
Extends: SimultaneousRecordingsTable
Quantity: 0 or 1
Name: simultaneous_recordings
2.6.2.36. Groups: /general/intracellular_ephys/sequential_recordings
A table for grouping different sequential recordings from the SimultaneousRecordingsTable table together. This is typically used to group together sequential recordings where a sequence of stimuli of the same type with varying parameters have been presented in a sequence.
Extends: SequentialRecordingsTable
Quantity: 0 or 1
Name: sequential_recordings
2.6.2.37. Groups: /general/intracellular_ephys/repetitions
A table for grouping different sequential intracellular recordings together. With each SequentialRecording typically representing a particular type of stimulus, the RepetitionsTable table is typically used to group sets of stimuli applied in sequence.
Extends: RepetitionsTable
Quantity: 0 or 1
Name: repetitions
2.6.2.38. Groups: /general/intracellular_ephys/experimental_conditions
A table for grouping different intracellular recording repetitions together that belong to the same experimental conditions.
Extends: ExperimentalConditionsTable
Quantity: 0 or 1
Name: experimental_conditions
2.6.2.39. Groups: /general/optogenetics
Metadata describing optogenetic stimulation.
Quantity: 0 or 1
Name: optogenetics
Id |
Type |
Description |
|---|---|---|
optogenetics |
Group |
Top level Group for optogenetics
|
Group |
An optogenetic stimulation site.
|
2.6.2.40. Groups: /general/optogenetics/<OptogeneticStimulusSite>
An optogenetic stimulation site.
Extends: OptogeneticStimulusSite
Quantity: 0 or more
2.6.2.41. Groups: /general/optophysiology
Metadata related to optophysiology.
Quantity: 0 or 1
Name: optophysiology
Id |
Type |
Description |
|---|---|---|
optophysiology |
Group |
Top level Group for optophysiology
|
—<ImagingPlane> |
Group |
An imaging plane.
|
2.6.2.42. Groups: /general/optophysiology/<ImagingPlane>
An imaging plane.
Extends: ImagingPlane
Quantity: 0 or more
2.6.2.43. Groups: /intervals
Experimental intervals, whether these are logically distinct sub-experiments having a particular scientific goal, trials (see trials subgroup) during an experiment, or epochs (see epochs subgroup) derived from analysis of data.
Quantity: 0 or 1
Name: intervals
Id |
Type |
Description |
|---|---|---|
intervals |
Group |
Top level Group for intervals
|
—epochs |
Group |
Time intervals marking coarse-grained experimental phases or subdivisions of a recording session, such as baseline, task, rest, or sleep stages.
|
—trials |
Group |
Time intervals corresponding to repeated experimental units with consistent structure, such as individual stimulus-response-reward cycles.
|
—invalid_times |
Group |
Time intervals that should be removed from analysis.
|
Group |
Optional additional table(s) for describing other experimental time intervals.
|
2.6.2.44. Groups: /intervals/epochs
Time intervals marking coarse-grained experimental phases or subdivisions of a recording session, such as baseline, task, rest, or sleep stages.
Extends: TimeIntervals
Quantity: 0 or 1
Name: epochs
2.6.2.45. Groups: /intervals/trials
Time intervals corresponding to repeated experimental units with consistent structure, such as individual stimulus-response-reward cycles.
Extends: TimeIntervals
Quantity: 0 or 1
Name: trials
2.6.2.46. Groups: /intervals/invalid_times
Time intervals that should be removed from analysis.
Extends: TimeIntervals
Quantity: 0 or 1
Name: invalid_times
2.6.2.47. Groups: /intervals/<TimeIntervals>
Optional additional table(s) for describing other experimental time intervals.
Extends: TimeIntervals
Quantity: 0 or more
2.6.2.48. Groups: /events
Experimental event tables for the session, stored as EventsTable instances. This is the recommended location for all event tables in the file, regardless of whether the events were emitted directly by the acquisition system (TTL edges, hardware event channels), derived by user processing (filtering, detection algorithms), or added as post-hoc annotations. The provenance of each table can be recorded in the source_description attribute of the EventsTable and described in more detail in its description. Each EventsTable should hold events of a single type (i.e., events sharing the same per-event metadata columns). For periods with required start and stop times, see /intervals/. For continuous acquired signals or stimulus templates from which events may have been derived, see /acquisition/ or /stimulus/.
Quantity: 0 or 1
Name: events
Id |
Type |
Description |
|---|---|---|
events |
Group |
Top level Group for events
|
—<EventsTable> |
Group |
An EventsTable holding a collection of event times of a particular type (e.g., licks, rewards, stimulus presentations) along with their per-event metadata.
|
2.6.2.49. Groups: /events/<EventsTable>
An EventsTable holding a collection of event times of a particular type (e.g., licks, rewards, stimulus presentations) along with their per-event metadata.
Extends: EventsTable
Quantity: 0 or more
2.6.2.50. Groups: /units
Data about sorted spike units.
Extends: Units
Quantity: 0 or 1
Name: units
2.6.3. LabMetaData
Overview: Lab-specific meta-data.
LabMetaData extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.file.yaml
Source Specification: see Section 3.7.3
2.6.4. Subject
Overview: Information about the animal or person from which the data was measured.
Subject extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.file.yaml
Source Specification: see Section 3.7.4
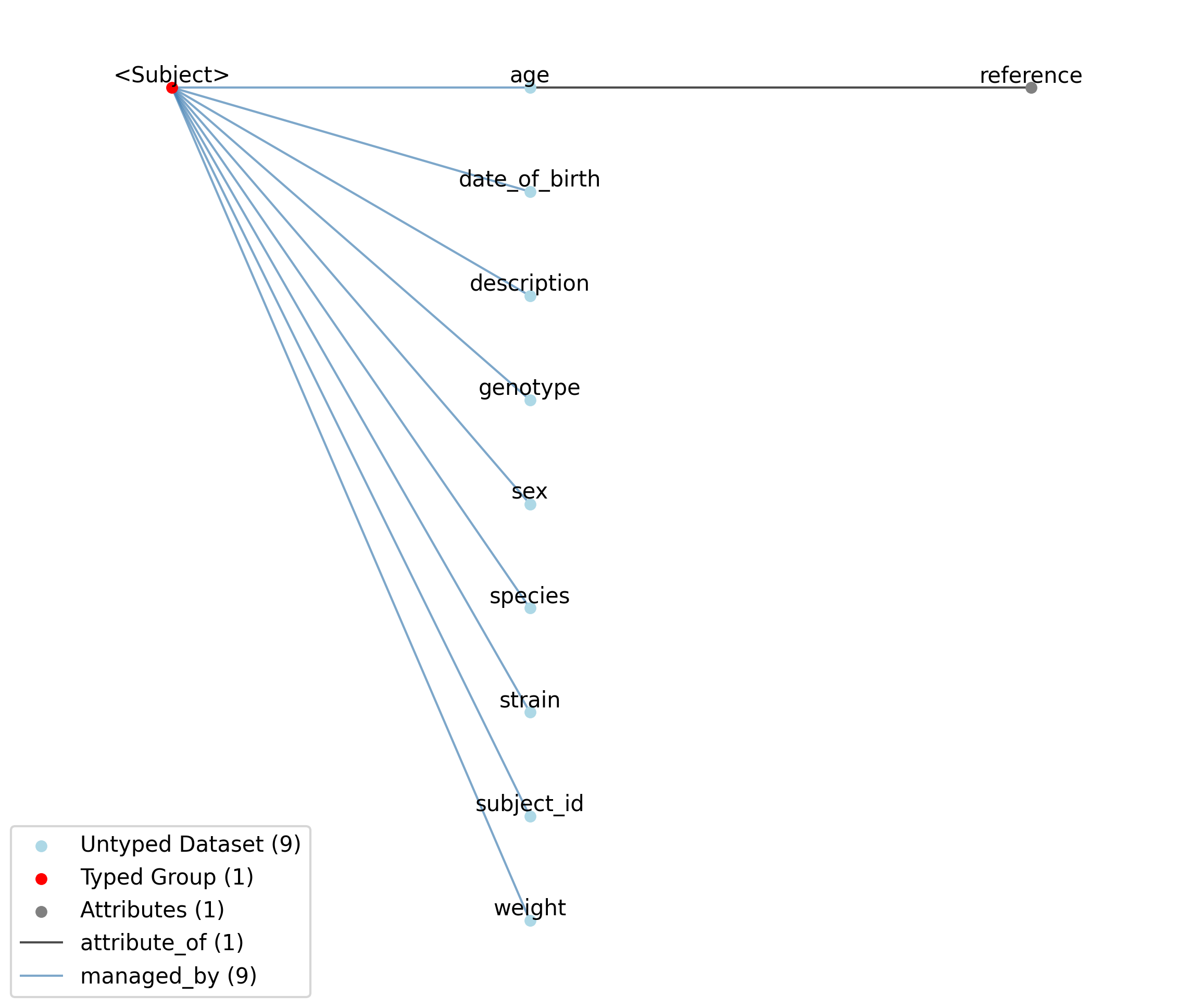
Id |
Type |
Description |
|---|---|---|
<Subject> |
Group |
Top level Group for <Subject>
|
—age |
Dataset |
Age of subject. Can be supplied instead of ‘date_of_birth’. The ISO 8601 Duration format is recommended, e.g., ‘P90D’ for 90 days old. If the precise age is unknown, an age range can be given by ‘[lower bound]/[upper bound]’ e.g. ‘P10D/P20D’ would mean that the age is in between 10 and 20 days. If only the lower bound is known, then including only the slash after that lower bound can be used to indicate a missing bound. For instance, ‘P90Y/’ would indicate that the age is 90 years or older.
|
——reference |
Attribute |
Age is with reference to this event. Can be ‘birth’ or ‘gestational’. If reference is omitted, ‘birth’ is implied.
|
—date_of_birth |
Dataset |
Date of birth of subject. Can be supplied instead of ‘age’.
|
—description |
Dataset |
Description of subject and where subject came from (e.g., breeder, if animal).
|
—genotype |
Dataset |
Genetic strain. If absent, assume Wild Type (WT).
|
—sex |
Dataset |
Biological sex of subject.
|
—species |
Dataset |
Species of subject.
|
—strain |
Dataset |
Strain of subject.
|
—subject_id |
Dataset |
ID of animal/person used/participating in experiment (lab convention).
|
—weight |
Dataset |
Weight at time of experiment, at time of surgery and at other important times.
|
2.7. Miscellaneous neurodata_types.
Miscellaneous types.
2.7.1. AbstractFeatureSeries
Overview: Abstract features, such as quantitative descriptions of sensory stimuli. The TimeSeries::data field is a 2-D array, storing those features (e.g., for a visual grating stimulus this might be orientation, spatial frequency and contrast). Null stimuli (e.g., uniform gray) can be marked as being an independent feature (e.g., 1.0 for gray, 0.0 for actual stimulus) or by storing NaNs for feature values, or through use of the TimeSeries::control fields. A set of features is considered to persist until the next set of features is defined. The final set of features stored should be the null set. This is useful when storing the raw stimulus is impractical.
AbstractFeatureSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.misc.yaml
Source Specification: see Section 3.8.1
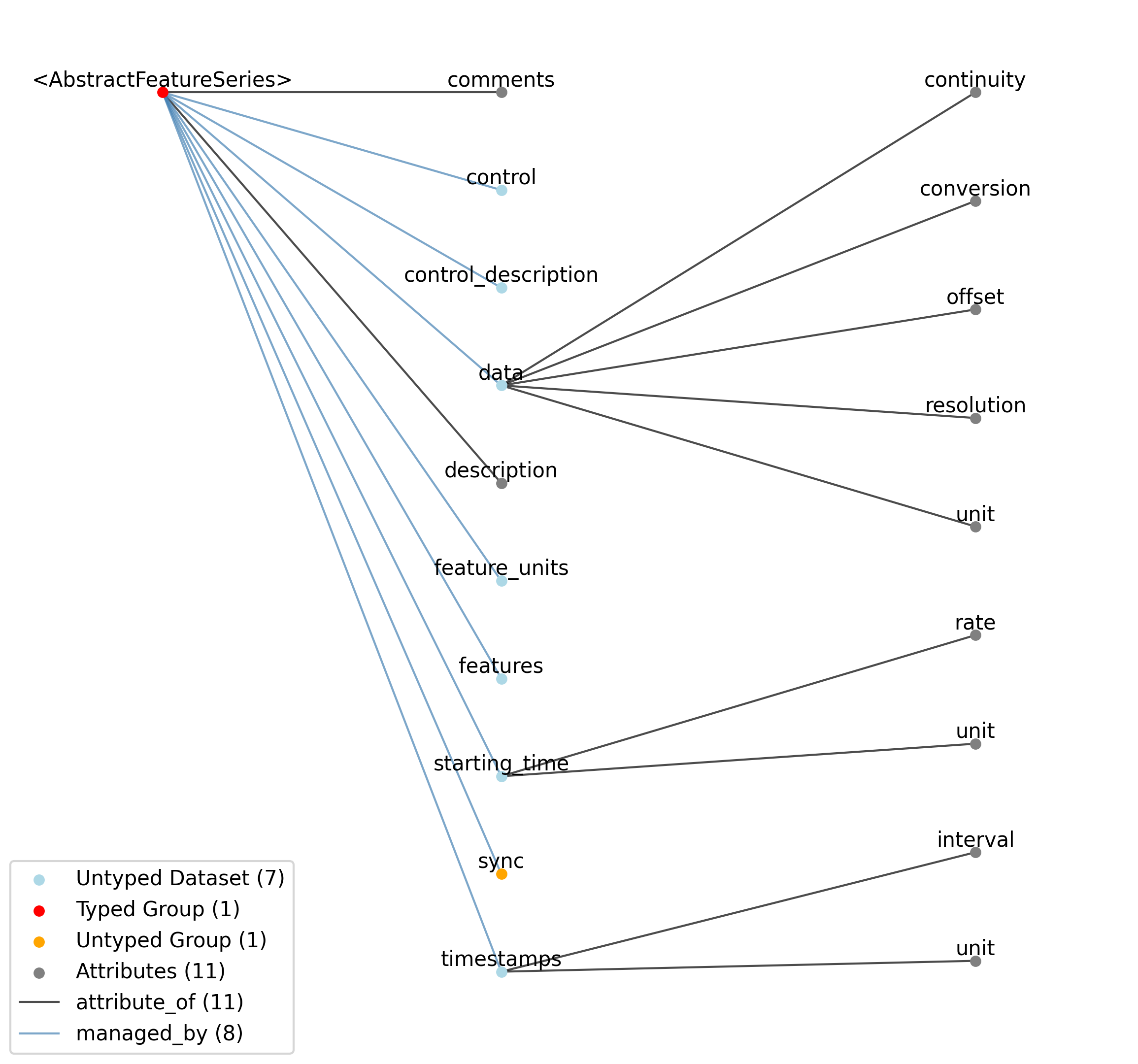
Id |
Type |
Description |
|---|---|---|
<AbstractFeatureSeries> |
Group |
Top level Group for <AbstractFeatureSeries>
|
—data |
Dataset |
Values of each feature at each time.
|
——unit |
Attribute |
Since there can be different units for different features, store the units in ‘feature_units’. The default value for this attribute is “see ‘feature_units’”.
|
—feature_units |
Dataset |
Units of each feature.
|
—features |
Dataset |
Description of the features represented in TimeSeries::data.
|
2.7.2. AnnotationSeries
Overview: DEPRECATED. Use an EventsTable instead, placed in the top-level /events group of the NWBFile. The timestamps field maps to the timestamp column, and the data field (annotation strings) maps to the annotation column on EventsTable. Use the source_description attribute on the EventsTable to record where the annotations came from (e.g., “Manual video review”). Original definition: Stores user annotations made during an experiment. The data[] field stores a text array, and timestamps are stored for each annotation (i.e., interval=1). This is largely an alias to a standard TimeSeries storing a text array but that is identifiable as storing annotations in a machine-readable way.
AnnotationSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.misc.yaml
Source Specification: see Section 3.8.2
Id |
Type |
Description |
|---|---|---|
<AnnotationSeries> |
Group |
Top level Group for <AnnotationSeries>
|
—data |
Dataset |
Annotations made during an experiment.
|
——resolution |
Attribute |
Smallest meaningful difference between values in data. Annotations have no units, so the value is fixed to -1.0.
|
——unit |
Attribute |
Base unit of measurement for working with the data. Annotations have no units, so the value is fixed to ‘n/a’.
|
2.7.3. IntervalSeries
Overview: Stores intervals of data. The timestamps field stores the beginning and end of intervals. The data field stores whether the interval just started (>0 value) or ended (<0 value). Different interval types can be represented in the same series by using multiple key values (e.g., 1 for feature A, 2 for feature B, 3 for feature C, etc.). The field data stores an 8-bit integer. This is largely an alias of a standard TimeSeries but that is identifiable as representing time intervals in a machine-readable way.
IntervalSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.misc.yaml
Source Specification: see Section 3.8.3
Id |
Type |
Description |
|---|---|---|
<IntervalSeries> |
Group |
Top level Group for <IntervalSeries>
|
—data |
Dataset |
Use values >0 if interval started, <0 if interval ended.
|
——resolution |
Attribute |
Smallest meaningful difference between values in data. IntervalSeries stores integer markers, so the value is fixed to -1.0.
|
——unit |
Attribute |
Base unit of measurement for working with the data. IntervalSeries stores integer markers with no physical unit, so the value is fixed to ‘n/a’.
|
2.7.4. FrequencyBandsTable
Overview: Table for describing the bands that DecompositionSeries was generated from. There should be one row in this table for each band.
FrequencyBandsTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Inherits from: DynamicTable, Container
Source filename: nwb.misc.yaml
Source Specification: see Section 3.8.4

Id |
Type |
Description |
|---|---|---|
<FrequencyBandsTable> |
Group |
Top level Group for <FrequencyBandsTable>
|
—band_name |
Dataset |
Name of the band, e.g., theta.
|
—band_limits |
Dataset |
Low and high limit of each band in Hz. If it is a Gaussian filter, use 2 SD on either side of the center.
|
—band_mean |
Dataset |
The center frequency (mean) of each Gaussian filter, in Hz.
|
—band_stdev |
Dataset |
The standard deviation (bandwidth) of each Gaussian filter, in Hz.
|
2.7.5. DecompositionSeries
Overview: Spectral analysis of a time series, e.g., of an LFP or a speech signal.
DecompositionSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.misc.yaml
Source Specification: see Section 3.8.5
Id |
Type |
Description |
|---|---|---|
<DecompositionSeries> |
Group |
Top level Group for <DecompositionSeries>
|
—data |
Dataset |
Data decomposed into frequency bands.
|
——unit |
Attribute |
Base unit of measurement for working with the data. Actual stored values are not necessarily stored in these units. To access the data in these units, multiply ‘data’ by ‘conversion’.
|
—metric |
Dataset |
The metric used, e.g., phase, amplitude, power.
|
—source_channels |
Dataset |
DynamicTableRegion pointer to the channels that this decomposition series was generated from.
|
—source_timeseries |
Link |
Link to TimeSeries object that this data was calculated from. Metadata about electrodes and their position can be read from that ElectricalSeries so it is not necessary to store that information here.
|
Id |
Type |
Description |
|---|---|---|
<DecompositionSeries> |
Group |
Top level Group for <DecompositionSeries>
|
—source_timeseries |
Link |
Link to TimeSeries object that this data was calculated from. Metadata about electrodes and their position can be read from that ElectricalSeries so it is not necessary to store that information here.
|
—bands |
Group |
Table for describing the bands that this series was generated from.
|
2.7.5.1. Groups: bands
Table for describing the bands that this series was generated from.
Extends: FrequencyBandsTable
Quantity: 0 or 1
Name: bands
2.7.6. Units
Overview: Data about spiking units. Event times of observed units (e.g., cell, synapse, etc.) should be concatenated and stored in spike_times.
Units extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Default Name: Units
Inherits from: DynamicTable, Container
Source filename: nwb.misc.yaml
Source Specification: see Section 3.8.6
Id |
Type |
Description |
|---|---|---|
<Units> |
Group |
Top level Group for <Units>
|
—spike_times_index |
Dataset |
Index into the spike_times dataset.
|
—spike_times |
Dataset |
Spike times for each unit, in seconds, relative to the session reference time (i.e., session_start_time or, if defined, timestamps_reference_time). Times should be stored in ascending order.
|
——resolution |
Attribute |
The temporal resolution of the spike times, in seconds. This is typically the sampling period (1/sampling_rate) of the acquisition data from which spikes were extracted. If the acquisition data was downsampled before spike sorting, the resolution should be based on the downsampled sampling rate (lower sampling rate, larger resolution value). If interpolation was applied during spike sorting, then spike times may fall between samples of the acquisition data, so the resolution should be the interpolation step size (higher sampling rate, smaller resolution value).
|
—obs_intervals_index |
Dataset |
Index into the obs_intervals dataset.
|
—obs_intervals |
Dataset |
Observation intervals for each unit, in seconds, relative to the session reference time (i.e., session_start_time or, if defined, timestamps_reference_time). Intervals should be in ascending order and non-overlapping.
|
—electrodes_index |
Dataset |
Index into electrodes.
|
—electrodes |
Dataset |
Electrode that each spike unit came from, specified using a DynamicTableRegion.
|
—electrode_group |
Dataset |
Electrode group that each spike unit came from.
|
—waveform_mean |
Dataset |
Spike waveform mean for each spike unit.
|
——sampling_rate |
Attribute |
Sampling rate, in hertz.
|
——unit |
Attribute |
Unit of measurement. This value is fixed to ‘volts’.
|
—waveform_sd |
Dataset |
Spike waveform standard deviation for each spike unit.
|
——sampling_rate |
Attribute |
Sampling rate, in hertz.
|
——unit |
Attribute |
Unit of measurement. This value is fixed to ‘volts’.
|
—waveforms |
Dataset |
Individual waveforms for each spike on each electrode. This is a doubly indexed column. The ‘waveforms_index’ column indexes which waveforms in this column belong to the same spike event for a given unit, where each waveform was recorded from a different electrode. The ‘waveforms_index_index’ column indexes the ‘waveforms_index’ column to indicate which spike events belong to a given unit. For example, if the ‘waveforms_index_index’ column has values [2, 5, 6], then the first 2 elements of the ‘waveforms_index’ column correspond to the 2 spike events of the first unit, the next 3 elements of the ‘waveforms_index’ column correspond to the 3 spike events of the second unit, and the next 1 element of the ‘waveforms_index’ column corresponds to the 1 spike event of the third unit. If the ‘waveforms_index’ column has values [3, 6, 8, 10, 12, 13], then the first 3 elements of the ‘waveforms’ column contain the 3 spike waveforms that were recorded from 3 different electrodes for the first spike time of the first unit. See https://nwb-schema.readthedocs.io/en/stable/format_description.html#doubly-ragged-arrays for a graphical representation of this example. When there is only one electrode for each unit (i.e., each spike time is associated with a single waveform), then the ‘waveforms_index’ column will have values 1, 2, …, N, where N is the number of spike events. The number of electrodes for each spike event should be the same within a given unit. The ‘electrodes’ column should be used to indicate which electrodes are associated with each unit, and the order of the waveforms within a given unit x spike event should be the same as the order of the electrodes referenced in the ‘electrodes’ column of this table. The number of samples for each waveform must be the same.
|
——sampling_rate |
Attribute |
Sampling rate, in hertz.
|
——unit |
Attribute |
Unit of measurement. This value is fixed to ‘volts’.
|
—waveforms_index |
Dataset |
Index into the ‘waveforms’ dataset. One value for every spike event. See ‘waveforms’ for more detail.
|
—waveforms_index_index |
Dataset |
Index into the ‘waveforms_index’ dataset. One value for every unit (row in the table). See ‘waveforms’ for more detail.
|
2.8. Behavior
This source module contains neurodata_types for behavior data.
2.8.1. SpatialSeries
Overview: Direction, e.g., of gaze or travel, or position. The TimeSeries::data field is a 2-D array storing position or direction relative to some reference frame. Array structure: [num measurements] [num dimensions]. Each SpatialSeries has a text dataset reference_frame that indicates the zero-position, or the zero-axes for direction. For example, if representing gaze direction, ‘straight-ahead’ might be a specific pixel on the monitor, or some other point in space. For position data, the 0,0 point might be the top-left corner of an enclosure, as viewed from the tracking camera. The unit of data will indicate how to interpret SpatialSeries values.
SpatialSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.behavior.yaml
Source Specification: see Section 3.9.1
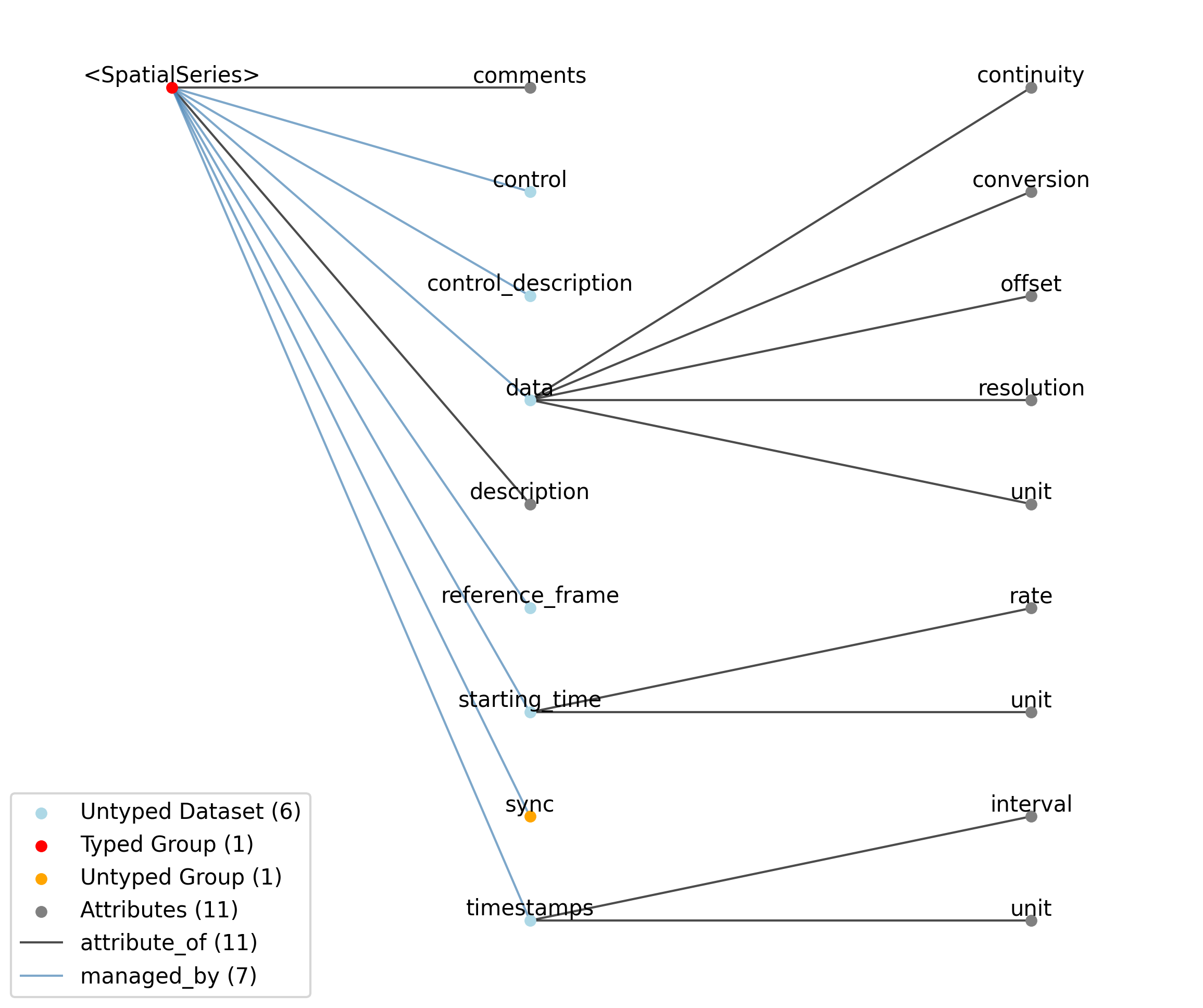
Id |
Type |
Description |
|---|---|---|
<SpatialSeries> |
Group |
Top level Group for <SpatialSeries>
|
—data |
Dataset |
1-D or 2-D array storing position or direction relative to some reference frame.
|
——unit |
Attribute |
Base unit of measurement for working with the data. The default value is ‘meters’. Actual stored values are not necessarily stored in these units. To access the data in these units, multiply ‘data’ by ‘conversion’ and add ‘offset’.
|
—reference_frame |
Dataset |
Description defining what exactly ‘straight-ahead’ means.
|
2.8.2. BehavioralEpochs
Overview: TimeSeries for storing behavioral epochs. The objective of this and the other two Behavioral interfaces (e.g., BehavioralEvents and BehavioralTimeSeries) is to provide generic hooks for software tools/scripts. This allows a tool/script to take the output of one specific interface (e.g., UnitTimes) and plot that data relative to another data modality (e.g., behavioral events) without having to define all possible modalities in advance. Declaring one of these interfaces means that one or more TimeSeries of the specified type are published. These TimeSeries should reside in a group having the same name as the interface. For example, if a BehavioralTimeSeries interface is declared, the module will have one or more TimeSeries defined in the module sub-group ‘BehavioralTimeSeries’. BehavioralEpochs should use IntervalSeries. BehavioralEvents is used for irregular events. BehavioralTimeSeries is for continuous data.
BehavioralEpochs extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: BehavioralEpochs
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.behavior.yaml
Source Specification: see Section 3.9.2
Id |
Type |
Description |
|---|---|---|
<BehavioralEpochs> |
Group |
Top level Group for <BehavioralEpochs>
|
Group |
IntervalSeries object containing start and stop times of epochs.
|
2.8.2.1. Groups: <IntervalSeries>
IntervalSeries object containing start and stop times of epochs.
Extends: IntervalSeries
Quantity: 1 or more
2.8.3. BehavioralEvents
Overview: DEPRECATED. Use an EventsTable instead, placed in the top-level /events group of the NWBFile. Each TimeSeries formerly stored under BehavioralEvents becomes one EventsTable. The timestamps field maps to the timestamp column, and the data field maps to an additional column named after the event marker (e.g., reward_magnitude, port_number); for multi-dimensional data, use one column per field. Any other per-event metadata becomes additional columns. Use the source_description attribute on the EventsTable to record where the events came from (e.g., “Acquisition system”, “Thresholding of analog signal ANALOG1 at 3 V”, “Manual video review”). Original definition: TimeSeries for storing behavioral events. See description of BehavioralEpochs for more details.
BehavioralEvents extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: BehavioralEvents
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.behavior.yaml
Source Specification: see Section 3.9.3
Id |
Type |
Description |
|---|---|---|
<BehavioralEvents> |
Group |
Top level Group for <BehavioralEvents>
|
—<TimeSeries> |
Group |
TimeSeries object containing behavioral events.
|
2.8.3.1. Groups: <TimeSeries>
TimeSeries object containing behavioral events.
Extends: TimeSeries
Quantity: 1 or more
2.8.4. BehavioralTimeSeries
Overview: TimeSeries for storing behavioral time series data. See description of BehavioralEpochs for more details.
BehavioralTimeSeries extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: BehavioralTimeSeries
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.behavior.yaml
Source Specification: see Section 3.9.4
Id |
Type |
Description |
|---|---|---|
<BehavioralTimeSeries> |
Group |
Top level Group for <BehavioralTimeSeries>
|
—<TimeSeries> |
Group |
TimeSeries object containing continuous behavioral data.
|
2.8.4.1. Groups: <TimeSeries>
TimeSeries object containing continuous behavioral data.
Extends: TimeSeries
Quantity: 1 or more
2.8.5. PupilTracking
Overview: Eye-tracking data, representing pupil size.
PupilTracking extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: PupilTracking
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.behavior.yaml
Source Specification: see Section 3.9.5
Id |
Type |
Description |
|---|---|---|
<PupilTracking> |
Group |
Top level Group for <PupilTracking>
|
—<TimeSeries> |
Group |
TimeSeries object containing time series data on pupil size.
|
2.8.5.1. Groups: <TimeSeries>
TimeSeries object containing time series data on pupil size.
Extends: TimeSeries
Quantity: 1 or more
2.8.6. EyeTracking
Overview: Eye-tracking data, representing direction of gaze.
EyeTracking extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: EyeTracking
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.behavior.yaml
Source Specification: see Section 3.9.6
Id |
Type |
Description |
|---|---|---|
<EyeTracking> |
Group |
Top level Group for <EyeTracking>
|
Group |
SpatialSeries object containing data measuring direction of gaze.
|
2.8.6.1. Groups: <SpatialSeries>
SpatialSeries object containing data measuring direction of gaze.
Extends: SpatialSeries
Quantity: 1 or more
2.8.7. CompassDirection
Overview: With a CompassDirection interface, a module publishes a SpatialSeries object representing a floating point value for theta. The SpatialSeries::reference_frame field should indicate what direction corresponds to 0 and which is the direction of rotation (this should be clockwise). The unit for the SpatialSeries should be radians or degrees.
CompassDirection extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: CompassDirection
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.behavior.yaml
Source Specification: see Section 3.9.7
Id |
Type |
Description |
|---|---|---|
<CompassDirection> |
Group |
Top level Group for <CompassDirection>
|
Group |
SpatialSeries object containing direction of gaze travel.
|
2.8.7.1. Groups: <SpatialSeries>
SpatialSeries object containing direction of gaze travel.
Extends: SpatialSeries
Quantity: 1 or more
2.8.8. Position
Overview: Position data, whether along the x, x/y, or x/y/z axes.
Position extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: Position
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.behavior.yaml
Source Specification: see Section 3.9.8
Id |
Type |
Description |
|---|---|---|
<Position> |
Group |
Top level Group for <Position>
|
Group |
SpatialSeries object containing position data.
|
2.8.8.1. Groups: <SpatialSeries>
SpatialSeries object containing position data.
Extends: SpatialSeries
Quantity: 1 or more
2.9. Extracellular electrophysiology
This source module contains neurodata_types for extracellular electrophysiology data.
2.9.1. ElectricalSeries
Overview: A time series of acquired voltage data from extracellular recordings. The data field is an int or float array storing data in volts. The first dimension should always represent time. The second dimension, if present, should represent channels.
ElectricalSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Subtypes: SpikeEventSeries
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.1
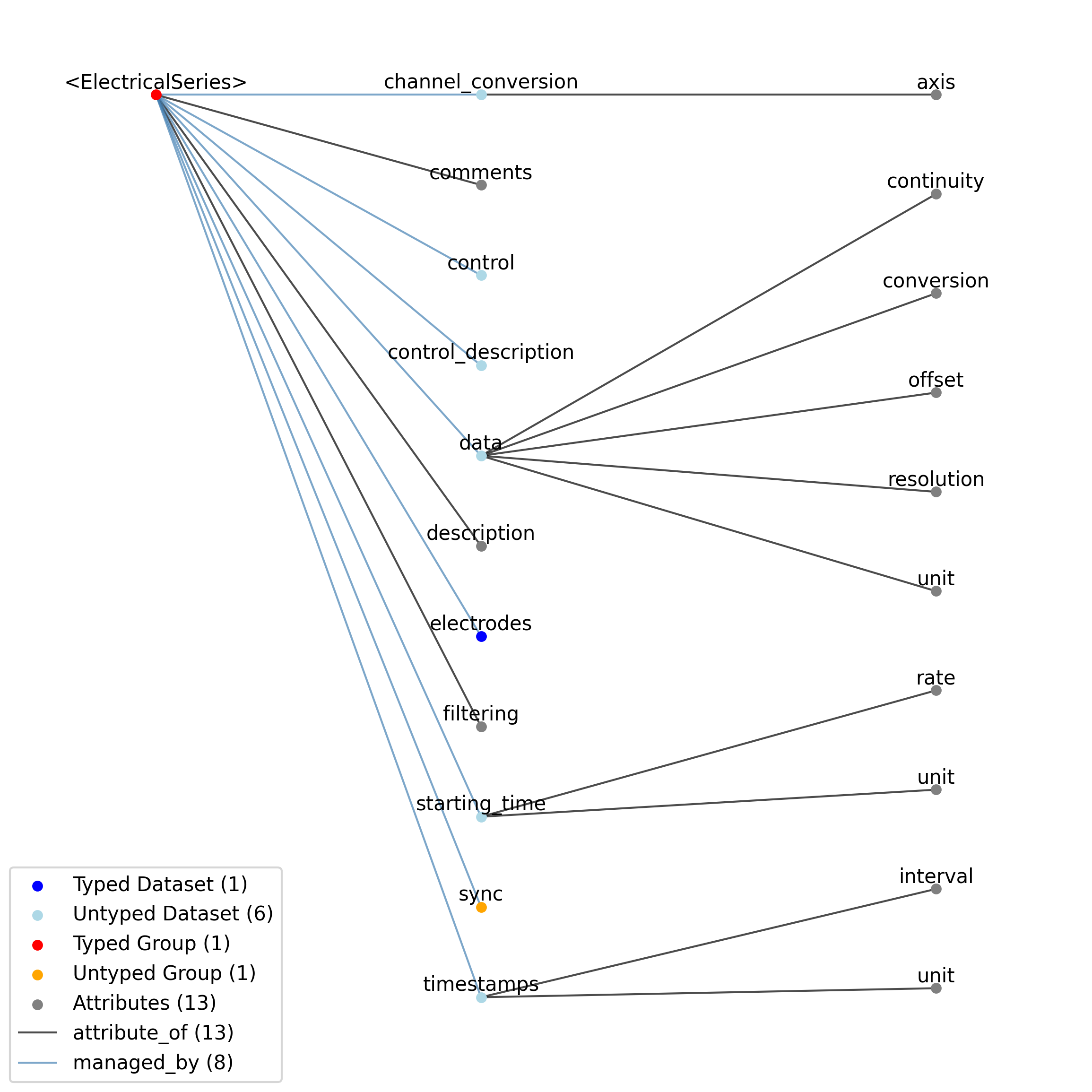
Id |
Type |
Description |
|---|---|---|
<ElectricalSeries> |
Group |
Top level Group for <ElectricalSeries>
|
—filtering |
Attribute |
Filtering applied to all channels of the data. For example, if this ElectricalSeries represents high-pass-filtered data (also known as AP Band), then this value could be “High-pass 4-pole Bessel filter at 500 Hz”. If this ElectricalSeries represents low-pass-filtered LFP data and the type of filter is unknown, then this value could be “Low-pass filter at 300 Hz”. If a non-standard filter type is used, provide as much detail about the filter properties as possible.
|
—data |
Dataset |
Recorded voltage data.
|
——unit |
Attribute |
Base unit of measurement for working with the data. This value is fixed to ‘volts’. Actual stored values are not necessarily stored in these units. To access the data in these units, multiply ‘data’ by ‘conversion’, followed by ‘channel_conversion’ (if present), and then add ‘offset’.
|
—electrodes |
Dataset |
DynamicTableRegion pointer to the electrodes that this time series was generated from.
|
—channel_conversion |
Dataset |
Channel-specific conversion factor. Multiply the data in the ‘data’ dataset by these values along the channel axis (as indicated by axis attribute) AND by the global conversion factor in the ‘conversion’ attribute of ‘data’ to get the data values in Volts, i.e., data in Volts = data * data.conversion * channel_conversion. This approach allows for both global and per-channel data conversion factors needed to support the storage of electrical recordings as native values generated by data acquisition systems. If this dataset is not present, then there is no channel-specific conversion factor, i.e., it is 1 for all channels.
|
——axis |
Attribute |
The zero-indexed axis of the ‘data’ dataset that the channel-specific conversion factor corresponds to. This value is fixed to 1.
|
2.9.2. SpikeEventSeries
Overview: Stores snapshots/snippets of recorded spike events (i.e., threshold crossings). This may also be raw data, as reported by ephys hardware. If so, the TimeSeries::description field should describe how events were detected. All events span the same recording channels and store snapshots of equal duration. TimeSeries::data array structure: [num events] [num channels] [num samples] (or [num events] [num samples] for single electrode).
SpikeEventSeries extends ElectricalSeries and includes all elements of ElectricalSeries with the following additions or changes.
Extends: ElectricalSeries
Primitive Type: Group
Inherits from: ElectricalSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.2
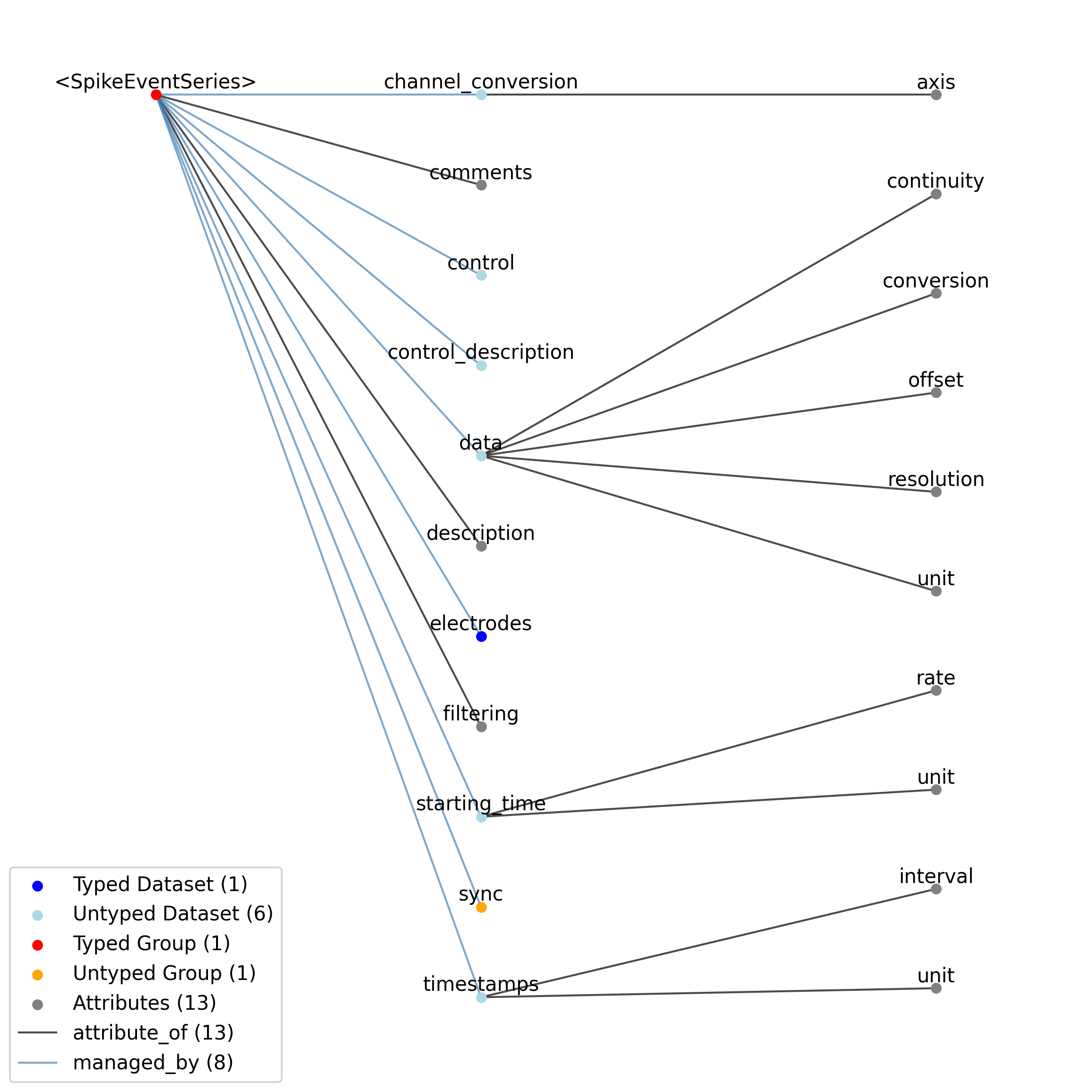
Id |
Type |
Description |
|---|---|---|
<SpikeEventSeries> |
Group |
Top level Group for <SpikeEventSeries>
|
—data |
Dataset |
Spike waveforms.
|
——unit |
Attribute |
Unit of measurement for waveforms, which is fixed to ‘volts’.
|
—timestamps |
Dataset |
Timestamps for samples stored in data, in seconds, relative to the common experiment master-clock stored in NWBFile.timestamps_reference_time. Timestamps are required for the events. Unlike for TimeSeries, timestamps are required for SpikeEventSeries and are thus re-specified here.
|
——interval |
Attribute |
Value is ‘1’
|
——unit |
Attribute |
Unit of measurement for timestamps, which is fixed to ‘seconds’.
|
2.9.3. FeatureExtraction
Overview: Features, such as PC1 and PC2, that are extracted from signals stored in a SpikeEventSeries or other source.
FeatureExtraction extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: FeatureExtraction
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.3
Id |
Type |
Description |
|---|---|---|
<FeatureExtraction> |
Group |
Top level Group for <FeatureExtraction>
|
—description |
Dataset |
Description of features (e.g., ‘’PC1’’) for each of the extracted features.
|
—features |
Dataset |
Multi-dimensional array of features extracted from each event.
|
—times |
Dataset |
Times of events that features correspond to (can be a link).
|
—electrodes |
Dataset |
DynamicTableRegion pointer to the electrodes that this time series was generated from.
|
2.9.4. EventDetection
Overview: Detected spike events from voltage trace(s).
EventDetection extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: EventDetection
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.4
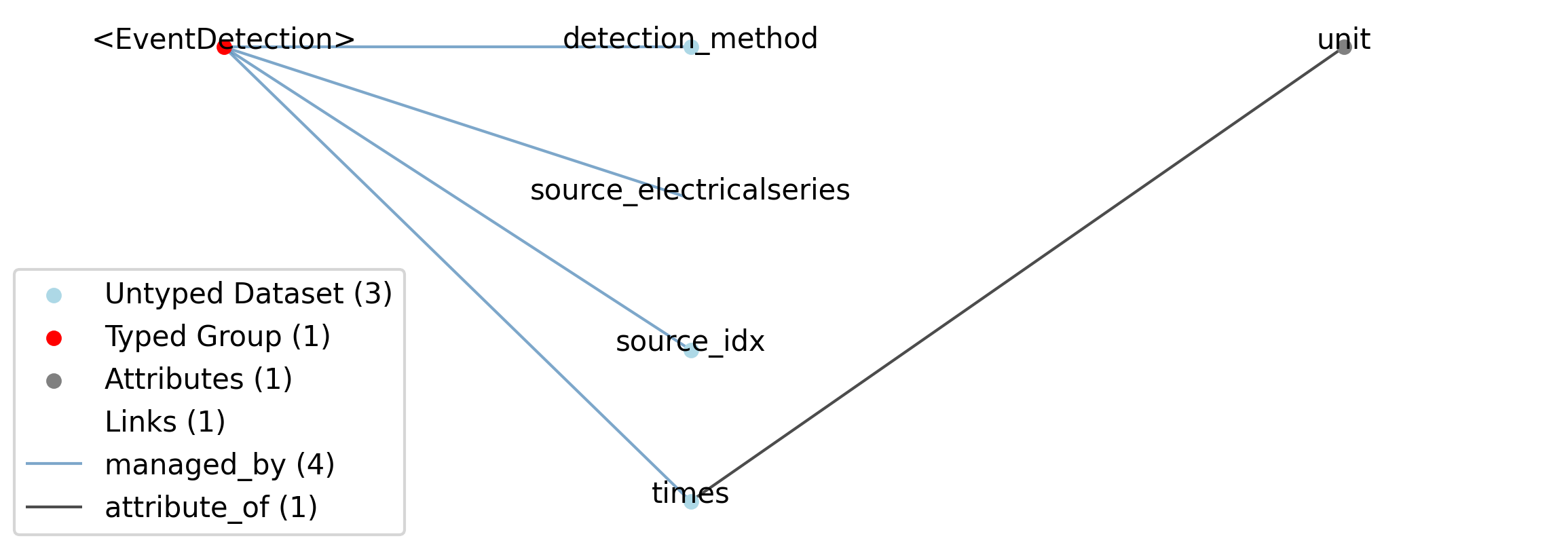
Id |
Type |
Description |
|---|---|---|
<EventDetection> |
Group |
Top level Group for <EventDetection>
|
—detection_method |
Dataset |
Description of how events were detected, such as voltage threshold, or dV/dT threshold, as well as relevant values.
|
—source_idx |
Dataset |
Indices (zero-based) into the linked source ElectricalSeries::data array corresponding to the time of each event, or the time and channel of each event. ‘’description’’ should define what is meant by time of event (e.g., .25 ms before action potential peak, zero-crossing time, etc.). The index points to each event from the raw data.
|
—times |
Dataset |
DEPRECATED. Timestamps of events, in seconds.
|
——unit |
Attribute |
Unit of measurement for event times, which is fixed to ‘seconds’.
|
—source_electricalseries |
Link |
Link to the ElectricalSeries that this data was calculated from. Metadata about electrodes and their position can be read from that ElectricalSeries so it is not necessary to include that information here.
|
Id |
Type |
Description |
|---|---|---|
<EventDetection> |
Group |
Top level Group for <EventDetection>
|
—source_electricalseries |
Link |
Link to the ElectricalSeries that this data was calculated from. Metadata about electrodes and their position can be read from that ElectricalSeries so it is not necessary to include that information here.
|
2.9.5. EventWaveform
Overview: DEPRECATED. Represents either the waveforms of detected events, as extracted from a raw data trace in /acquisition, or the event waveforms that were stored during experiment acquisition.
EventWaveform extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: EventWaveform
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.5
Id |
Type |
Description |
|---|---|---|
<EventWaveform> |
Group |
Top level Group for <EventWaveform>
|
Group |
SpikeEventSeries object(s) containing detected spike event waveforms.
|
2.9.5.1. Groups: <SpikeEventSeries>
SpikeEventSeries object(s) containing detected spike event waveforms.
Extends: SpikeEventSeries
Quantity: 1 or more
2.9.6. FilteredEphys
Overview: Electrophysiology data from one or more channels that has been subjected to filtering. Examples of filtered data include Theta and Gamma (LFP has its own interface). FilteredEphys modules publish an ElectricalSeries for each filtered channel or set of channels. The name of each ElectricalSeries is arbitrary but should be informative. The source of the filtered data, whether this is from analysis of another time series or as acquired by hardware, should be noted in the TimeSeries::description field of each ElectricalSeries. There is no assumed 1:1 correspondence between filtered ephys signals and electrodes, as a single signal can apply to many nearby electrodes, and one electrode may have different filtered (e.g., theta and/or gamma) signals represented. Filter properties should be noted in the ElectricalSeries ‘filtering’ attribute.
FilteredEphys extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: FilteredEphys
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.6
Id |
Type |
Description |
|---|---|---|
<FilteredEphys> |
Group |
Top level Group for <FilteredEphys>
|
Group |
ElectricalSeries object(s) containing filtered electrophysiology data.
|
2.9.6.1. Groups: <ElectricalSeries>
ElectricalSeries object(s) containing filtered electrophysiology data.
Extends: ElectricalSeries
Quantity: 1 or more
2.9.7. LFP
Overview: LFP data from one or more channels. The electrode map in each published ElectricalSeries will identify which channels are providing LFP data. Filter properties should be noted in the ElectricalSeries ‘filtering’ attribute.
LFP extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: LFP
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.7
Id |
Type |
Description |
|---|---|---|
<LFP> |
Group |
Top level Group for <LFP>
|
Group |
ElectricalSeries object(s) containing LFP data for one or more channels.
|
2.9.7.1. Groups: <ElectricalSeries>
ElectricalSeries object(s) containing LFP data for one or more channels.
Extends: ElectricalSeries
Quantity: 1 or more
2.9.8. ElectrodeGroup
Overview: A physical grouping of electrodes, e.g., a shank of an array. An electrode group is typically used to describe electrodes that are physically connected on a single device and are often (but not always) used together for analysis, such as for spike sorting. Note that this is descriptive metadata; electrodes from different groups can still be spike-sorted together if needed.
ElectrodeGroup extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.8
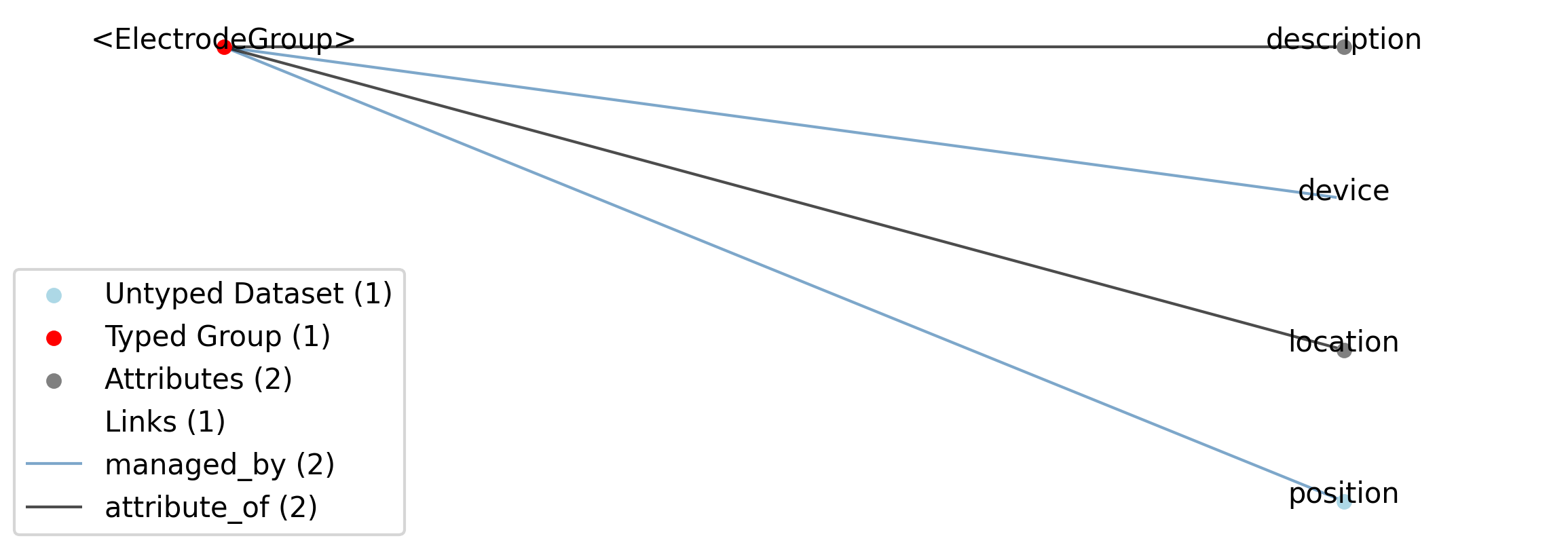
Id |
Type |
Description |
|---|---|---|
<ElectrodeGroup> |
Group |
Top level Group for <ElectrodeGroup>
|
—description |
Attribute |
Description of this electrode group.
|
—location |
Attribute |
Location of electrode group. Specify the area, layer, comments on estimation of area/layer, etc. Use standard atlas names for anatomical regions when possible.
|
—position |
Dataset |
Stereotaxic or common framework coordinates of the electrode group position.
|
—device |
Link |
Link to the device that was used to record from this electrode group.
|
Id |
Type |
Description |
|---|---|---|
<ElectrodeGroup> |
Group |
Top level Group for <ElectrodeGroup>
|
—device |
Link |
Link to the device that was used to record from this electrode group.
|
2.9.9. ElectrodesTable
Overview: A table of all electrodes (i.e., channels) used for recording. Introduced in NWB 2.8.0. Replaces the “electrodes” table (neurodata_type_inc DynamicTable, no neurodata_type_def) that is part of NWBFile.
ElectrodesTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Inherits from: DynamicTable, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.9
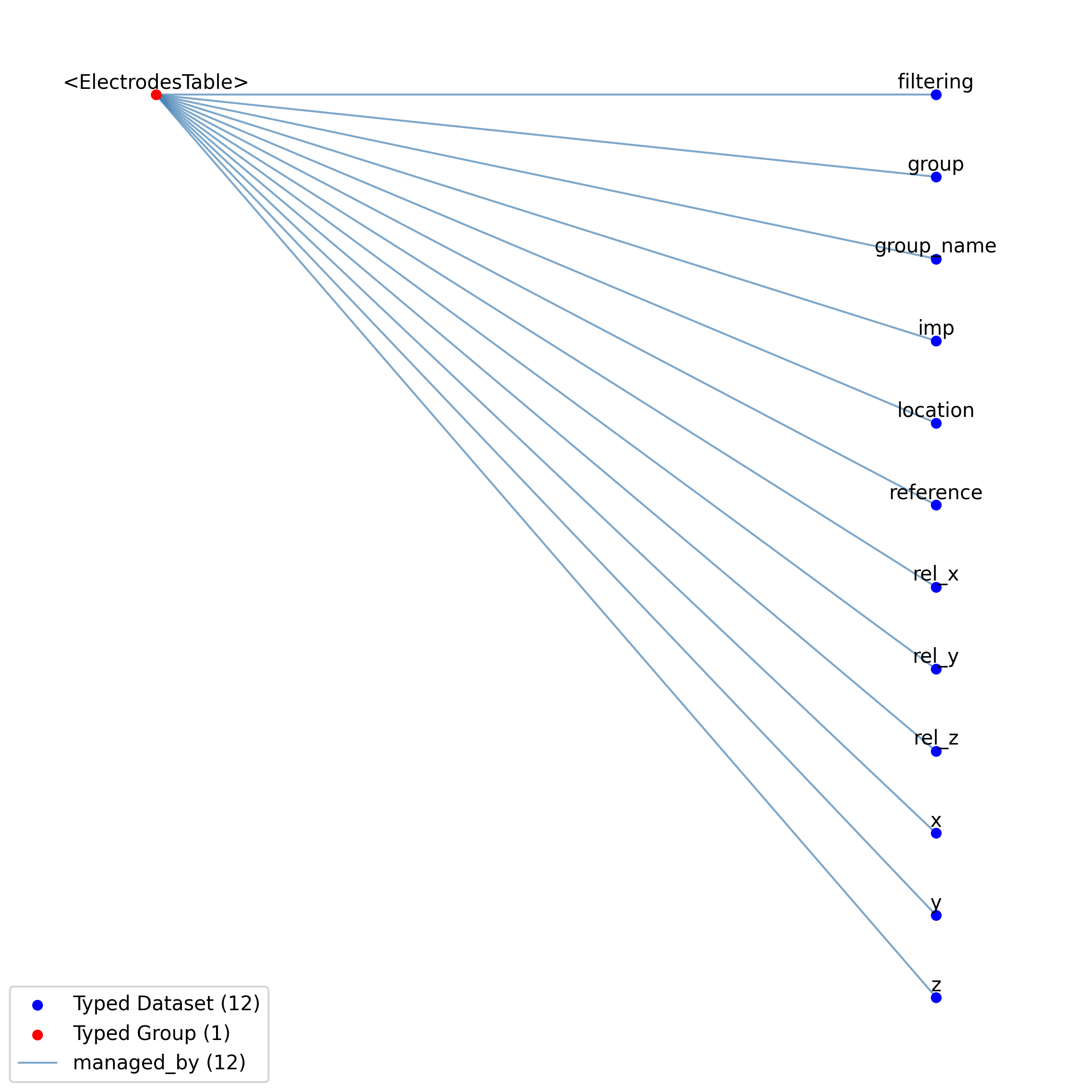
Id |
Type |
Description |
|---|---|---|
<ElectrodesTable> |
Group |
Top level Group for <ElectrodesTable>
|
—location |
Dataset |
Location of the electrode (channel). Specify the area, layer, comments on estimation of area/layer, stereotaxic coordinates if in vivo, etc. Use standard atlas names for anatomical regions when possible.
|
—group |
Dataset |
Reference to the ElectrodeGroup this electrode is a part of.
|
—group_name |
Dataset |
Name of the ElectrodeGroup this electrode is a part of.
|
—x |
Dataset |
x coordinate of the channel location in the brain (+x is posterior). Units should be specified in microns.
|
—y |
Dataset |
y coordinate of the channel location in the brain (+y is inferior). Units should be specified in microns.
|
—z |
Dataset |
z coordinate of the channel location in the brain (+z is right). Units should be specified in microns.
|
—imp |
Dataset |
Impedance of the channel, in ohms.
|
—filtering |
Dataset |
Description of hardware filtering, including the filter name and frequency cutoffs.
|
—rel_x |
Dataset |
x coordinate in electrode group. Units should be specified in microns.
|
—rel_y |
Dataset |
y coordinate in electrode group. Units should be specified in microns.
|
—rel_z |
Dataset |
z coordinate in electrode group. Units should be specified in microns.
|
—reference |
Dataset |
Description of the reference electrode and/or reference scheme used for this electrode, e.g., “stainless steel skull screw” or “online common average referencing”.
|
2.9.10. ClusterWaveforms
Overview: DEPRECATED. The mean waveform shape, including standard deviation, of the different clusters. Ideally, the waveform analysis should be performed on data that is only high-pass filtered. This is a separate module because it is expected to require updating. For example, IMEC probes may require different storage requirements to store/display mean waveforms, requiring a new interface or an extension of this one.
ClusterWaveforms extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: ClusterWaveforms
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.10
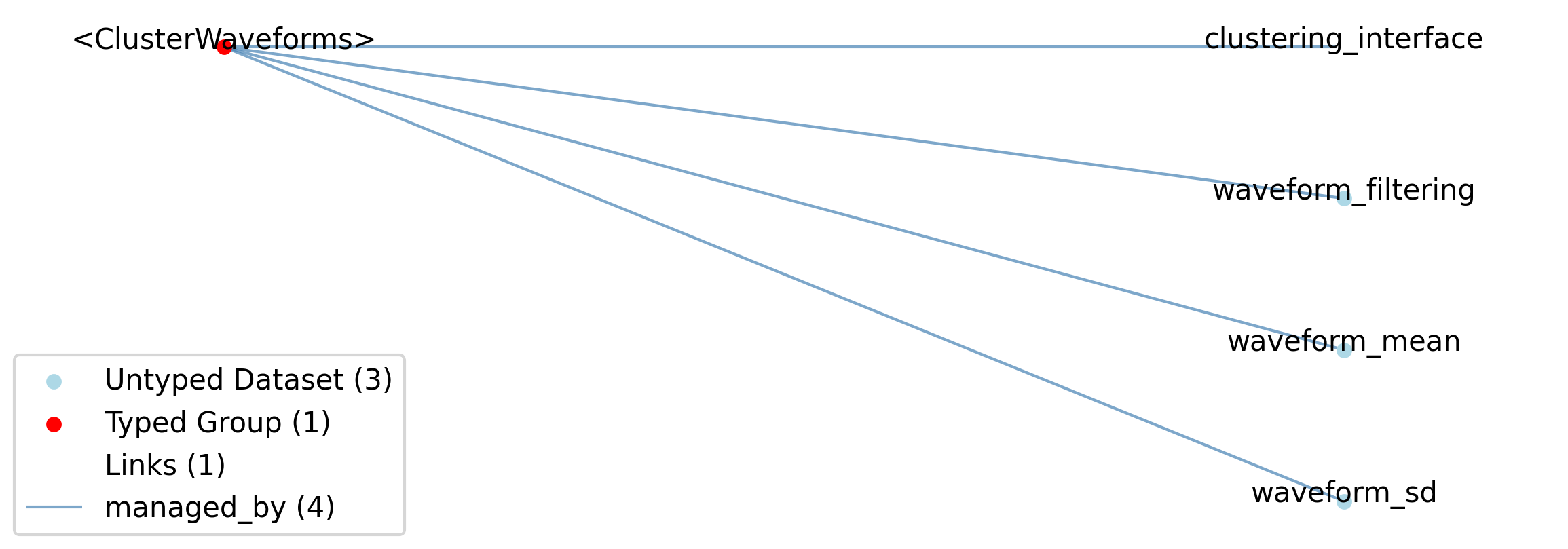
Id |
Type |
Description |
|---|---|---|
<ClusterWaveforms> |
Group |
Top level Group for <ClusterWaveforms>
|
—waveform_filtering |
Dataset |
Filtering applied to data before generating mean/sd
|
—waveform_mean |
Dataset |
The mean waveform for each cluster, using the same indices for each wave as cluster numbers in the associated Clustering module (i.e., cluster 3 is in array slot [3]). Waveforms corresponding to gaps in cluster sequence should be empty (e.g., zero-filled).
|
—waveform_sd |
Dataset |
Stdev of waveforms for each cluster, using the same indices as in mean.
|
—clustering_interface |
Link |
Link to Clustering interface that was the source of the clustered data.
|
Id |
Type |
Description |
|---|---|---|
<ClusterWaveforms> |
Group |
Top level Group for <ClusterWaveforms>
|
—clustering_interface |
Link |
Link to Clustering interface that was the source of the clustered data.
|
2.9.11. Clustering
Overview: DEPRECATED. Clustered spike data, whether from automatic clustering tools (e.g., klustakwik) or as a result of manual sorting.
Clustering extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: Clustering
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ecephys.yaml
Source Specification: see Section 3.10.11
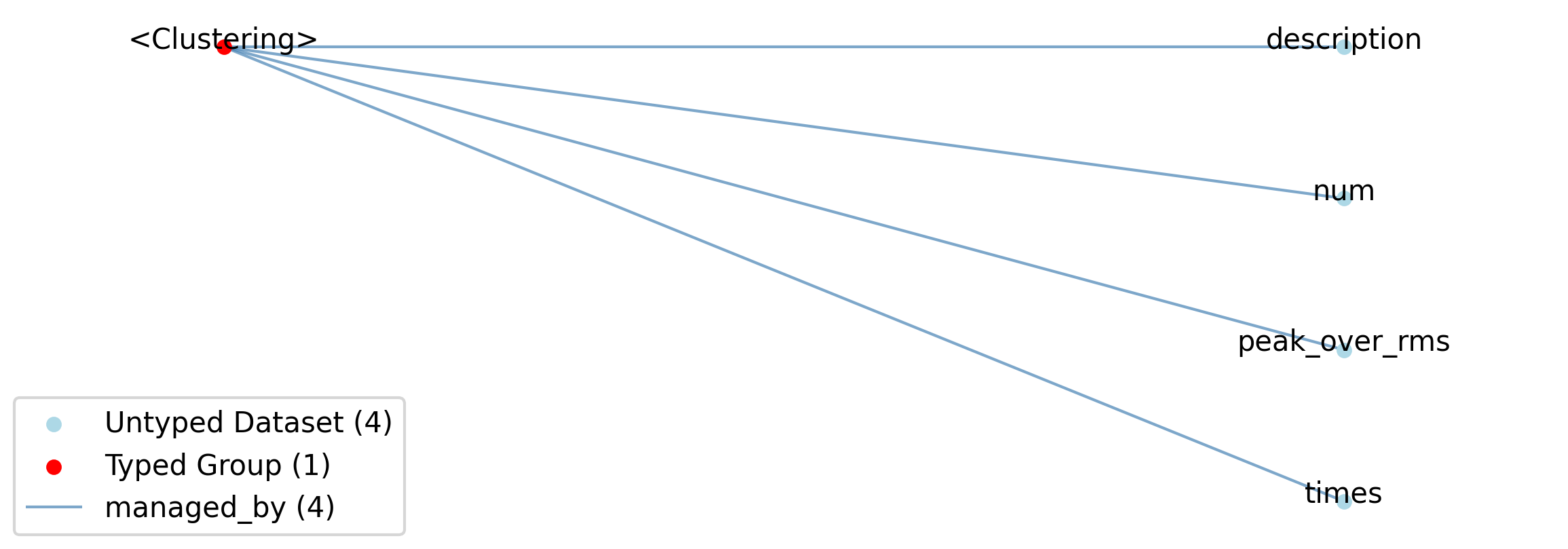
Id |
Type |
Description |
|---|---|---|
<Clustering> |
Group |
Top level Group for <Clustering>
|
—description |
Dataset |
Description of clusters or clustering (e.g., cluster 0 is noise, clusters curated using Klusters, etc.).
|
—num |
Dataset |
Cluster number of each event
|
—peak_over_rms |
Dataset |
Maximum ratio of waveform peak to RMS on any channel in the cluster (provides a basic clustering metric).
|
—times |
Dataset |
Times of clustered events, in seconds. This may be a link to times field in associated FeatureExtraction module.
|
2.10. Intracellular electrophysiology
This source module contains neurodata_types for intracellular electrophysiology data.
2.10.1. PatchClampSeries
Overview: An abstract base class for patch-clamp data - stimulus or response, current or voltage.
PatchClampSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Subtypes: VoltageClampSeries, IZeroClampSeries, CurrentClampStimulusSeries, CurrentClampSeries, VoltageClampStimulusSeries
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.1
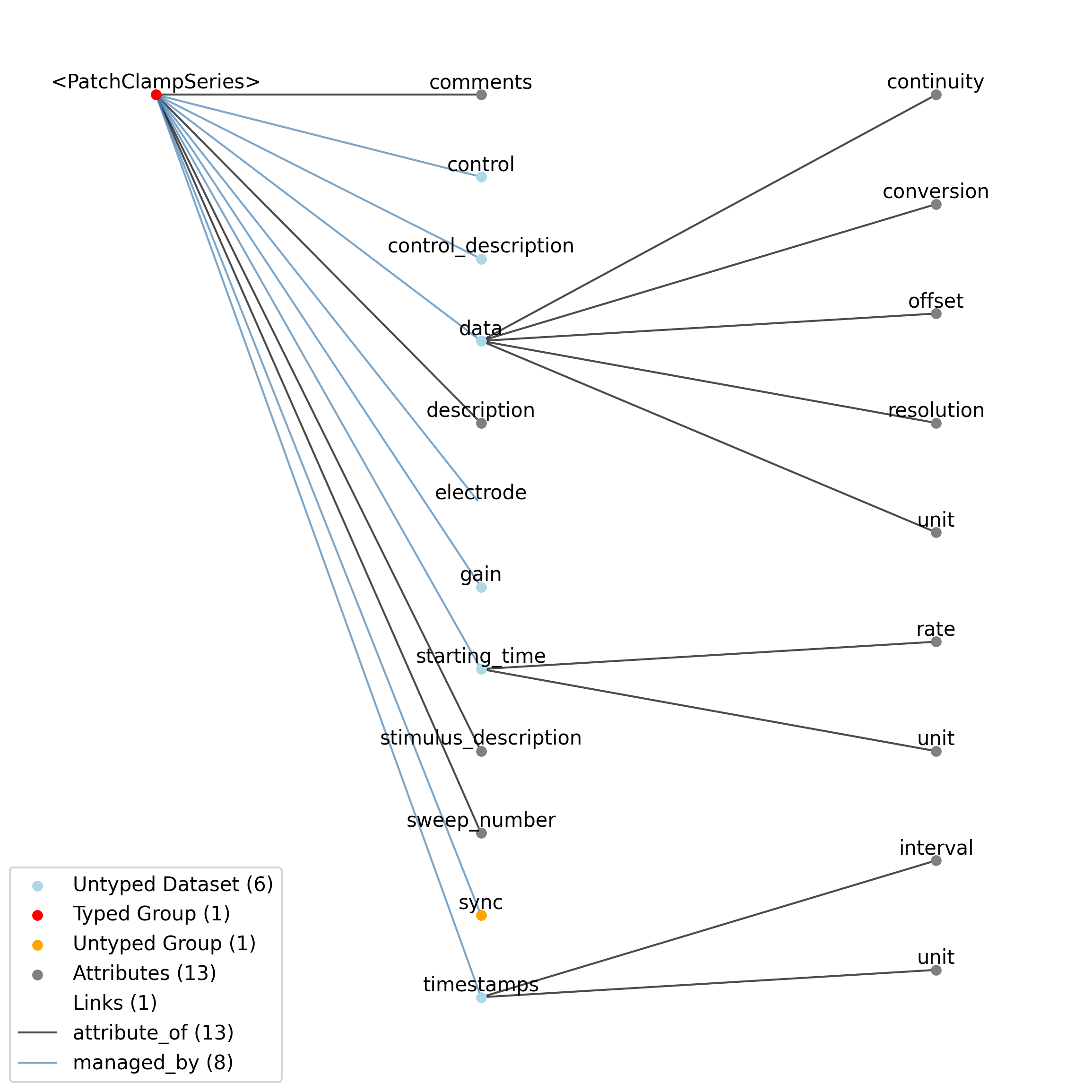
Id |
Type |
Description |
|---|---|---|
<PatchClampSeries> |
Group |
Top level Group for <PatchClampSeries>
|
—stimulus_description |
Attribute |
Protocol/stimulus name for this patch-clamp dataset.
|
—sweep_number |
Attribute |
Sweep number, allows users to group different PatchClampSeries together.
|
—data |
Dataset |
Recorded voltage or current.
|
——unit |
Attribute |
Base unit of measurement for working with the data. Actual stored values are not necessarily stored in these units. To access the data in these units, multiply ‘data’ by ‘conversion’ and add ‘offset’.
|
—gain |
Dataset |
Gain of the recording, in units Volt/Amp (v-clamp) or Volt/Volt (c-clamp).
|
—electrode |
Link |
Link to IntracellularElectrode object that describes the electrode that was used to apply or record this data.
|
Id |
Type |
Description |
|---|---|---|
<PatchClampSeries> |
Group |
Top level Group for <PatchClampSeries>
|
—electrode |
Link |
Link to IntracellularElectrode object that describes the electrode that was used to apply or record this data.
|
2.10.2. CurrentClampSeries
Overview: Voltage data from an intracellular current-clamp recording. A corresponding CurrentClampStimulusSeries (stored separately as a stimulus) is used to store the current injected.
CurrentClampSeries extends PatchClampSeries and includes all elements of PatchClampSeries with the following additions or changes.
Extends: PatchClampSeries
Primitive Type: Group
Inherits from: PatchClampSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Subtypes: IZeroClampSeries
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.2
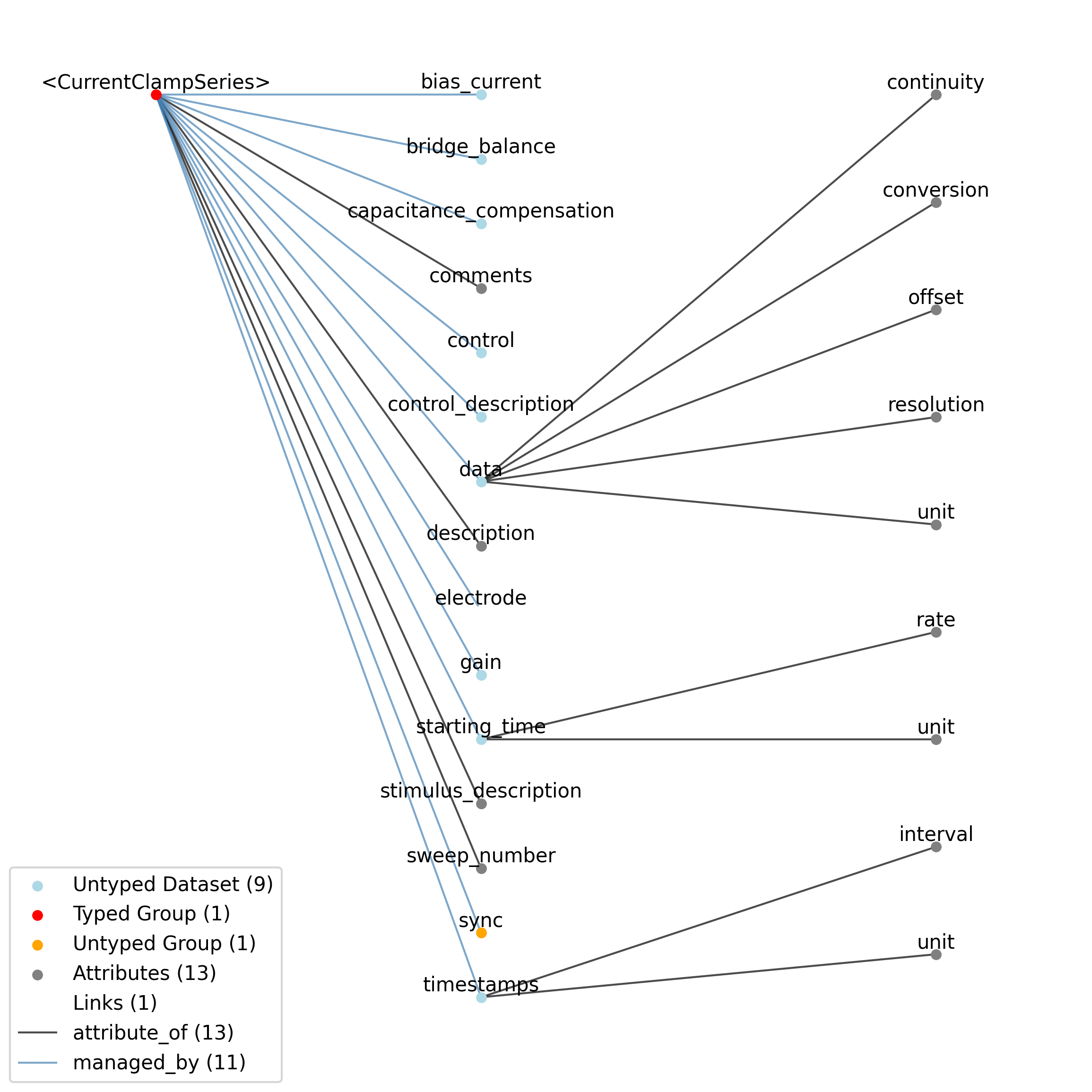
Id |
Type |
Description |
|---|---|---|
<CurrentClampSeries> |
Group |
Top level Group for <CurrentClampSeries>
|
—data |
Dataset |
Recorded voltage.
|
——unit |
Attribute |
Base unit of measurement for working with the data, which is fixed to ‘volts’. Actual stored values are not necessarily stored in these units. To access the data in these units, multiply ‘data’ by ‘conversion’ and add ‘offset’.
|
—bias_current |
Dataset |
Bias current, in amperes.
|
—bridge_balance |
Dataset |
Bridge balance, in ohms.
|
—capacitance_compensation |
Dataset |
Capacitance compensation, in farads.
|
2.10.3. IZeroClampSeries
Overview: Voltage data from an intracellular recording when all current and amplifier settings are off (i.e., CurrentClampSeries fields will be zero). There is no CurrentClampStimulusSeries associated with an IZero series because the amplifier is disconnected and no stimulus can reach the cell.
IZeroClampSeries extends CurrentClampSeries and includes all elements of CurrentClampSeries with the following additions or changes.
Extends: CurrentClampSeries
Primitive Type: Group
Inherits from: CurrentClampSeries, PatchClampSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.3
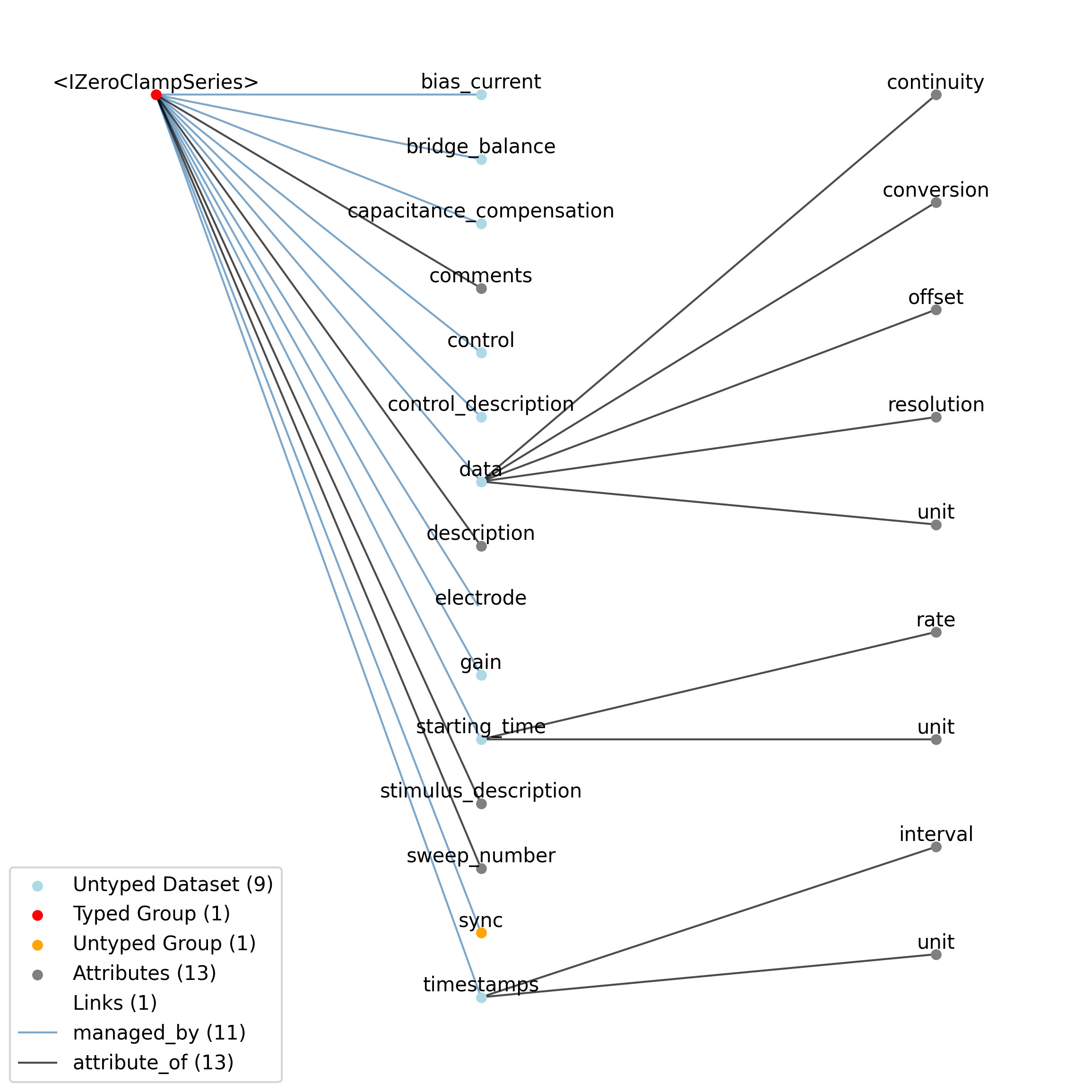
Id |
Type |
Description |
|---|---|---|
<IZeroClampSeries> |
Group |
Top level Group for <IZeroClampSeries>
|
—stimulus_description |
Attribute |
An IZeroClampSeries has no stimulus, so this attribute is automatically set to “N/A”.
|
—bias_current |
Dataset |
Bias current, in amperes, fixed to 0.0.
|
—bridge_balance |
Dataset |
Bridge balance, in ohms, fixed to 0.0.
|
—capacitance_compensation |
Dataset |
Capacitance compensation, in farads, fixed to 0.0.
|
2.10.4. CurrentClampStimulusSeries
Overview: Stimulus current applied during current clamp recording.
CurrentClampStimulusSeries extends PatchClampSeries and includes all elements of PatchClampSeries with the following additions or changes.
Extends: PatchClampSeries
Primitive Type: Group
Inherits from: PatchClampSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.4
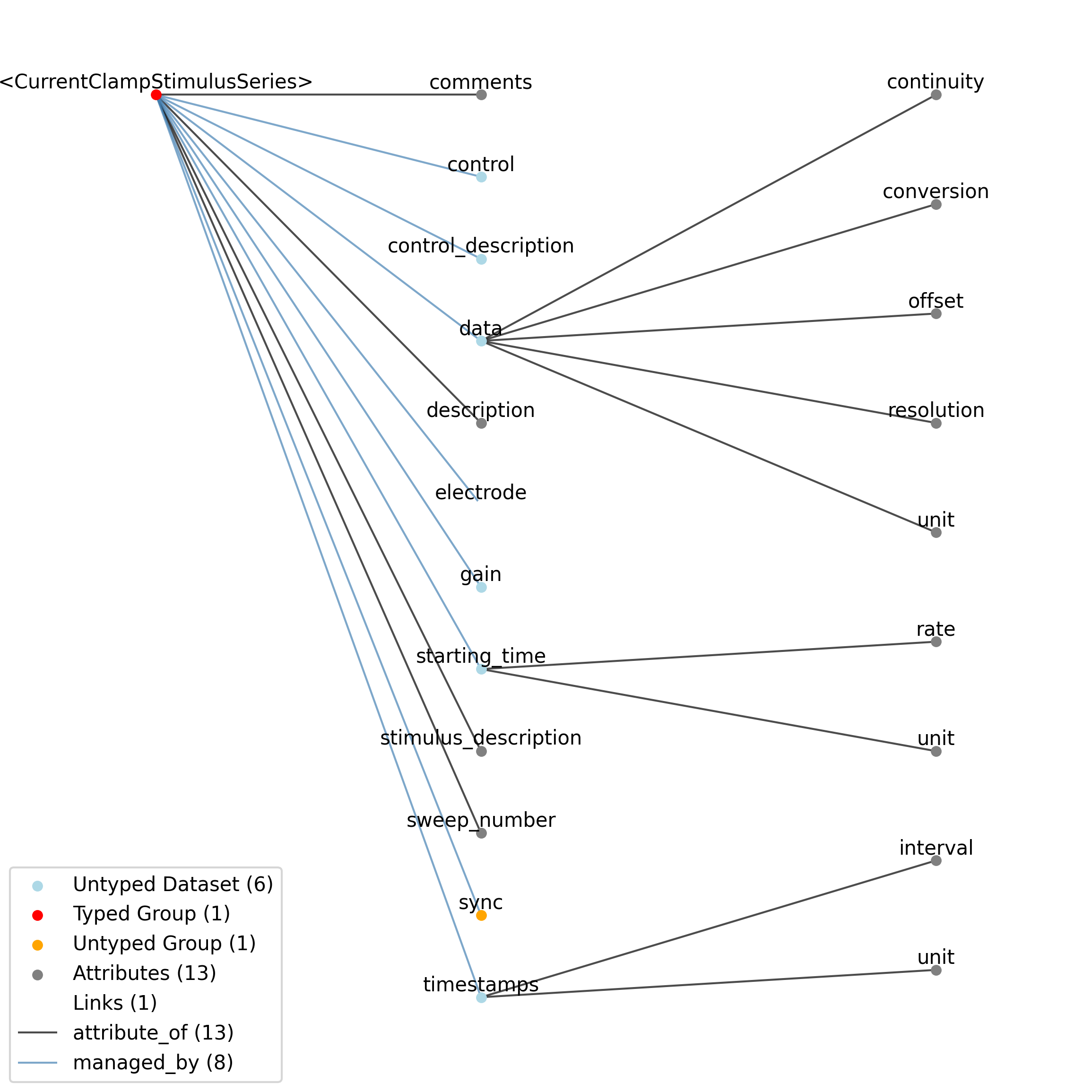
Id |
Type |
Description |
|---|---|---|
<CurrentClampStimulusSeries> |
Group |
Top level Group for <CurrentClampStimulusSeries>
|
—data |
Dataset |
Stimulus current applied.
|
——unit |
Attribute |
Base unit of measurement for working with the data, which is fixed to ‘amperes’. Actual stored values are not necessarily stored in these units. To access the data in these units, multiply ‘data’ by ‘conversion’ and add ‘offset’.
|
2.10.5. VoltageClampSeries
Overview: Current data from an intracellular voltage-clamp recording. A corresponding VoltageClampStimulusSeries (stored separately as a stimulus) is used to store the voltage injected.
VoltageClampSeries extends PatchClampSeries and includes all elements of PatchClampSeries with the following additions or changes.
Extends: PatchClampSeries
Primitive Type: Group
Inherits from: PatchClampSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.5
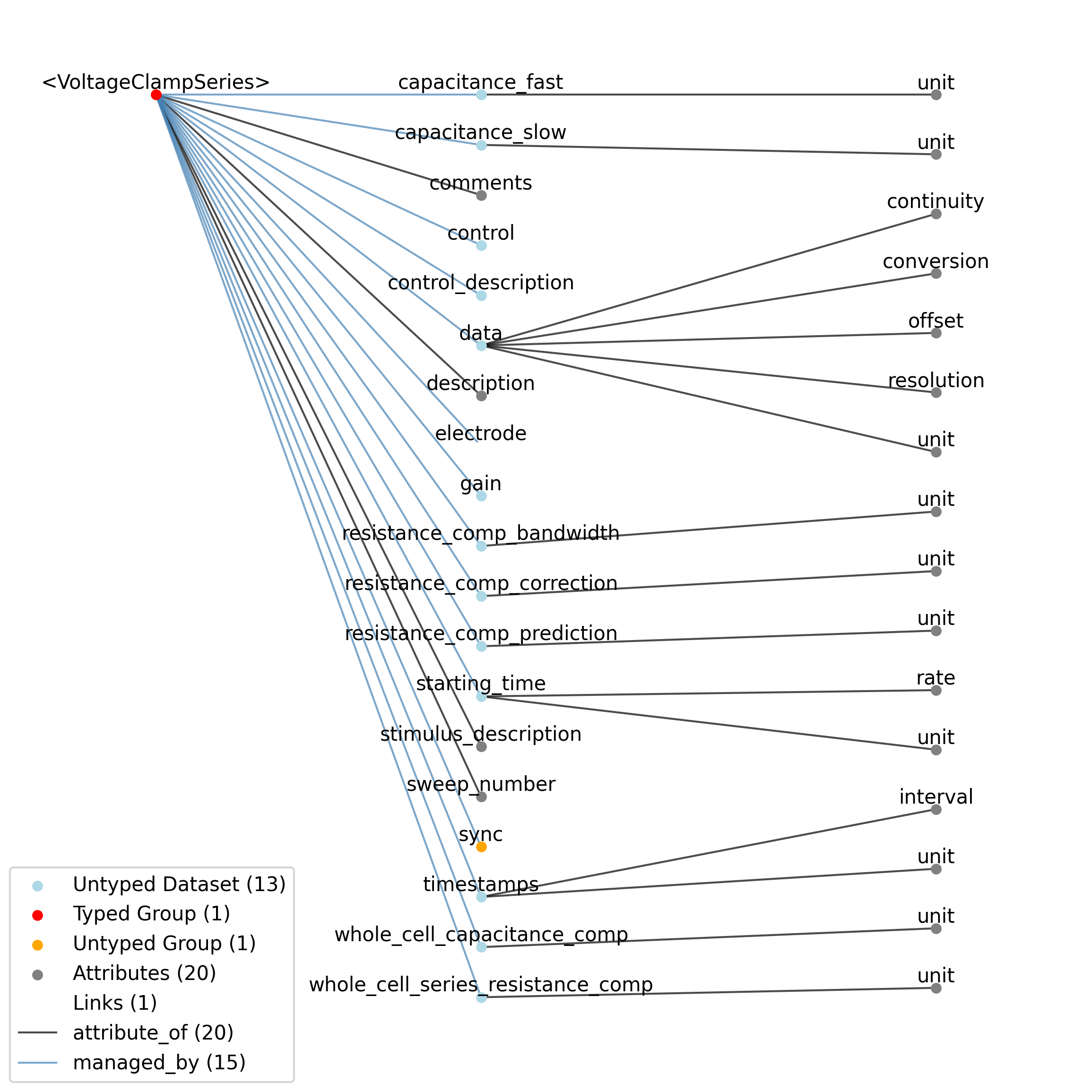
Id |
Type |
Description |
|---|---|---|
<VoltageClampSeries> |
Group |
Top level Group for <VoltageClampSeries>
|
—data |
Dataset |
Recorded current.
|
——unit |
Attribute |
Base unit of measurement for working with the data, which is fixed to ‘amperes’. Actual stored values are not necessarily stored in these units. To access the data in these units, multiply ‘data’ by ‘conversion’ and add ‘offset’.
|
—capacitance_fast |
Dataset |
Fast capacitance, in farads.
|
——unit |
Attribute |
Unit of measurement for capacitance_fast, which is fixed to ‘farads’.
|
—capacitance_slow |
Dataset |
Slow capacitance, in farads.
|
——unit |
Attribute |
Unit of measurement for capacitance_slow, which is fixed to ‘farads’.
|
—resistance_comp_bandwidth |
Dataset |
Resistance compensation bandwidth, in hertz.
|
——unit |
Attribute |
Unit of measurement for resistance_comp_bandwidth, which is fixed to ‘hertz’.
|
—resistance_comp_correction |
Dataset |
Resistance compensation correction, in percent.
|
——unit |
Attribute |
Unit of measurement for resistance_comp_correction, which is fixed to ‘percent’.
|
—resistance_comp_prediction |
Dataset |
Resistance compensation prediction, in percent.
|
——unit |
Attribute |
Unit of measurement for resistance_comp_prediction, which is fixed to ‘percent’.
|
—whole_cell_capacitance_comp |
Dataset |
Whole cell capacitance compensation, in farads.
|
——unit |
Attribute |
Unit of measurement for whole_cell_capacitance_comp, which is fixed to ‘farads’.
|
—whole_cell_series_resistance_comp |
Dataset |
Whole cell series resistance compensation, in ohms.
|
——unit |
Attribute |
Unit of measurement for whole_cell_series_resistance_comp, which is fixed to ‘ohms’.
|
2.10.6. VoltageClampStimulusSeries
Overview: Stimulus voltage applied during a voltage clamp recording.
VoltageClampStimulusSeries extends PatchClampSeries and includes all elements of PatchClampSeries with the following additions or changes.
Extends: PatchClampSeries
Primitive Type: Group
Inherits from: PatchClampSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.6
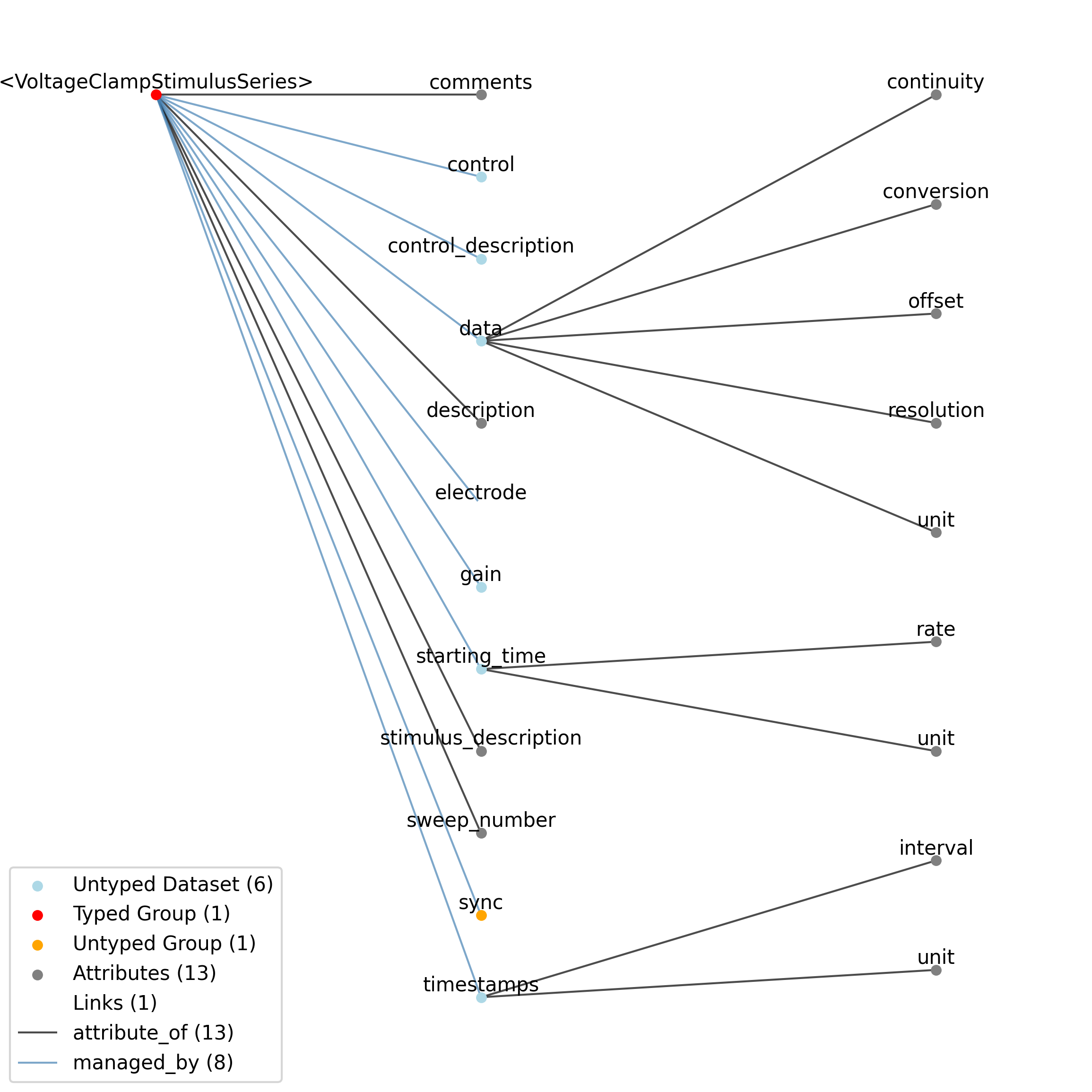
Id |
Type |
Description |
|---|---|---|
<VoltageClampStimulusSeries> |
Group |
Top level Group for <VoltageClampStimulusSeries>
|
—data |
Dataset |
Stimulus voltage applied.
|
——unit |
Attribute |
Base unit of measurement for working with the data, which is fixed to ‘volts’. Actual stored values are not necessarily stored in these units. To access the data in these units, multiply ‘data’ by ‘conversion’ and add ‘offset’.
|
2.10.7. IntracellularElectrode
Overview: An intracellular electrode and its metadata.
IntracellularElectrode extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.7
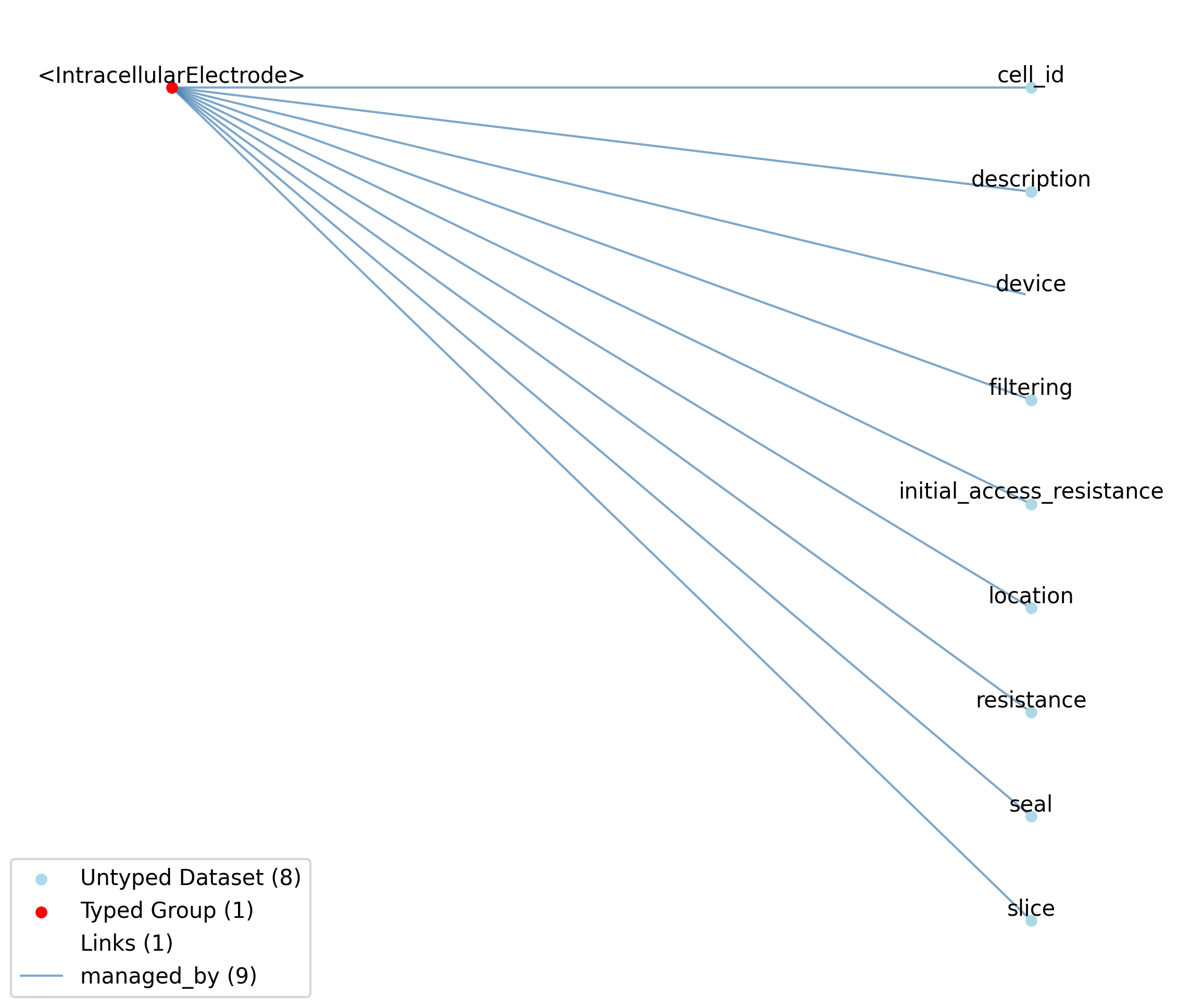
Id |
Type |
Description |
|---|---|---|
<IntracellularElectrode> |
Group |
Top level Group for <IntracellularElectrode>
|
—cell_id |
Dataset |
Unique identifier of the cell.
|
—description |
Dataset |
Description of electrode (e.g., whole-cell, sharp, etc.).
|
—filtering |
Dataset |
Electrode specific filtering.
|
—initial_access_resistance |
Dataset |
Initial access resistance.
|
—location |
Dataset |
Location of the electrode. Specify the area, layer, comments on estimation of area/layer, stereotaxic coordinates if in vivo, etc. Use standard atlas names for anatomical regions when possible.
|
—resistance |
Dataset |
Electrode resistance, in ohms.
|
—seal |
Dataset |
Information about seal used for recording.
|
—slice |
Dataset |
Information about slice used for recording.
|
—device |
Link |
Device that was used to record from this electrode.
|
Id |
Type |
Description |
|---|---|---|
<IntracellularElectrode> |
Group |
Top level Group for <IntracellularElectrode>
|
—device |
Link |
Device that was used to record from this electrode.
|
2.10.8. SweepTable
Overview: [DEPRECATED] Table used to group different PatchClampSeries. SweepTable is being replaced by IntracellularRecordingsTable and SimultaneousRecordingsTable tables. Additional SequentialRecordingsTable, RepetitionsTable, and ExperimentalConditions tables provide enhanced support for experiment metadata.
SweepTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Inherits from: DynamicTable, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.8

Id |
Type |
Description |
|---|---|---|
<SweepTable> |
Group |
Top level Group for <SweepTable>
|
—sweep_number |
Dataset |
Sweep number of the PatchClampSeries in that row.
|
—series |
Dataset |
The PatchClampSeries with the sweep number in that row.
|
—series_index |
Dataset |
Index for series.
|
2.10.9. IntracellularElectrodesTable
Overview: Table for storing intracellular electrode related metadata.
IntracellularElectrodesTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Inherits from: DynamicTable, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.9
Id |
Type |
Description |
|---|---|---|
<IntracellularElectrodesTable> |
Group |
Top level Group for <IntracellularElectrodesTable>
|
—description |
Attribute |
Description of what is in this dynamic table.
|
—electrode |
Dataset |
Column for storing the reference to the intracellular electrode.
|
2.10.10. IntracellularStimuliTable
Overview: Table for storing intracellular stimulus related metadata.
IntracellularStimuliTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Inherits from: DynamicTable, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.10
Id |
Type |
Description |
|---|---|---|
<IntracellularStimuliTable> |
Group |
Top level Group for <IntracellularStimuliTable>
|
—description |
Attribute |
Description of what is in this dynamic table.
|
—stimulus |
Dataset |
Column storing the reference to the recorded stimulus for the recording (rows).
|
—stimulus_template |
Dataset |
Column storing the reference to the stimulus template for the recording (rows).
|
2.10.11. IntracellularResponsesTable
Overview: Table for storing intracellular response related metadata.
IntracellularResponsesTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Inherits from: DynamicTable, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.11
Id |
Type |
Description |
|---|---|---|
<IntracellularResponsesTable> |
Group |
Top level Group for <IntracellularResponsesTable>
|
—description |
Attribute |
Description of what is in this dynamic table.
|
—response |
Dataset |
Column storing the reference to the recorded response for the recording (rows).
|
2.10.12. IntracellularRecordingsTable
Overview: A table to group together a stimulus and response from a single electrode and a single simultaneous recording. Each row in the table represents a single recording consisting typically of a stimulus and a corresponding response. In some cases, however, only a stimulus or a response is recorded as part of an experiment. In this case, both the stimulus and response will point to the same TimeSeries while the idx_start and count of the invalid column will be set to -1, thus, indicating that no values have been recorded for the stimulus or response, respectively. Note, a recording MUST contain at least a stimulus or a response. Typically the stimulus and response are PatchClampSeries. However, the use of AD/DA channels that are not associated to an electrode is also common in intracellular electrophysiology, in which case other TimeSeries may be used.
IntracellularRecordingsTable extends AlignedDynamicTable and includes all elements of AlignedDynamicTable with the following additions or changes.
Extends: AlignedDynamicTable
Primitive Type: Group
Name: intracellular_recordings
Inherits from: AlignedDynamicTable, DynamicTable, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.12
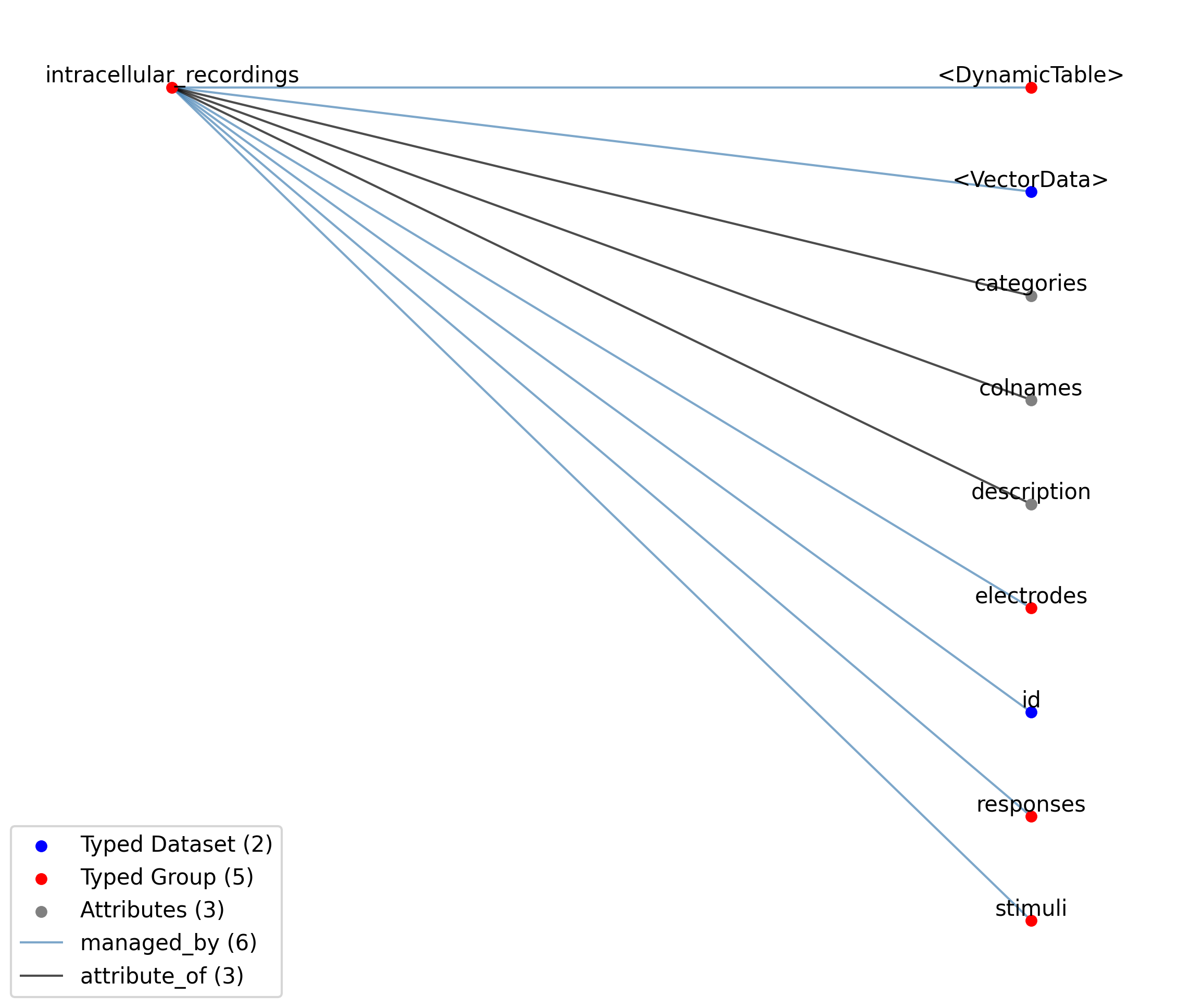
Id |
Type |
Description |
|---|---|---|
intracellular_recordings |
Group |
Top level Group for intracellular_recordings
|
—description |
Attribute |
Description of the contents of this table. Inherited from AlignedDynamicTable and overwritten here to fix the value of the attribute.
|
Id |
Type |
Description |
|---|---|---|
intracellular_recordings |
Group |
Top level Group for intracellular_recordings
|
—electrodes |
Group |
Table for storing intracellular electrode related metadata.
|
—stimuli |
Group |
Table for storing intracellular stimulus related metadata.
|
—responses |
Group |
Table for storing intracellular response related metadata.
|
2.10.12.1. Groups: electrodes
Table for storing intracellular electrode related metadata.
Extends: IntracellularElectrodesTable
Name: electrodes
2.10.12.2. Groups: stimuli
Table for storing intracellular stimulus related metadata.
Extends: IntracellularStimuliTable
Name: stimuli
2.10.12.3. Groups: responses
Table for storing intracellular response related metadata.
Extends: IntracellularResponsesTable
Name: responses
2.10.13. SimultaneousRecordingsTable
Overview: A table for grouping different intracellular recordings from the IntracellularRecordingsTable table together that were recorded simultaneously from different electrodes.
SimultaneousRecordingsTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Name: simultaneous_recordings
Inherits from: DynamicTable, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.13
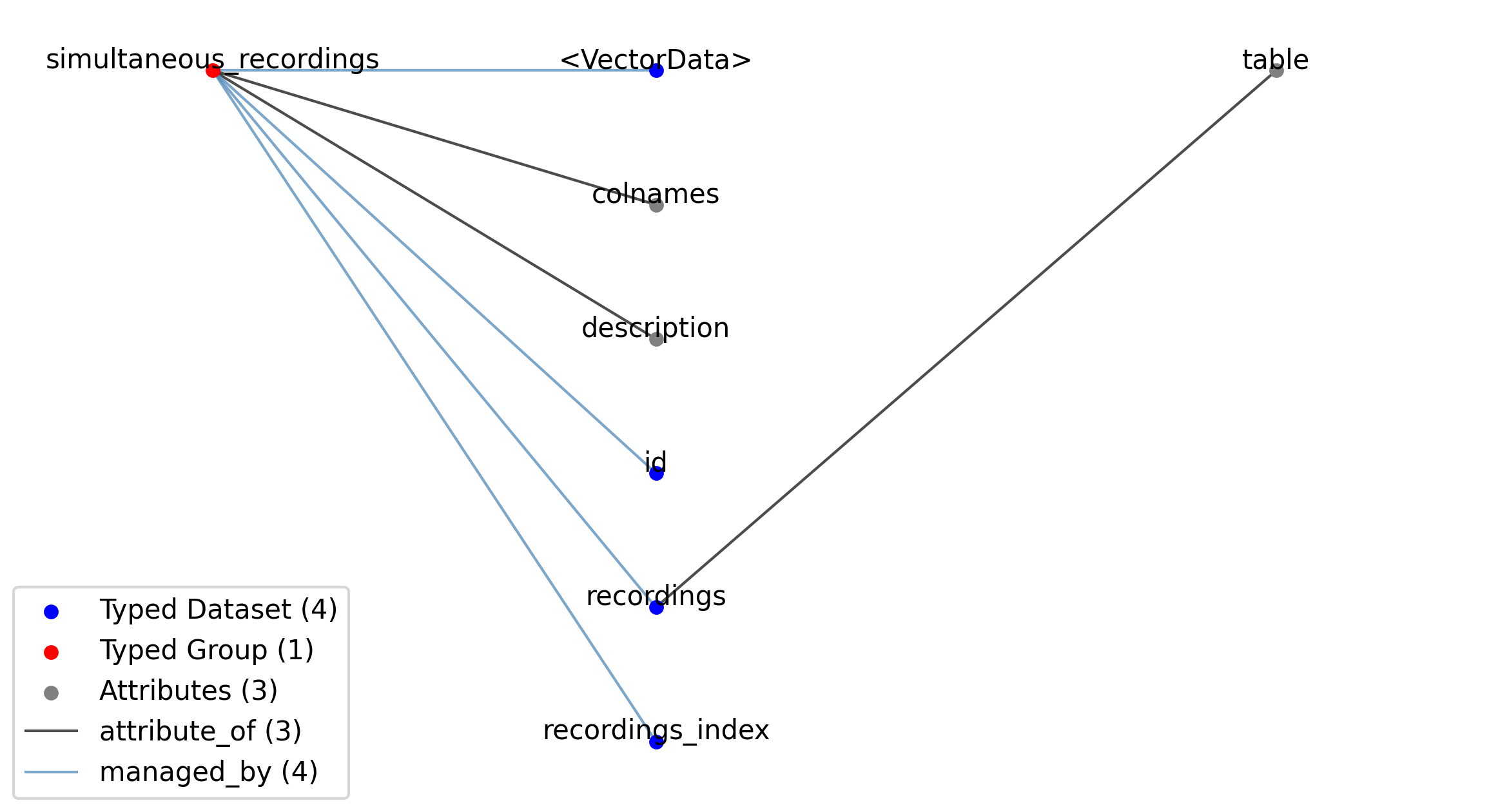
Id |
Type |
Description |
|---|---|---|
simultaneous_recordings |
Group |
Top level Group for simultaneous_recordings
|
—recordings |
Dataset |
A reference to one or more rows in the IntracellularRecordingsTable table.
|
——table |
Attribute |
Reference to the IntracellularRecordingsTable table that this table region applies to. This specializes the attribute inherited from DynamicTableRegion to fix the type of table that can be referenced here.
|
—recordings_index |
Dataset |
Index dataset for the recordings column.
|
2.10.14. SequentialRecordingsTable
Overview: A table for grouping different sequential recordings from the SimultaneousRecordingsTable table together. This is typically used to group together sequential recordings where a sequence of stimuli of the same type with varying parameters have been presented in a sequence.
SequentialRecordingsTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Name: sequential_recordings
Inherits from: DynamicTable, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.14
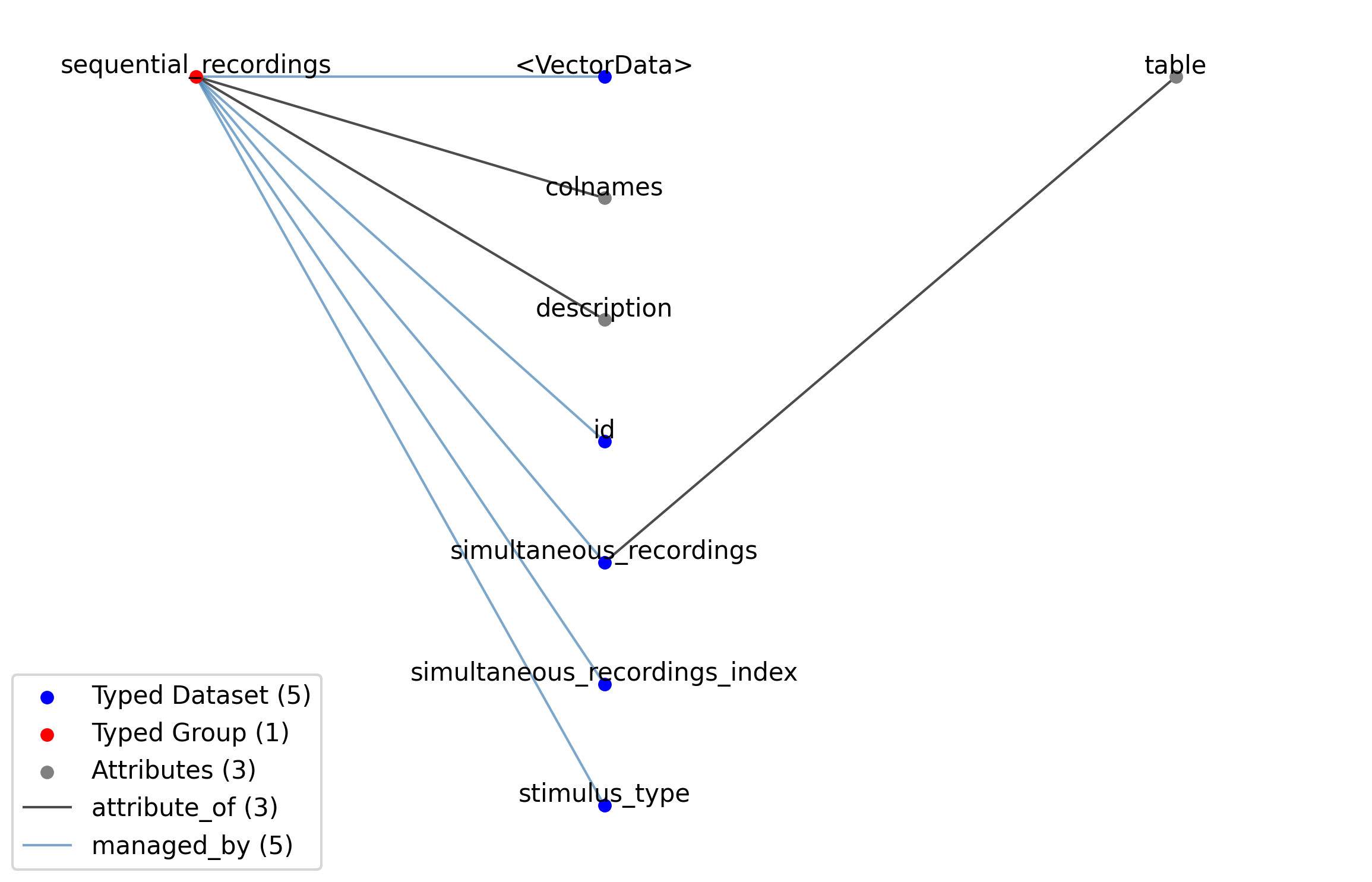
Id |
Type |
Description |
|---|---|---|
sequential_recordings |
Group |
Top level Group for sequential_recordings
|
—simultaneous_recordings |
Dataset |
A reference to one or more rows in the SimultaneousRecordingsTable table.
|
——table |
Attribute |
Reference to the SimultaneousRecordingsTable table that this table region applies to. This specializes the attribute inherited from DynamicTableRegion to fix the type of table that can be referenced here.
|
—simultaneous_recordings_index |
Dataset |
Index dataset for the simultaneous_recordings column.
|
—stimulus_type |
Dataset |
The type of stimulus used for the sequential recording.
|
2.10.15. RepetitionsTable
Overview: A table for grouping different sequential intracellular recordings together. With each SequentialRecording typically representing a particular type of stimulus, the RepetitionsTable table is typically used to group sets of stimuli applied in sequence.
RepetitionsTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Name: repetitions
Inherits from: DynamicTable, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.15
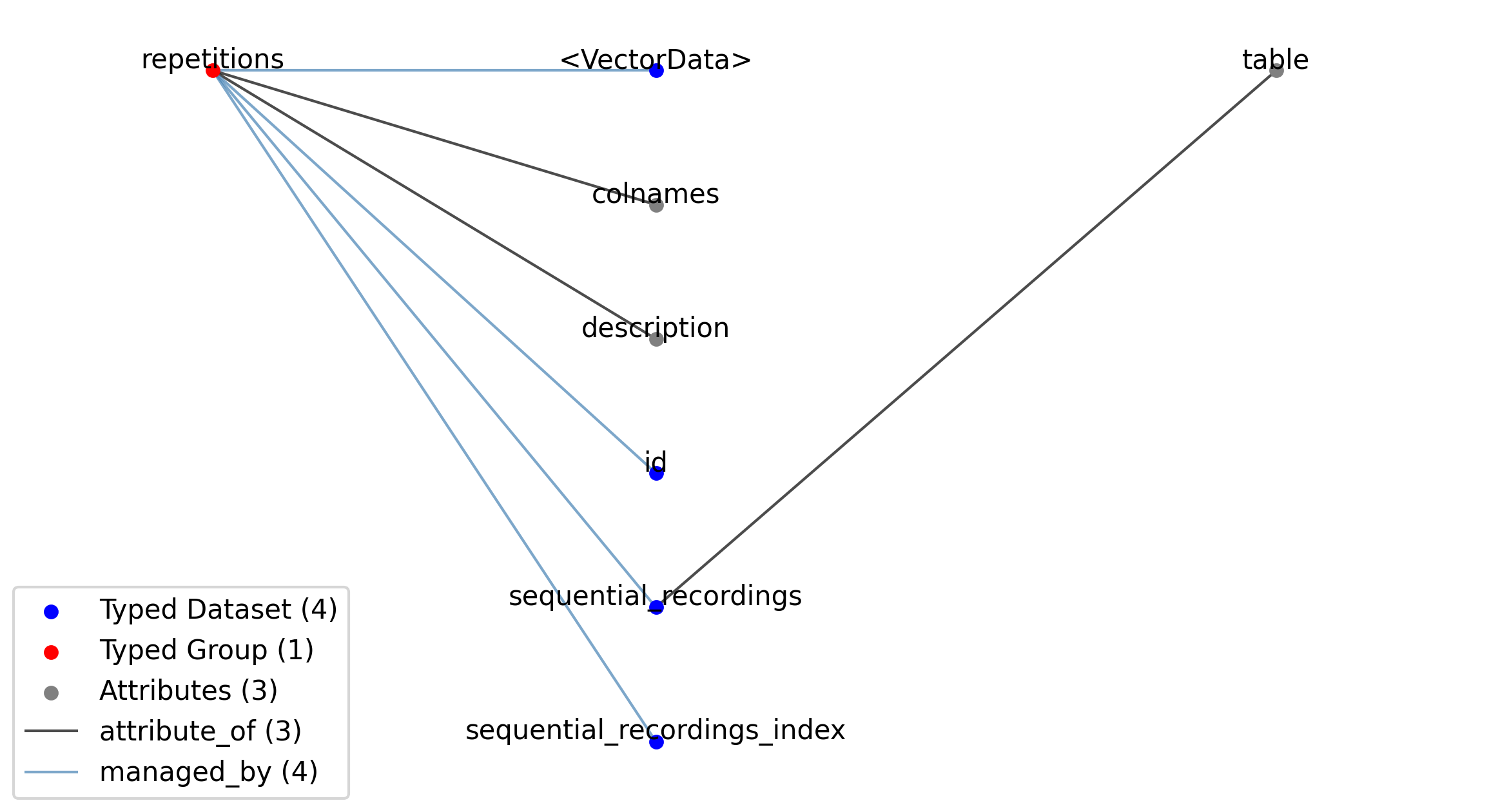
Id |
Type |
Description |
|---|---|---|
repetitions |
Group |
Top level Group for repetitions
|
—sequential_recordings |
Dataset |
A reference to one or more rows in the SequentialRecordingsTable table.
|
——table |
Attribute |
Reference to the SequentialRecordingsTable table that this table region applies to. This specializes the attribute inherited from DynamicTableRegion to fix the type of table that can be referenced here.
|
—sequential_recordings_index |
Dataset |
Index dataset for the sequential_recordings column.
|
2.10.16. ExperimentalConditionsTable
Overview: A table for grouping different intracellular recording repetitions together that belong to the same experimental condition.
ExperimentalConditionsTable extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Name: experimental_conditions
Inherits from: DynamicTable, Container
Source filename: nwb.icephys.yaml
Source Specification: see Section 3.11.16
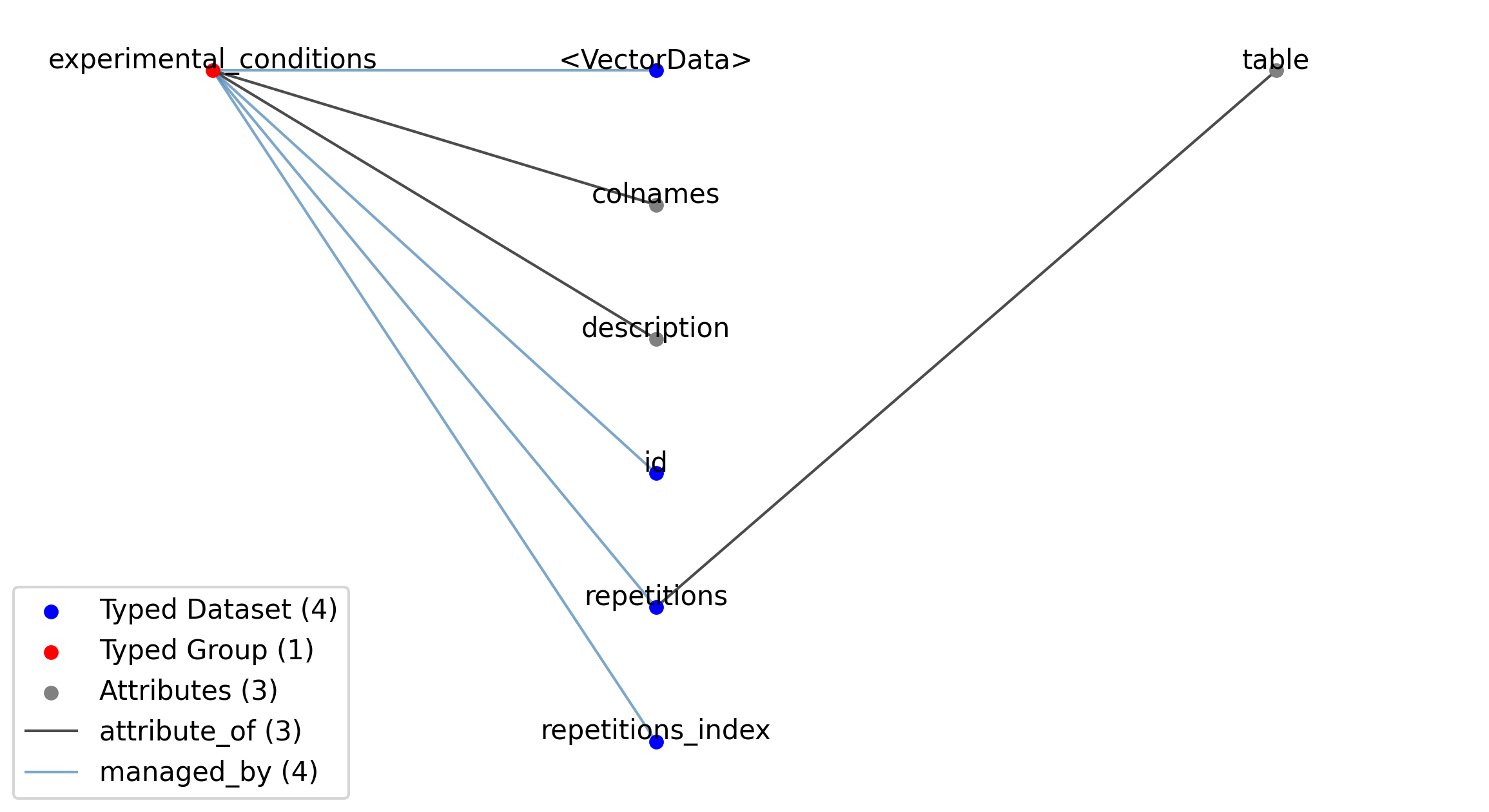
Id |
Type |
Description |
|---|---|---|
experimental_conditions |
Group |
Top level Group for experimental_conditions
|
—repetitions |
Dataset |
A reference to one or more rows in the RepetitionsTable table.
|
——table |
Attribute |
Reference to the RepetitionsTable table that this table region applies to. This specializes the attribute inherited from DynamicTableRegion to fix the type of table that can be referenced here.
|
—repetitions_index |
Dataset |
Index dataset for the repetitions column.
|
2.11. Optogenetics
This source module contains neurodata_types for optogenetics data.
2.11.1. OptogeneticSeries
Overview: An optogenetic stimulus.
OptogeneticSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.ogen.yaml
Source Specification: see Section 3.12.1
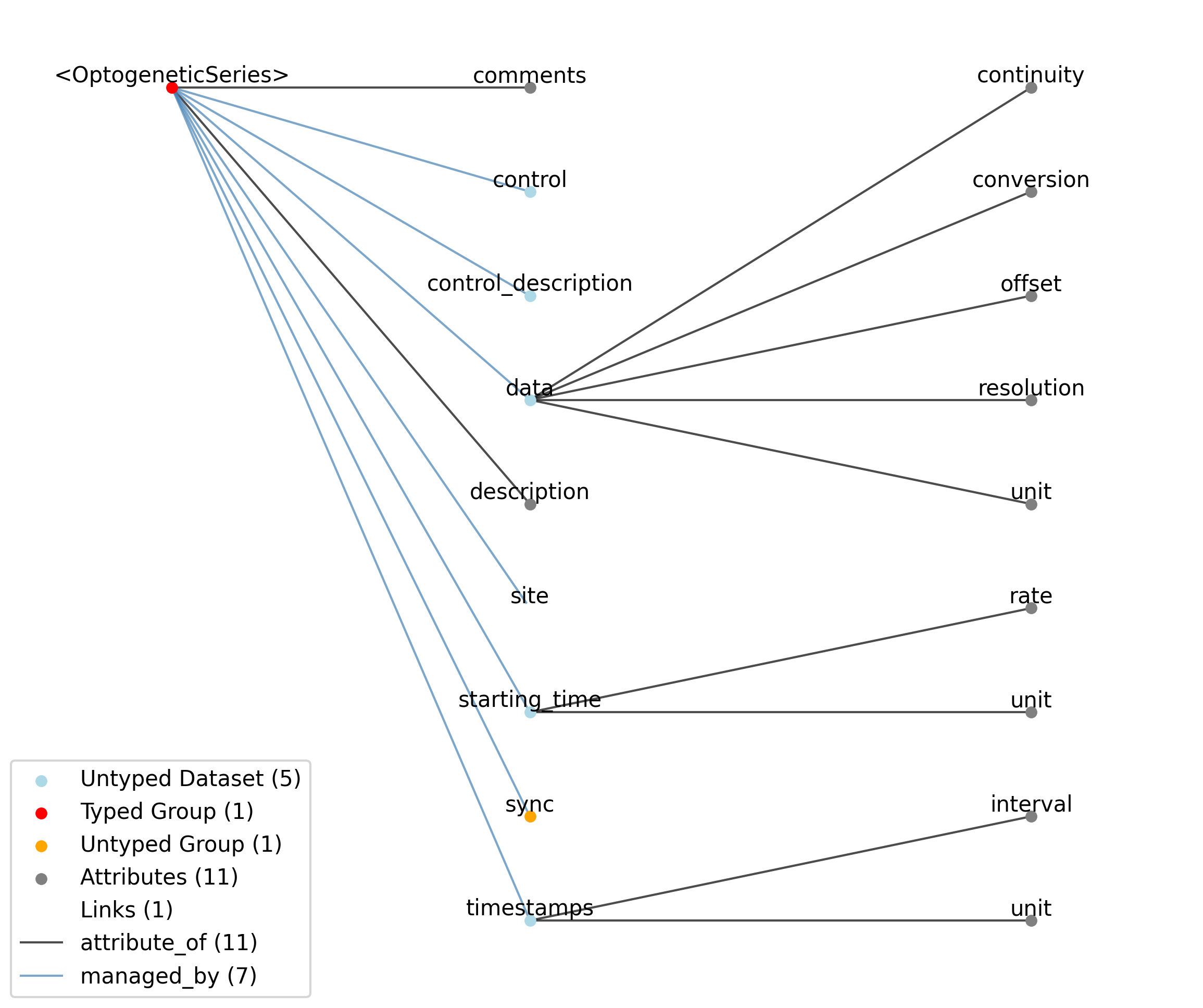
Id |
Type |
Description |
|---|---|---|
<OptogeneticSeries> |
Group |
Top level Group for <OptogeneticSeries>
|
—data |
Dataset |
Applied power for optogenetic stimulus, in watts. Shape can be 1-D or 2-D. 2-D data is meant to be used in an extension of OptogeneticSeries that defines what the second dimension represents.
|
——unit |
Attribute |
Unit of measurement for data, which is fixed to ‘watts’.
|
—site |
Link |
Link to OptogeneticStimulusSite object that describes the site to which this stimulus was applied.
|
Id |
Type |
Description |
|---|---|---|
<OptogeneticSeries> |
Group |
Top level Group for <OptogeneticSeries>
|
—site |
Link |
Link to OptogeneticStimulusSite object that describes the site to which this stimulus was applied.
|
2.11.2. OptogeneticStimulusSite
Overview: A site of optogenetic stimulation.
OptogeneticStimulusSite extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.ogen.yaml
Source Specification: see Section 3.12.2
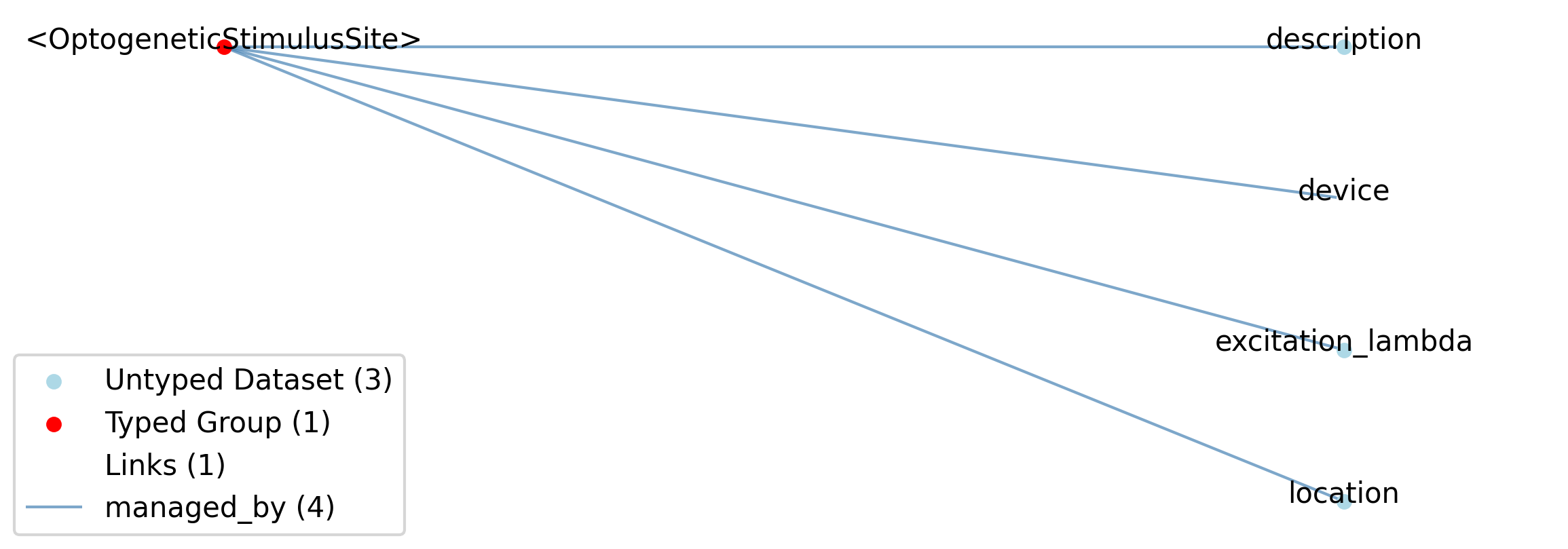
Id |
Type |
Description |
|---|---|---|
<OptogeneticStimulusSite> |
Group |
Top level Group for <OptogeneticStimulusSite>
|
—description |
Dataset |
Description of stimulation site.
|
—excitation_lambda |
Dataset |
Excitation wavelength, in nm.
|
—location |
Dataset |
Location of the stimulation site. Specify the area, layer, comments on estimation of area/layer, stereotaxic coordinates if in vivo, etc. Use standard atlas names for anatomical regions when possible.
|
—device |
Link |
Device that generated the stimulus.
|
Id |
Type |
Description |
|---|---|---|
<OptogeneticStimulusSite> |
Group |
Top level Group for <OptogeneticStimulusSite>
|
—device |
Link |
Device that generated the stimulus.
|
2.12. Optical physiology
This source module contains neurodata_types for optical physiology data.
2.12.1. OnePhotonSeries
Overview: Image stack recorded over time from 1-photon microscope.
OnePhotonSeries extends ImageSeries and includes all elements of ImageSeries with the following additions or changes.
Extends: ImageSeries
Primitive Type: Group
Inherits from: ImageSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.1
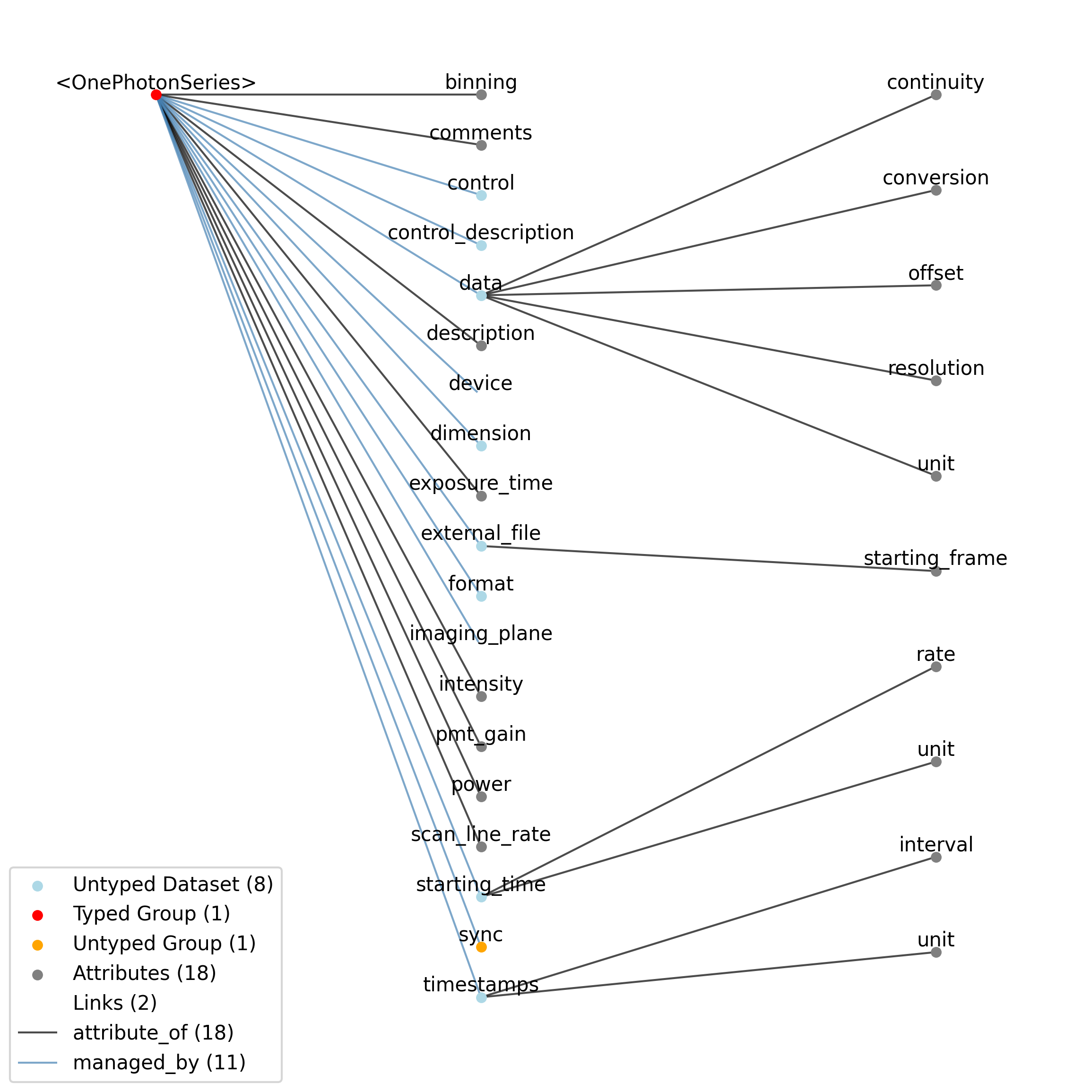
Id |
Type |
Description |
|---|---|---|
<OnePhotonSeries> |
Group |
Top level Group for <OnePhotonSeries>
|
—pmt_gain |
Attribute |
Photomultiplier gain.
|
—scan_line_rate |
Attribute |
Lines imaged per second. This is also stored in /general/optophysiology but is kept here as it is useful information for analysis, and is therefore stored with the actual data.
|
—exposure_time |
Attribute |
Exposure time of the sample; often the inverse of the frequency.
|
—binning |
Attribute |
Amount of pixels combined into ‘bins’; could be 1, 2, 4, 8, etc.
|
—power |
Attribute |
Power of the excitation in mW, if known.
|
—intensity |
Attribute |
Intensity of the excitation in mW/mm^2, if known.
|
—data |
Dataset |
Time-series of microscopy data indexed as data[time, width, height].
Coordinate system diagram: height ^
(slow) |
| +-----------------+
| | |
| | Image plane |
| | |
| +-----------------+
|
0 ----------------------> width (fast)
For non-raster systems (wide-field, light-sheet, random-access), width and height are arbitrary coordinates of the image plane. Note: This indexing convention conflicts with standard matrix[row, column] notation for array access where the first index moves vertically through rows and the second moves horizontally through columns. In the schema, data[time, width, height] means that the first spatial index moves horizontally (width) through columns and the second spatial index moves vertically (height) through rows. In summary, incrementing the first spatial index moves you horizontally across the image, while in matrix notation it would move you vertically across the rows of the image.
|
—imaging_plane |
Link |
Link to ImagingPlane object from which this TimeSeries data was generated.
|
Id |
Type |
Description |
|---|---|---|
<OnePhotonSeries> |
Group |
Top level Group for <OnePhotonSeries>
|
—imaging_plane |
Link |
Link to ImagingPlane object from which this TimeSeries data was generated.
|
2.12.2. TwoPhotonSeries
Overview: Image stack recorded over time from 2-photon microscope.
TwoPhotonSeries extends ImageSeries and includes all elements of ImageSeries with the following additions or changes.
Extends: ImageSeries
Primitive Type: Group
Inherits from: ImageSeries, TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.2
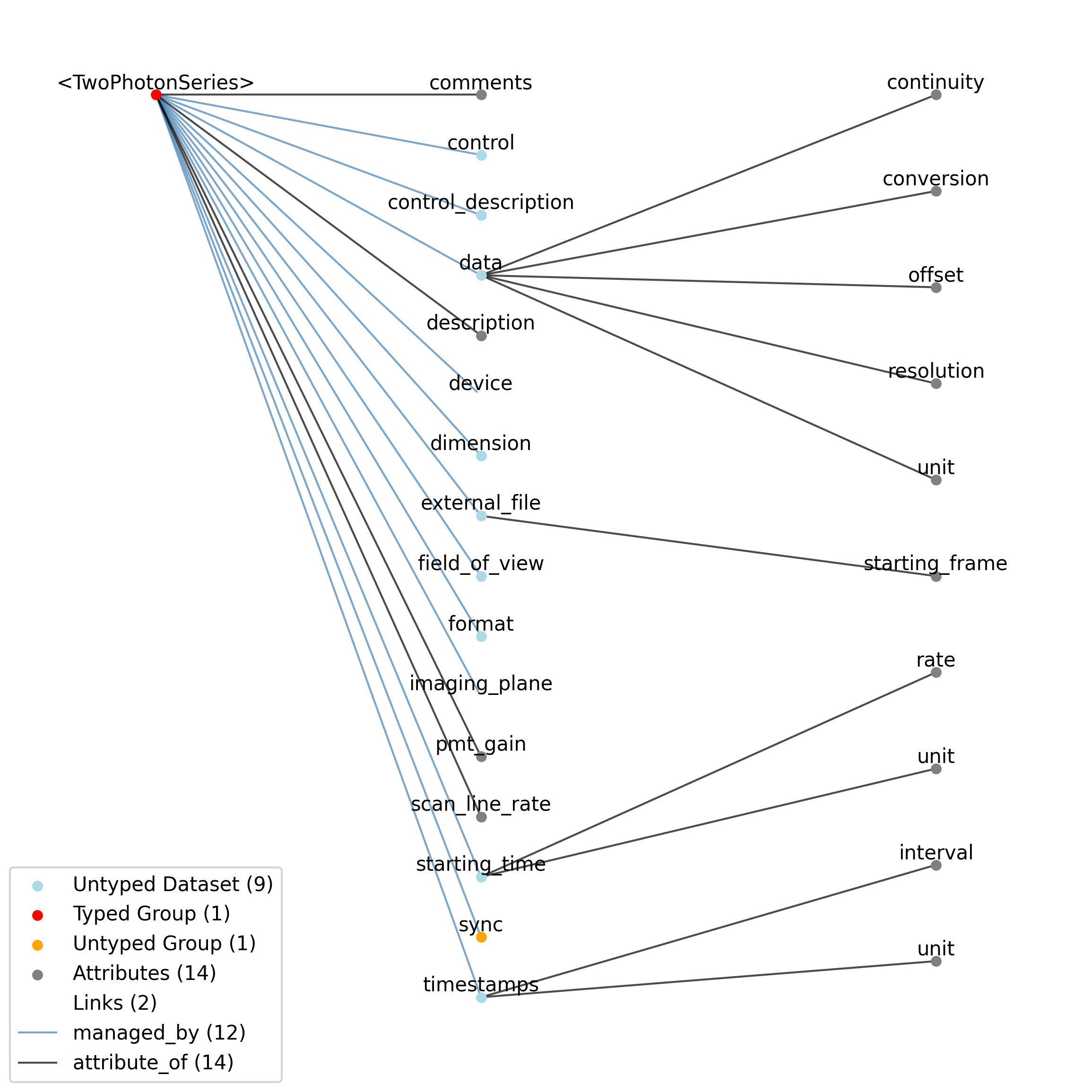
Id |
Type |
Description |
|---|---|---|
<TwoPhotonSeries> |
Group |
Top level Group for <TwoPhotonSeries>
|
—pmt_gain |
Attribute |
Photomultiplier gain.
|
—scan_line_rate |
Attribute |
Lines imaged per second. This is also stored in /general/optophysiology but is kept here as it is useful information for analysis, and is therefore stored with the actual data.
|
—data |
Dataset |
Time-series of microscopy data indexed as data[time, width, height].
Coordinate system diagram: height ^
(slow) |
| +-----------------+
| | |
| | Image plane |
| | |
| +-----------------+
|
0 ----------------------> width (fast)
For non-raster systems (wide-field, light-sheet, random-access), width and height are arbitrary coordinates of the image plane. Note: This indexing convention conflicts with standard matrix[row, column] notation for array access where the first index moves vertically through rows and the second moves horizontally through columns. In the schema, data[time, width, height] means that the first spatial index moves horizontally (width) through columns and the second spatial index moves vertically (height) through rows.
|
—field_of_view |
Dataset |
Physical dimensions of the imaging field of view in width, height, and optionally depth directions, in meters. The width dimension corresponds to the faster scanning axis, and the height dimension corresponds to the slower scanning axis.
|
—imaging_plane |
Link |
Link to ImagingPlane object from which this TimeSeries data was generated.
|
Id |
Type |
Description |
|---|---|---|
<TwoPhotonSeries> |
Group |
Top level Group for <TwoPhotonSeries>
|
—imaging_plane |
Link |
Link to ImagingPlane object from which this TimeSeries data was generated.
|
2.12.3. RoiResponseSeries
Overview: ROI responses over an imaging plane. The first dimension represents time. The second dimension, if present, represents ROIs.
RoiResponseSeries extends TimeSeries and includes all elements of TimeSeries with the following additions or changes.
Extends: TimeSeries
Primitive Type: Group
Inherits from: TimeSeries, NWBDataInterface, NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.3
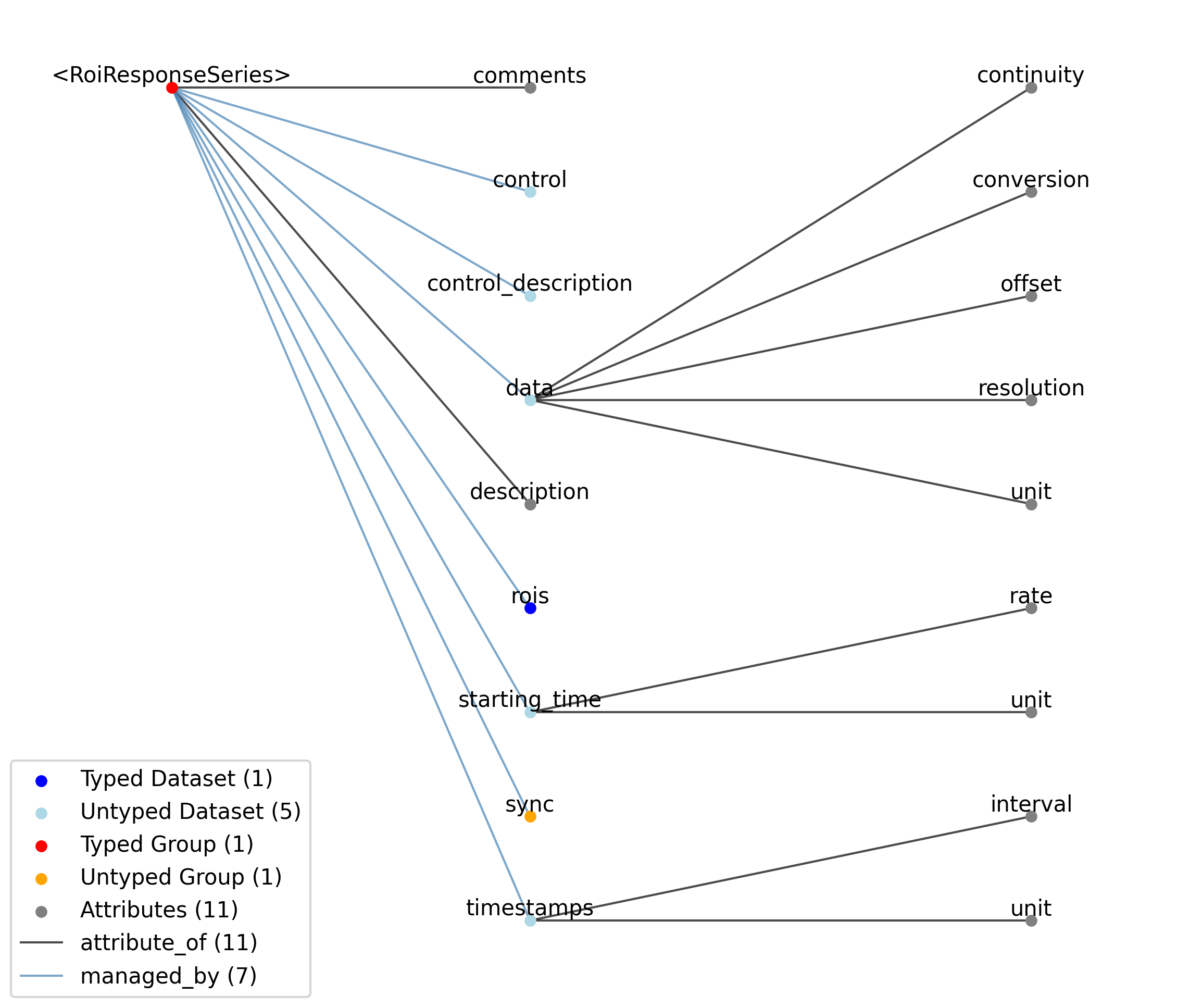
Id |
Type |
Description |
|---|---|---|
<RoiResponseSeries> |
Group |
Top level Group for <RoiResponseSeries>
|
—data |
Dataset |
Signals from ROIs.
|
—rois |
Dataset |
DynamicTableRegion referencing into a PlaneSegmentation table containing information on the ROIs stored in this TimeSeries.
|
2.12.4. DfOverF
Overview: dF/F information about a region of interest (ROI). Storage hierarchy of dF/F should be the same as for segmentation (i.e., same names for ROIs and for image planes).
DfOverF extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: DfOverF
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.4
Id |
Type |
Description |
|---|---|---|
<DfOverF> |
Group |
Top level Group for <DfOverF>
|
Group |
RoiResponseSeries object(s) containing dF/F for a ROI.
|
2.12.4.1. Groups: <RoiResponseSeries>
RoiResponseSeries object(s) containing dF/F for a ROI.
Extends: RoiResponseSeries
Quantity: 1 or more
2.12.5. Fluorescence
Overview: Fluorescence information about a region of interest (ROI). Storage hierarchy of fluorescence should be the same as for segmentation (i.e., same names for ROIs and for image planes).
Fluorescence extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: Fluorescence
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.5
Id |
Type |
Description |
|---|---|---|
<Fluorescence> |
Group |
Top level Group for <Fluorescence>
|
Group |
RoiResponseSeries object(s) containing fluorescence data for a ROI.
|
2.12.5.1. Groups: <RoiResponseSeries>
RoiResponseSeries object(s) containing fluorescence data for a ROI.
Extends: RoiResponseSeries
Quantity: 1 or more
2.12.6. ImageSegmentation
Overview: Stores pixels in an image that represent different regions of interest (ROIs) or masks. All segmentation for a given imaging plane is stored together, with storage for multiple imaging planes (masks) supported. Each ROI is stored in its own subgroup, with the ROI group containing both a 2-D mask and a list of pixels that make up this mask. Segments can also be used for masking neuropil. If segmentation is allowed to change with time, a new imaging plane (or module) is required and ROI names should remain consistent between them.
ImageSegmentation extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: ImageSegmentation
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.6
Id |
Type |
Description |
|---|---|---|
<ImageSegmentation> |
Group |
Top level Group for <ImageSegmentation>
|
Group |
Results from image segmentation of a specific imaging plane.
|
2.12.6.1. Groups: <PlaneSegmentation>
Results from image segmentation of a specific imaging plane.
Extends: PlaneSegmentation
Quantity: 1 or more
2.12.7. PlaneSegmentation
Overview: Results from image segmentation of a specific imaging plane. At least one of image_mask, pixel_mask, or voxel_mask is required.
PlaneSegmentation extends DynamicTable and includes all elements of DynamicTable with the following additions or changes.
Extends: DynamicTable
Primitive Type: Group
Inherits from: DynamicTable, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.7
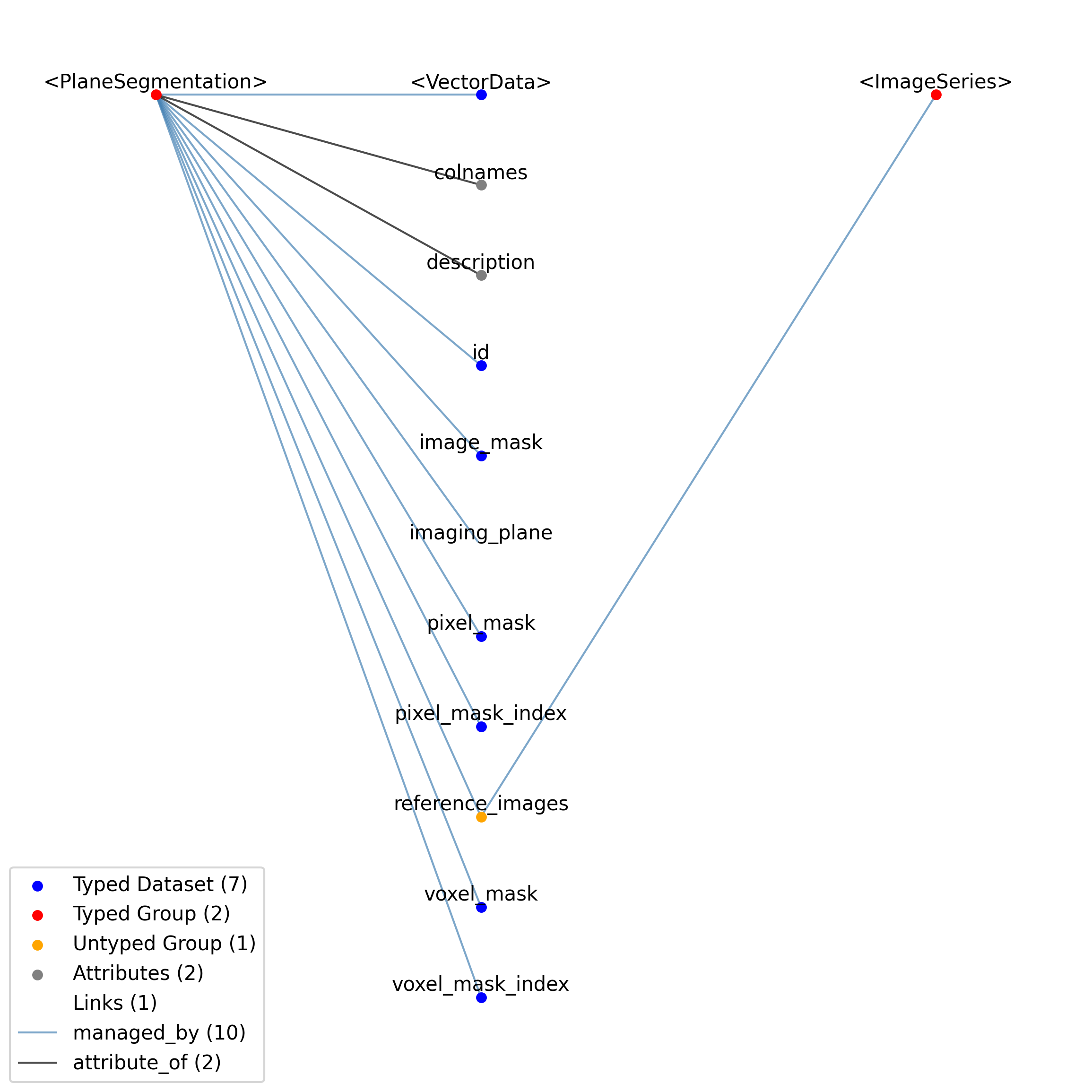
Id |
Type |
Description |
|---|---|---|
<PlaneSegmentation> |
Group |
Top level Group for <PlaneSegmentation>
|
—image_mask |
Dataset |
ROI masks for each ROI. Each image mask is the size of the original imaging plane (or volume) and members of the ROI are finite non-zero. At least one of image_mask, pixel_mask, or voxel_mask is required.
|
—pixel_mask_index |
Dataset |
Index into pixel_mask.
|
—pixel_mask |
Dataset |
Pixel masks for each ROI: a list of indices and weights for the ROI. Pixel masks are concatenated and parsing of this dataset is maintained by the PlaneSegmentation. At least one of image_mask, pixel_mask, or voxel_mask is required.
|
—voxel_mask_index |
Dataset |
Index into voxel_mask.
|
—voxel_mask |
Dataset |
Voxel masks for each ROI: a list of indices and weights for the ROI. Voxel masks are concatenated and parsing of this dataset is maintained by the PlaneSegmentation. At least one of image_mask, pixel_mask, or voxel_mask is required.
|
—imaging_plane |
Link |
Link to ImagingPlane object from which this data was generated.
|
Id |
Type |
Description |
|---|---|---|
<PlaneSegmentation> |
Group |
Top level Group for <PlaneSegmentation>
|
—imaging_plane |
Link |
Link to ImagingPlane object from which this data was generated.
|
—reference_images |
Group |
Image stacks that the segmentation masks apply to.
|
2.12.7.1. Groups: reference_images
Image stacks that the segmentation masks apply to.
Name: reference_images
Id |
Type |
Description |
|---|---|---|
reference_images |
Group |
Top level Group for reference_images
|
—<ImageSeries> |
Group |
One or more image stacks that the masks apply to (can be one-element stack).
|
2.12.7.2. Groups: reference_images/<ImageSeries>
One or more image stacks that the masks apply to (can be one-element stack).
Extends: ImageSeries
Quantity: 0 or more
2.12.8. ImagingPlane
Overview: An imaging plane and its metadata.
ImagingPlane extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.8
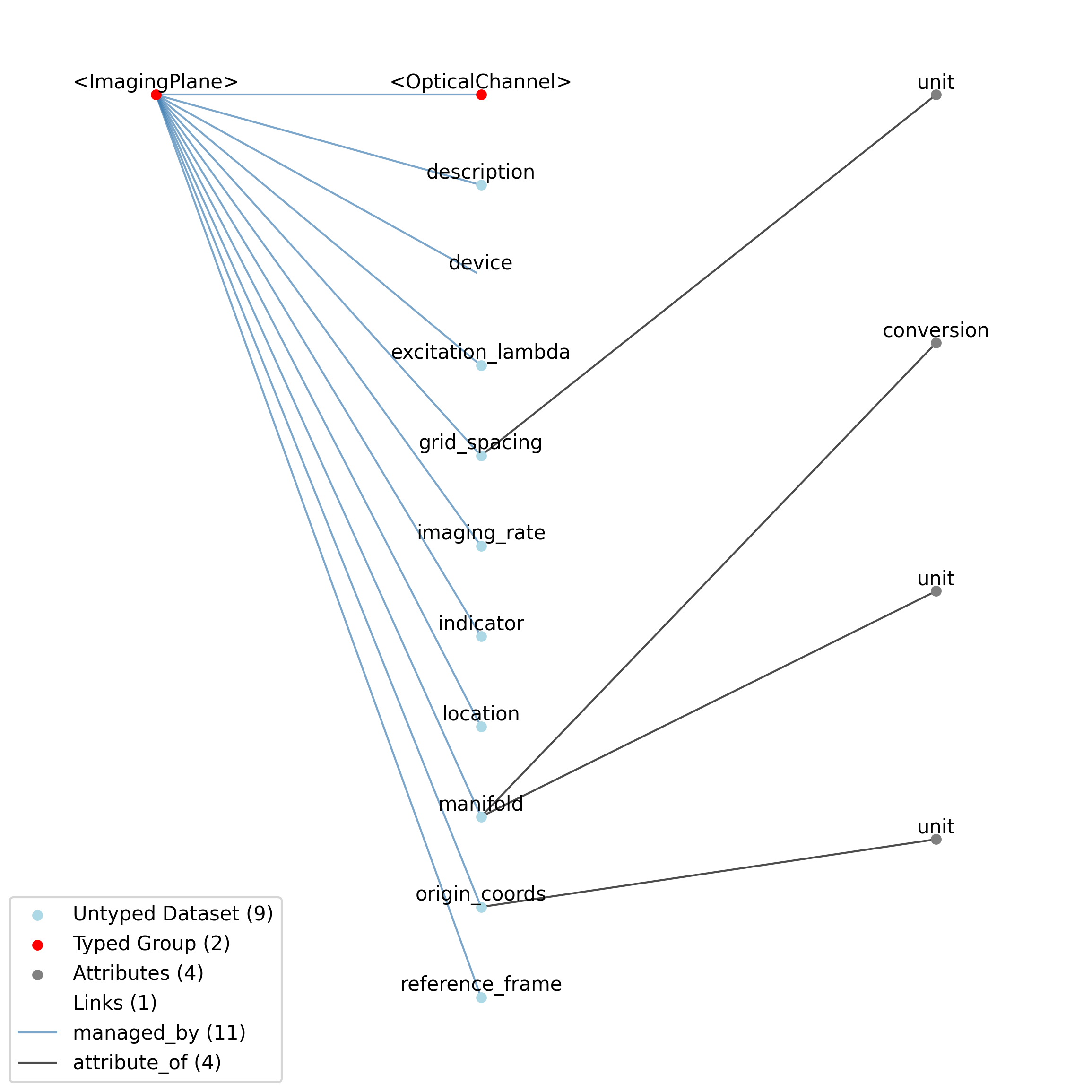
Id |
Type |
Description |
|---|---|---|
<ImagingPlane> |
Group |
Top level Group for <ImagingPlane>
|
—description |
Dataset |
Description of the imaging plane.
|
—excitation_lambda |
Dataset |
Excitation wavelength, in nm.
|
—imaging_rate |
Dataset |
Rate that images are acquired, in Hz. If the corresponding TimeSeries is present, the rate should be stored there instead.
|
—indicator |
Dataset |
Calcium indicator.
|
—location |
Dataset |
Location of the imaging plane. Specify the area, layer, comments on estimation of area/layer, stereotaxic coordinates if in vivo, etc. Use standard atlas names for anatomical regions when possible.
|
—manifold |
Dataset |
DEPRECATED. Physical position of each pixel. ‘xyz’ represents the position of the pixel relative to the defined coordinate space. Deprecated in favor of origin_coords and grid_spacing.
|
——conversion |
Attribute |
Scalar to multiply each element in data to convert it to the specified ‘unit’. If the data are stored in acquisition system units or other units that require a conversion to be interpretable, multiply the data by ‘conversion’ to convert the data to the specified ‘unit’. For example, if the data acquisition system stores values in this object as pixels from x = -500 to 499, y = -500 to 499 that correspond to a 2 m x 2 m range, then the ‘conversion’ multiplier to get from raw data acquisition pixel units to meters is 2/1000.
|
——unit |
Attribute |
Base unit of measurement for working with the data. The default value is ‘meters’.
|
—origin_coords |
Dataset |
Physical location of the first element of the imaging plane (0, 0) for 2-D data or (0, 0, 0) for 3-D data. See also reference_frame for what the physical location is relative to (e.g., bregma).
|
——unit |
Attribute |
Measurement units for origin_coords. The default value is ‘meters’.
|
—grid_spacing |
Dataset |
Space between pixels in (x, y) or voxels in (x, y, z) directions, in the specified unit. Assumes imaging plane is a regular grid. See also reference_frame to interpret the grid.
|
——unit |
Attribute |
Measurement units for grid_spacing. The default value is ‘meters’.
|
—reference_frame |
Dataset |
Describes reference frame of origin_coords and grid_spacing. For example, this can be a text description of the anatomical location and orientation of the grid defined by origin_coords and grid_spacing or the vectors needed to transform or rotate the grid to a common anatomical axis (e.g., AP/DV/ML). This field is necessary to interpret origin_coords and grid_spacing. If origin_coords and grid_spacing are not present, then this field is not required. For example, if the microscope takes 10 x 10 x 2 images, where the first value of the data matrix (index (0, 0, 0)) corresponds to (-1.2, -0.6, -2) mm relative to bregma, the spacing between pixels is 0.2 mm in x, 0.2 mm in y and 0.5 mm in z, and larger numbers in x mean more anterior, larger numbers in y mean more rightward, and larger numbers in z mean more ventral, then enter the following – origin_coords = (-1.2, -0.6, -2) grid_spacing = (0.2, 0.2, 0.5) reference_frame = “Origin coordinates are relative to bregma. First dimension corresponds to anterior-posterior axis (larger index = more anterior). Second dimension corresponds to medial-lateral axis (larger index = more rightward). Third dimension corresponds to dorsal-ventral axis (larger index = more ventral).”
|
—device |
Link |
Link to the Device object (e.g., microscope) used to acquire images from this imaging plane.
|
Id |
Type |
Description |
|---|---|---|
<ImagingPlane> |
Group |
Top level Group for <ImagingPlane>
|
—device |
Link |
Link to the Device object (e.g., microscope) used to acquire images from this imaging plane.
|
Group |
An optical channel used to record from an imaging plane.
|
2.12.8.1. Groups: <OpticalChannel>
An optical channel used to record from an imaging plane.
Extends: OpticalChannel
Quantity: 1 or more
2.12.9. OpticalChannel
Overview: An optical channel used to record from an imaging plane.
OpticalChannel extends NWBContainer and includes all elements of NWBContainer with the following additions or changes.
Extends: NWBContainer
Primitive Type: Group
Inherits from: NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.9

Id |
Type |
Description |
|---|---|---|
<OpticalChannel> |
Group |
Top level Group for <OpticalChannel>
|
—description |
Dataset |
Description or other notes about the channel.
|
—emission_lambda |
Dataset |
Emission wavelength for channel, in nm.
|
2.12.10. MotionCorrection
Overview: An image stack where all frames are shifted (registered) to a common coordinate system, to account for movement and drift between frames. Note: each frame at each point in time is assumed to be 2-D (has only x and y dimensions).
MotionCorrection extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: MotionCorrection
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.10
Id |
Type |
Description |
|---|---|---|
<MotionCorrection> |
Group |
Top level Group for <MotionCorrection>
|
Group |
Results from motion correction of an image stack.
|
2.12.10.1. Groups: <CorrectedImageStack>
Results from motion correction of an image stack.
Extends: CorrectedImageStack
Quantity: 1 or more
2.12.11. CorrectedImageStack
Overview: Results from motion correction of an image stack.
CorrectedImageStack extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.ophys.yaml
Source Specification: see Section 3.13.11
Id |
Type |
Description |
|---|---|---|
<CorrectedImageStack> |
Group |
Top level Group for <CorrectedImageStack>
|
—original |
Link |
Link to ImageSeries object that is being registered.
|
Id |
Type |
Description |
|---|---|---|
<CorrectedImageStack> |
Group |
Top level Group for <CorrectedImageStack>
|
—original |
Link |
Link to ImageSeries object that is being registered.
|
—corrected |
Group |
Image stack with frames shifted to the common coordinates.
|
—xy_translation |
Group |
Stores the x,y delta necessary to align each frame to the common coordinates, for example, to align each frame to a reference image.
|
2.12.11.1. Groups: corrected
Image stack with frames shifted to the common coordinates.
Extends: ImageSeries
Name: corrected
2.12.11.2. Groups: xy_translation
Stores the x,y delta necessary to align each frame to the common coordinates, for example, to align each frame to a reference image.
Extends: TimeSeries
Name: xy_translation
2.13. Retinotopy
This source module contains neurodata_type for retinotopy data.
2.13.1. ImagingRetinotopy
Overview: DEPRECATED. Intrinsic signal optical imaging or widefield imaging for measuring retinotopy. Stores orthogonal maps (e.g., altitude/azimuth; radius/theta) of responses to specific stimuli and a combined polarity map from which to identify visual areas. This group does not store the raw responses imaged during retinotopic mapping or the stimuli presented, but rather the resulting phase and power maps after applying a Fourier transform on the averaged responses. Note: for data consistency, all images and arrays are stored in the format [row][column] and [row, col], which equates to [y][x]. Field of view and dimension arrays may appear backward (i.e., y before x).
ImagingRetinotopy extends NWBDataInterface and includes all elements of NWBDataInterface with the following additions or changes.
Extends: NWBDataInterface
Primitive Type: Group
Default Name: ImagingRetinotopy
Inherits from: NWBDataInterface, NWBContainer, Container
Source filename: nwb.retinotopy.yaml
Source Specification: see Section 3.14.1
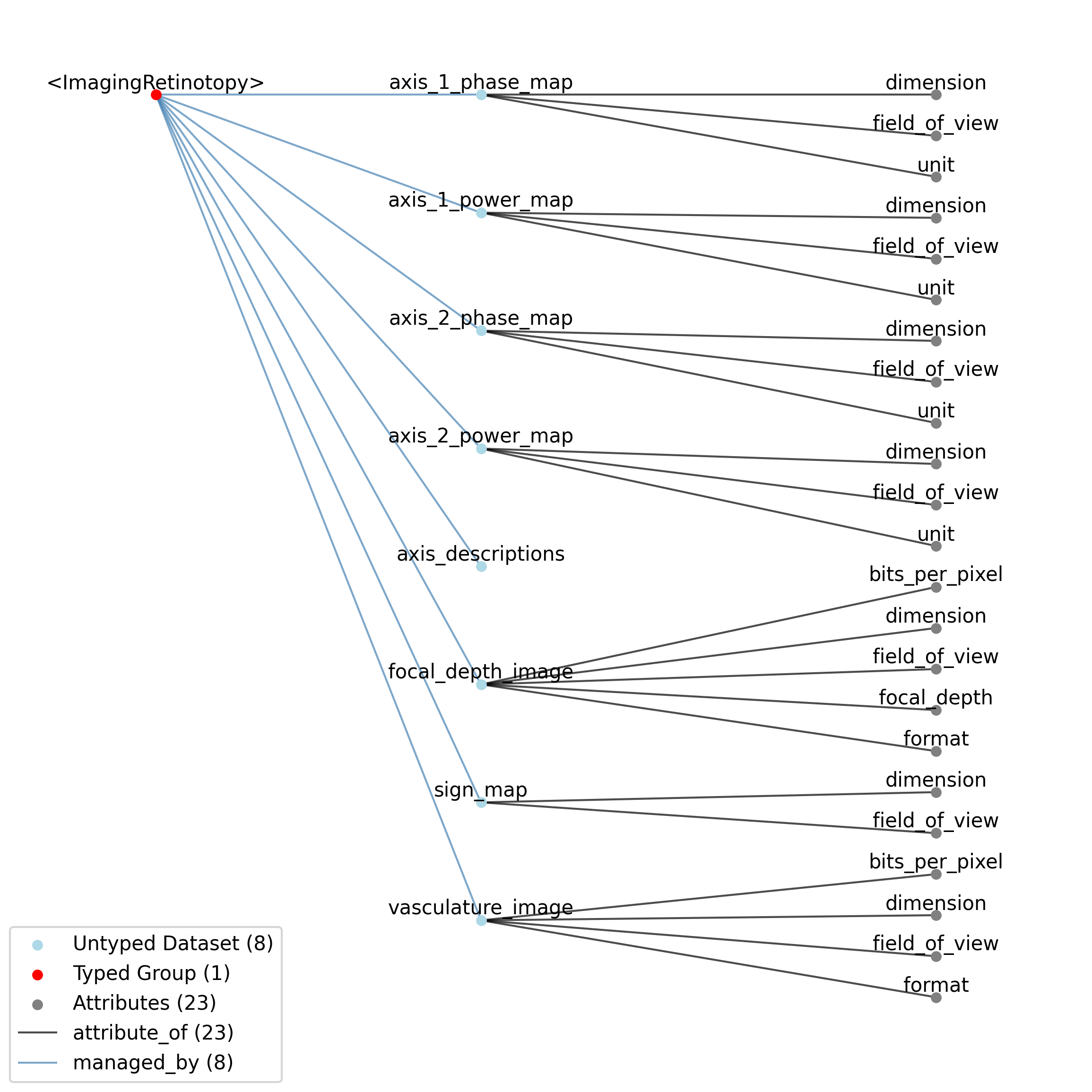
Id |
Type |
Description |
|---|---|---|
<ImagingRetinotopy> |
Group |
Top level Group for <ImagingRetinotopy>
|
—axis_1_phase_map |
Dataset |
Phase response to stimulus on the first measured axis.
|
——dimension |
Attribute |
Number of rows and columns in the image.
|
——field_of_view |
Attribute |
Size of viewing area, in meters.
|
——unit |
Attribute |
Unit that axis data is stored in (e.g., degrees).
|
—axis_1_power_map |
Dataset |
Power response on the first measured axis. Response is scaled so 0.0 is no power in the response and 1.0 is maximum relative power.
|
——dimension |
Attribute |
Number of rows and columns in the image.
|
——field_of_view |
Attribute |
Size of viewing area, in meters.
|
——unit |
Attribute |
Unit that axis data is stored in (e.g., degrees).
|
—axis_2_phase_map |
Dataset |
Phase response to stimulus on the second measured axis.
|
——dimension |
Attribute |
Number of rows and columns in the image.
|
——field_of_view |
Attribute |
Size of viewing area, in meters.
|
——unit |
Attribute |
Unit that axis data is stored in (e.g., degrees).
|
—axis_2_power_map |
Dataset |
Power response on the second measured axis. Response is scaled so 0.0 is no power in the response and 1.0 is maximum relative power.
|
——dimension |
Attribute |
Number of rows and columns in the image.
|
——field_of_view |
Attribute |
Size of viewing area, in meters.
|
——unit |
Attribute |
Unit that axis data is stored in (e.g., degrees).
|
—axis_descriptions |
Dataset |
Two-element array describing the contents of the two response axis fields. Description should be something like [‘altitude’, ‘azimuth’] or [‘radius’, ‘theta’].
|
—focal_depth_image |
Dataset |
Gray-scale image taken with the same settings/parameters (e.g., focal depth, wavelength) as data collection. Array format: [rows][columns].
|
——bits_per_pixel |
Attribute |
Number of bits used to represent each value. This is necessary to determine maximum (white) pixel value.
|
——dimension |
Attribute |
Number of rows and columns in the image.
|
——field_of_view |
Attribute |
Size of viewing area, in meters.
|
——focal_depth |
Attribute |
Focal depth offset, in meters.
|
——format |
Attribute |
Format of image. Currently only ‘raw’ is supported.
|
—sign_map |
Dataset |
Sine of the angle between the direction of the gradient in axis_1 and axis_2.
|
——dimension |
Attribute |
Number of rows and columns in the image.
|
——field_of_view |
Attribute |
Size of viewing area, in meters.
|
—vasculature_image |
Dataset |
Gray-scale anatomical image of cortical surface. Array structure: [rows][columns]
|
——bits_per_pixel |
Attribute |
Number of bits used to represent each value. This is necessary to determine maximum (white) pixel value.
|
——dimension |
Attribute |
Number of rows and columns in the image.
|
——field_of_view |
Attribute |
Size of viewing area, in meters.
|
——format |
Attribute |
Format of image. Currently only ‘raw’ is supported.
|
3. Schema Sources
Source Specification: see Section 3.1
3.1. Namespace – NWB core
Description: see Section 1.1
YAML Specification:
1name: core
2doc: NWB namespace
3schema:
4- namespace: hdmf-common
5- doc: This source module contains base data types used throughout the NWB data
6 format.
7 source: nwb.base.yaml
8 title: Base data types
9- doc: This source module contains neurodata_types for device data.
10 source: nwb.device.yaml
11 title: Devices
12- doc: This source module contains neurodata_types for epoch data.
13 source: nwb.epoch.yaml
14 title: Epochs
15- doc: This source module contains neurodata_types for event data.
16 source: nwb.event.yaml
17 title: Events
18- doc: This source module contains neurodata_types for image data.
19 source: nwb.image.yaml
20 title: Image data
21- doc: Main NWB file specification.
22 source: nwb.file.yaml
23 title: NWB file
24- doc: Miscellaneous types.
25 source: nwb.misc.yaml
26 title: Miscellaneous neurodata_types.
27- doc: This source module contains neurodata_types for behavior data.
28 source: nwb.behavior.yaml
29 title: Behavior
30- doc: This source module contains neurodata_types for extracellular
31 electrophysiology data.
32 source: nwb.ecephys.yaml
33 title: Extracellular electrophysiology
34- doc: This source module contains neurodata_types for intracellular
35 electrophysiology data.
36 source: nwb.icephys.yaml
37 title: Intracellular electrophysiology
38- doc: This source module contains neurodata_types for optogenetics data.
39 source: nwb.ogen.yaml
40 title: Optogenetics
41- doc: This source module contains neurodata_types for optical physiology data.
42 source: nwb.ophys.yaml
43 title: Optical physiology
44- doc: This source module contains neurodata_type for retinotopy data.
45 source: nwb.retinotopy.yaml
46 title: Retinotopy
47full_name: NWB core
48version: 2.10.1-alpha
49author:
50- Andrew Tritt
51- Oliver Ruebel
52- Ryan Ly
53- Ben Dichter
54- Keith Godfrey
55- Jeff Teeters
56contact:
57- ajtritt@lbl.gov
58- oruebel@lbl.gov
59- rly@lbl.gov
60- bdichter@lbl.gov
61- keithg@alleninstitute.org
62- jteeters@berkeley.edu
3.2. Base data types
This source module contains base data types used throughout the NWB data format.
3.2.1. NWBData
Extends: Data
Description: see Section 2.1.1
YAML Specification:
1neurodata_type_def: NWBData
2neurodata_type_inc: Data
3doc: An abstract data type for a dataset.
3.2.2. TimeSeriesReferenceVectorData
Extends: VectorData
Description: see Section 2.1.2
YAML Specification:
1neurodata_type_def: TimeSeriesReferenceVectorData
2neurodata_type_inc: VectorData
3default_name: timeseries
4dtype:
5- name: idx_start
6 dtype: int32
7 doc: Start index into the TimeSeries 'data' and 'timestamp' datasets of the
8 referenced TimeSeries. The first dimension of those arrays is always time.
9- name: count
10 dtype: int32
11 doc: Number of data samples available in this time series, during this epoch.
12- name: timeseries
13 dtype:
14 target_type: TimeSeries
15 reftype: object
16 doc: The TimeSeries object that this reference refers to.
17doc: Column storing references into one or more TimeSeries objects. Each row of
18 this column stores a start index and count into a referenced TimeSeries and an
19 object reference to that TimeSeries.
3.2.3. BaseImage
Extends: NWBData
Description: see Section 2.1.3
YAML Specification:
1neurodata_type_def: BaseImage
2neurodata_type_inc: NWBData
3doc: An abstract base type for image data. Parent type for Image and
4 ExternalImage types.
5attributes:
6- name: description
7 dtype: text
8 doc: Description of the image.
9 required: false
3.2.4. Image
Extends: BaseImage
Description: see Section 2.1.4
YAML Specification:
1neurodata_type_def: Image
2neurodata_type_inc: BaseImage
3dtype: numeric
4dims:
5- - x
6 - y
7- - x
8 - y
9 - r, g, b
10- - x
11 - y
12 - r, g, b, a
13shape:
14- - null
15 - null
16- - null
17 - null
18 - 3
19- - null
20 - null
21 - 4
22doc: A type for storing image data directly. Shape can be 2-D (x, y), or 3-D
23 where the third dimension can have three or four elements, e.g., (x, y, (r, g,
24 b)) or (x, y, (r, g, b, a)).
25attributes:
26- name: resolution
27 dtype: float32
28 doc: Pixel resolution of the image, in pixels per centimeter.
29 required: false
3.2.5. ExternalImage
Extends: BaseImage
Description: see Section 2.1.5
YAML Specification:
1neurodata_type_def: ExternalImage
2neurodata_type_inc: BaseImage
3dtype: text
4doc: A type for referencing an external image file. The single file path or URI
5 to the external image file should be stored in the dataset. This type should
6 NOT be used if the image is stored in another NWB file and that file is linked
7 to this file.
8attributes:
9- name: image_mode
10 dtype: text
11 doc: Image mode (color mode) of the image, e.g., "RGB", "RGBA", "grayscale",
12 and "LA".
13 required: false
14- name: image_format
15 dtype: text
16 doc: Common name of the image file format. Only widely readable, open file
17 formats are allowed. Allowed values are "PNG", "JPEG", and "GIF".
3.2.6. ImageReferences
Extends: NWBData
Description: see Section 2.1.6
YAML Specification:
1neurodata_type_def: ImageReferences
2neurodata_type_inc: NWBData
3dtype:
4 target_type: BaseImage
5 reftype: object
6dims:
7- num_images
8shape:
9- null
10doc: Ordered dataset of references to BaseImage (e.g., Image or ExternalImage)
11 objects.
3.2.7. NWBContainer
Extends: Container
Description: see Section 2.1.7
YAML Specification:
1neurodata_type_def: NWBContainer
2neurodata_type_inc: Container
3doc: An abstract data type for a generic container storing collections of data
4 and metadata. Base type for all data and metadata containers.
3.2.8. NWBDataInterface
Extends: NWBContainer
Description: see Section 2.1.8
YAML Specification:
1neurodata_type_def: NWBDataInterface
2neurodata_type_inc: NWBContainer
3doc: An abstract data type for a generic container storing collections of data,
4 as opposed to metadata.
3.2.9. TimeSeries
Extends: NWBDataInterface
Description: see Section 2.1.9
YAML Specification:
1neurodata_type_def: TimeSeries
2neurodata_type_inc: NWBDataInterface
3doc: General purpose time series.
4attributes:
5- name: description
6 dtype: text
7 default_value: no description
8 doc: Description of the time series.
9 required: false
10- name: comments
11 dtype: text
12 default_value: no comments
13 doc: Human-readable comments about the TimeSeries. This second descriptive
14 field can be used to store additional information, or descriptive
15 information if the primary description field is populated with a
16 computer-readable string.
17 required: false
18datasets:
19- name: data
20 dims:
21 - - num_times
22 - - num_times
23 - num_DIM2
24 - - num_times
25 - num_DIM2
26 - num_DIM3
27 - - num_times
28 - num_DIM2
29 - num_DIM3
30 - num_DIM4
31 shape:
32 - - null
33 - - null
34 - null
35 - - null
36 - null
37 - null
38 - - null
39 - null
40 - null
41 - null
42 doc: Data values. Data can be in 1-D, 2-D, 3-D, or 4-D. The first dimension
43 should always represent time. This can also be used to store binary data
44 (e.g., image frames). This can also be a link to data stored in an external
45 file.
46 attributes:
47 - name: conversion
48 dtype: float32
49 default_value: 1.0
50 doc: Scalar to multiply each element in data to convert it to the specified
51 'unit'. If the data are stored in acquisition system units or other units
52 that require a conversion to be interpretable, multiply the data by
53 'conversion' to convert the data to the specified 'unit'. For example, if
54 the data acquisition system stores values in this object as signed 16-bit
55 integers (int16 range -32,768 to 32,767) that correspond to a 5V range
56 (-2.5V to 2.5V), and the data acquisition system gain is 8000X, then the
57 'conversion' multiplier to get from raw data acquisition values to
58 recorded volts is 2.5/32768/8000 = 9.5367e-9.
59 required: false
60 - name: offset
61 dtype: float32
62 default_value: 0.0
63 doc: Scalar to add to the data after scaling by 'conversion' to finalize its
64 coercion to the specified 'unit'. Two common examples of this include (a)
65 data stored in an unsigned type that requires a shift after scaling to
66 re-center the data, and (b) specialized recording devices that naturally
67 cause a scalar offset with respect to the true units.
68 required: false
69 - name: resolution
70 dtype: float32
71 default_value: -1.0
72 doc: Smallest meaningful difference between values in data, stored in the
73 specified unit, e.g., the change in value of the least significant bit, or
74 a larger number if signal noise is known to be present. If unknown, use
75 -1.0.
76 required: false
77 - name: unit
78 dtype: text
79 doc: Base unit of measurement for working with the data. Actual stored
80 values are not necessarily stored in these units. To access the data in
81 these units, multiply 'data' by 'conversion' and add 'offset'.
82 - name: continuity
83 dtype: text
84 doc: Optionally describe the continuity of the data. Can be "continuous",
85 "instantaneous", or "step". For example, a voltage trace would be
86 "continuous", because samples are recorded from a continuous process. An
87 array of lick times would be "instantaneous", because the data represents
88 distinct moments in time. Times of image presentations would be "step"
89 because the picture remains the same until the next timepoint. This field
90 is optional, but is useful in providing information about the underlying
91 data. It may inform the way this data is interpreted, the way it is
92 visualized, and what analysis methods are applicable. For storing
93 instantaneous event information, it is recommended to use an EventsTable
94 instead of a TimeSeries with continuity set to "instantaneous".
95 required: false
96- name: starting_time
97 dtype: float64
98 doc: Timestamp of the first sample in seconds. When timestamps are uniformly
99 spaced, the timestamp of the first sample can be specified and all
100 subsequent ones calculated from the sampling rate attribute.
101 quantity: '?'
102 attributes:
103 - name: rate
104 dtype: float32
105 doc: Sampling rate, in Hz.
106 - name: unit
107 dtype: text
108 value: seconds
109 doc: Unit of measurement for time, which is fixed to 'seconds'.
110- name: timestamps
111 dtype: float64
112 dims:
113 - num_times
114 shape:
115 - null
116 doc: Timestamps for samples stored in data, in seconds, relative to the common
117 experiment master clock stored in NWBFile.timestamps_reference_time.
118 quantity: '?'
119 attributes:
120 - name: interval
121 dtype: int32
122 value: 1
123 doc: Value is '1'
124 - name: unit
125 dtype: text
126 value: seconds
127 doc: Unit of measurement for timestamps, which is fixed to 'seconds'.
128- name: control
129 dtype: uint8
130 dims:
131 - num_times
132 shape:
133 - null
134 doc: Numerical labels that apply to each time point in data for the purpose of
135 querying and slicing data by these values. If present, the length of this
136 array should be the same as the length of the first dimension of data.
137 quantity: '?'
138- name: control_description
139 dtype: text
140 dims:
141 - num_control_values
142 shape:
143 - null
144 doc: Description of each control value. Must be present if control is present.
145 If present, control_description[0] should describe time points where control
146 == 0.
147 quantity: '?'
148groups:
149- name: sync
150 doc: Lab-specific time and sync information as provided directly from hardware
151 devices and that is necessary for aligning all acquired time information to
152 a common timebase. The timestamp array stores time in the common timebase.
153 This group will usually only be populated in TimeSeries that are stored
154 external to the NWB file, in files storing raw data. Once timestamp data is
155 calculated, the contents of 'sync' are mostly for archival purposes.
156 quantity: '?'
3.2.10. ProcessingModule
Extends: NWBContainer
Description: see Section 2.1.10
YAML Specification:
1neurodata_type_def: ProcessingModule
2neurodata_type_inc: NWBContainer
3doc: A collection of processed data.
4attributes:
5- name: description
6 dtype: text
7 doc: Description of this collection of processed data.
8groups:
9- neurodata_type_inc: NWBDataInterface
10 doc: Data objects stored in this collection.
11 quantity: '*'
12- neurodata_type_inc: DynamicTable
13 doc: Tables stored in this collection.
14 quantity: '*'
3.2.11. Images
Extends: NWBDataInterface
Description: see Section 2.1.11
YAML Specification:
1neurodata_type_def: Images
2neurodata_type_inc: NWBDataInterface
3default_name: Images
4doc: A collection of images with an optional way to specify the order of the
5 images using the "order_of_images" dataset. An order must be specified if the
6 images are referenced by index, e.g., from an IndexSeries.
7attributes:
8- name: description
9 dtype: text
10 doc: Description of this collection of images.
11datasets:
12- neurodata_type_inc: BaseImage
13 doc: Images stored in this collection.
14 quantity: +
15- name: order_of_images
16 neurodata_type_inc: ImageReferences
17 doc: Ordered dataset of references to BaseImage objects stored in the parent
18 group. Each object in the Images group should be stored once and only once,
19 so the dataset should have the same length as the number of images.
20 quantity: '?'
3.3. Devices
This source module contains neurodata_types for device data.
3.3.1. Device
Extends: NWBContainer
Description: see Section 2.2.1
YAML Specification:
1neurodata_type_def: Device
2neurodata_type_inc: NWBContainer
3doc: Metadata about a specific instance of a data acquisition device, e.g.,
4 recording system, electrode, microscope. Link to a DeviceModel.model to
5 represent information about the model of the device.
6attributes:
7- name: description
8 dtype: text
9 doc: Description of the device as free-form text. If there is any
10 software/firmware associated with the device, the names and versions of
11 those can be added to NWBFile.was_generated_by.
12 required: false
13- name: manufacturer
14 dtype: text
15 doc: DEPRECATED. The name of the manufacturer of the device, e.g., Imec,
16 Plexon, Thorlabs. Instead of using this field, store the value in
17 DeviceModel.manufacturer and link to that DeviceModel from this Device.
18 required: false
19- name: model_number
20 dtype: text
21 doc: DEPRECATED. The model number (or part/product number) of the device,
22 e.g., PRB_1_4_0480_1, PLX-VP-32-15SE(75)-(260-80)(460-10)-300-(1)CON/32m-V,
23 BERGAMO. Instead of using this field, store the value in
24 DeviceModel.model_number and link to that DeviceModel from this Device.
25 required: false
26- name: model_name
27 dtype: text
28 doc: DEPRECATED. The model name of the device, e.g., Neuropixels 1.0, V-Probe,
29 Bergamo III. Instead of using this field, create and add a new DeviceModel
30 named the model name and link to that DeviceModel from this Device.
31 required: false
32- name: serial_number
33 dtype: text
34 doc: The serial number of the device.
35 required: false
36links:
37- name: model
38 target_type: DeviceModel
39 doc: The model of the device.
40 quantity: '?'
3.3.2. DeviceModel
Extends: NWBContainer
Description: see Section 2.2.2
YAML Specification:
1neurodata_type_def: DeviceModel
2neurodata_type_inc: NWBContainer
3doc: Model properties of a data acquisition device, e.g., recording system,
4 electrode, microscope. This should be extended for specific types of device
5 models to include additional attributes specific to each type. The name of the
6 DeviceModel should be the most common representation of the model name, e.g.,
7 Neuropixels 1.0, V-Probe, Bergamo III.
8attributes:
9- name: manufacturer
10 dtype: text
11 doc: The name of the manufacturer of the device model, e.g., Imec, Plexon,
12 Thorlabs.
13- name: model_number
14 dtype: text
15 doc: The model number (or part/product number) of the device, e.g.,
16 PRB_1_4_0480_1, PLX-VP-32-15SE(75)-(260-80)(460-10)-300-(1)CON/32m-V,
17 BERGAMO.
18 required: false
19- name: description
20 dtype: text
21 doc: Description of the device model as free-form text.
22 required: false
3.4. Epochs
This source module contains neurodata_types for epoch data.
3.4.1. TimeIntervals
Extends: DynamicTable
Description: see Section 2.3.1
YAML Specification:
1neurodata_type_def: TimeIntervals
2neurodata_type_inc: DynamicTable
3doc: A column-based table to store information about time intervals, one
4 interval per row. Use `TimeIntervals` when each row naturally has a start and
5 stop time and represents a contiguous period of time, often encompassing an
6 experimental condition. Rows can optionally reference `TimeSeries` data via
7 the `timeseries` column. Examples include trials, epochs, behavioral states
8 (e.g., "running", "resting"), and invalid recording windows.
9datasets:
10- name: start_time
11 neurodata_type_inc: VectorData
12 dtype: float32
13 doc: Start time of epoch, in seconds.
14- name: stop_time
15 neurodata_type_inc: VectorData
16 dtype: float32
17 doc: Stop time of epoch, in seconds.
18- name: tags
19 neurodata_type_inc: VectorData
20 dtype: text
21 doc: User-defined tags that identify or categorize events.
22 quantity: '?'
23- name: tags_index
24 neurodata_type_inc: VectorIndex
25 doc: Index for tags.
26 quantity: '?'
27- name: timeseries
28 neurodata_type_inc: TimeSeriesReferenceVectorData
29 doc: An index into a TimeSeries object.
30 quantity: '?'
31- name: timeseries_index
32 neurodata_type_inc: VectorIndex
33 doc: Index for timeseries.
34 quantity: '?'
3.5. Events
This source module contains neurodata_types for event data.
3.5.1. TimestampVectorData
Extends: VectorData
Description: see Section 2.4.1
YAML Specification:
1neurodata_type_def: TimestampVectorData
2neurodata_type_inc: VectorData
3dtype: float
4dims:
5- num_times
6shape:
7- null
8doc: A 1-D VectorData that stores timestamps in seconds from the session start
9 time. Timestamps are not required to be sorted in time.
10attributes:
11- name: unit
12 dtype: text
13 value: seconds
14 doc: The unit of measurement for the timestamps, fixed to 'seconds'.
15- name: resolution
16 dtype: float
17 doc: The temporal resolution of the timestamps, in seconds. This is typically
18 the sampling period (1 / sampling_rate), also known as the clock period, of
19 the data acquisition system from which the timestamps were recorded or
20 derived.
21 required: false
3.5.2. DurationVectorData
Extends: VectorData
Description: see Section 2.4.2
YAML Specification:
1neurodata_type_def: DurationVectorData
2neurodata_type_inc: VectorData
3dtype: float
4dims:
5- num_times
6shape:
7- null
8doc: A 1-D VectorData that stores durations in seconds.
9attributes:
10- name: unit
11 dtype: text
12 value: seconds
13 doc: The unit of measurement for the durations, fixed to 'seconds'.
14- name: resolution
15 dtype: float
16 doc: The temporal resolution of the durations, in seconds. This is typically
17 the sampling period (1 / sampling_rate), also known as the clock period, of
18 the data acquisition system from which the durations were recorded or
19 derived.
20 required: false
3.5.3. EventsTable
Extends: DynamicTable
Description: see Section 2.4.3
YAML Specification:
1neurodata_type_def: EventsTable
2neurodata_type_inc: DynamicTable
3doc: A column-based table to store information about events, one event per row.
4 Use `EventsTable` when each row is anchored at a single timestamp and duration
5 is absent, optional, or mixed across rows. Additional columns may be added to
6 store metadata about each event, such as the duration of the event. Examples
7 include TTL pulses, licks, rewards, stimulus onsets, and detected ripples.
8 Each `EventsTable` should hold events of a single type, so that all rows share
9 the same set of per-event metadata columns. Events of different types (e.g.,
10 licks and stimulus presentations) should be stored in separate `EventsTable`
11 instances.
12attributes:
13- name: description
14 dtype: text
15 doc: A description of the events stored in the table, including information
16 about how the event times were computed, especially if the times are the
17 result of processing or filtering raw data. For example, if the experimenter
18 is encoding different types of events using a strobed or N-bit encoding,
19 then the description should describe which channels were used and how the
20 event time is computed, e.g., as the rise time of the first bit.
21- name: source_description
22 dtype: text
23 doc: Optional short text description of where the events came from, applying
24 to every row in the table. For example, "Acquisition system" for events
25 emitted directly by the acquisition system (e.g., TTL edges or hardware
26 event channels); "Thresholding of analog signal ANALOG1 at 3 V" for events
27 produced by a detection algorithm run on acquired data; or "Manual video
28 review" for events added by a human annotator. This is a free-text label of
29 origin only; use `description` for the longer narrative of how the event
30 times were computed (channels used, encoding scheme, algorithm parameters,
31 etc.).
32 required: false
33datasets:
34- name: timestamp
35 neurodata_type_inc: TimestampVectorData
36 doc: Column containing the time that each event occurred, in seconds, from the
37 session start time.
38- name: duration
39 neurodata_type_inc: DurationVectorData
40 doc: Optional column containing the duration of each event, in seconds. A
41 value of NaN can be used for events without a duration or with a duration
42 that is not yet specified.
43 quantity: '?'
44- name: annotation
45 neurodata_type_inc: VectorData
46 dtype: text
47 dims:
48 - num_times
49 shape:
50 - null
51 doc: Column containing user annotations about events.
52 quantity: '?'
3.6. Image data
This source module contains neurodata_types for image data.
3.6.1. GrayscaleImage
Extends: Image
Description: see Section 2.5.1
YAML Specification:
1neurodata_type_def: GrayscaleImage
2neurodata_type_inc: Image
3dtype: numeric
4dims:
5- x
6- y
7shape:
8- null
9- null
10doc: A grayscale image.
3.6.2. RGBImage
Extends: Image
Description: see Section 2.5.2
YAML Specification:
1neurodata_type_def: RGBImage
2neurodata_type_inc: Image
3dtype: numeric
4dims:
5- x
6- y
7- r, g, b
8shape:
9- null
10- null
11- 3
12doc: A color image.
3.6.3. RGBAImage
Extends: Image
Description: see Section 2.5.3
YAML Specification:
1neurodata_type_def: RGBAImage
2neurodata_type_inc: Image
3dtype: numeric
4dims:
5- x
6- y
7- r, g, b, a
8shape:
9- null
10- null
11- 4
12doc: A color image with transparency.
3.6.4. ImageSeries
Extends: TimeSeries
Description: see Section 2.5.4
YAML Specification:
1neurodata_type_def: ImageSeries
2neurodata_type_inc: TimeSeries
3doc: General image data that is common between acquisition and stimulus time
4 series. Sometimes the image data is stored in the file in a raw format while
5 other times it will be stored as a series of external image files in the host
6 file system. The data field will either be binary data, if the data is stored
7 in the NWB file, or empty, if the data is stored in an external image stack.
8 [frame][x][y] or [frame][x][y][z].
9datasets:
10- name: data
11 dtype: numeric
12 dims:
13 - - frame
14 - x
15 - y
16 - - frame
17 - x
18 - y
19 - z
20 shape:
21 - - null
22 - null
23 - null
24 - - null
25 - null
26 - null
27 - null
28 doc: Binary data representing images across frames. If data are stored in an
29 external file, this should be an empty 3-D array.
30- name: dimension
31 dtype: int32
32 dims:
33 - rank
34 shape:
35 - null
36 doc: Number of pixels on x, y, (and z) axes.
37 quantity: '?'
38- name: external_file
39 dtype: text
40 dims:
41 - num_files
42 shape:
43 - null
44 doc: Paths to one or more external file(s). The field is only present if
45 format='external'. This is only relevant if the image series is stored in
46 the file system as one or more image file(s). This field should NOT be used
47 if the image is stored in another NWB file and that file is linked to this
48 file.
49 quantity: '?'
50 attributes:
51 - name: starting_frame
52 dtype: int32
53 dims:
54 - num_files
55 shape:
56 - null
57 doc: Each external image may contain one or more consecutive frames of the
58 full ImageSeries. This attribute serves as an index to indicate which
59 frames each file contains, to facilitate random access. The
60 'starting_frame' attribute, hence, contains a list of frame numbers within
61 the full ImageSeries of the first frame of each file listed in the parent
62 'external_file' dataset. Zero-based indexing is used (hence, the first
63 element will always be zero). For example, if the 'external_file' dataset
64 has three paths to files and the first file has 5 frames, the second file
65 has 10 frames, and the third file has 20 frames, then this attribute will
66 have values [0, 5, 15]. If there is a single external file that holds all
67 of the frames of the ImageSeries (and so there is a single element in the
68 'external_file' dataset), then this attribute should have value [0].
69- name: num_samples
70 dtype: uint32
71 doc: Total number of frames across all external files. This is required when
72 format='external' and timing is described using starting_time and rate,
73 since data is empty and its first dimension cannot be used to determine the
74 number of frames. When timestamps is provided, len(timestamps) already
75 serves this purpose.
76 quantity: '?'
77- name: format
78 dtype: text
79 default_value: raw
80 doc: Format of image. If this is 'external', then the attribute
81 'external_file' contains the path information to the image files. If this is
82 'raw', then the raw (single-channel) binary data is stored in the 'data'
83 dataset. If this attribute is not present, then the default format='raw'
84 case is assumed.
85 quantity: '?'
86links:
87- name: device
88 target_type: Device
89 doc: Link to the Device object that was used to capture these images.
90 quantity: '?'
3.6.5. ImageMaskSeries
Extends: ImageSeries
Description: see Section 2.5.5
YAML Specification:
1neurodata_type_def: ImageMaskSeries
2neurodata_type_inc: ImageSeries
3doc: DEPRECATED. An alpha mask that is applied to a presented visual stimulus.
4 The 'data' array contains an array of mask values that are applied to the
5 displayed image. Mask values are stored as RGBA. Mask can vary with time. The
6 timestamps array indicates the starting time of a mask, and that mask pattern
7 continues until it is explicitly changed.
8links:
9- name: masked_imageseries
10 target_type: ImageSeries
11 doc: Link to ImageSeries object that this image mask is applied to.
3.6.6. OpticalSeries
Extends: ImageSeries
Description: see Section 2.5.6
YAML Specification:
1neurodata_type_def: OpticalSeries
2neurodata_type_inc: ImageSeries
3doc: Image data that is presented or recorded. A stimulus template movie will be
4 stored only as an image. When the image is presented as stimulus, additional
5 data is required, such as field of view (e.g., how much of the visual field
6 the image covers, or how large the imaged area of the target is). If the
7 OpticalSeries represents acquired imaging data, orientation is also important.
8datasets:
9- name: distance
10 dtype: float32
11 doc: Distance from camera/monitor to target/eye.
12 quantity: '?'
13- name: field_of_view
14 dtype: float32
15 dims:
16 - - width, height
17 - - width, height, depth
18 shape:
19 - - 2
20 - - 3
21 doc: Width, height and depth of image, or imaged area, in meters.
22 quantity: '?'
23- name: data
24 dtype: numeric
25 dims:
26 - - frame
27 - x
28 - y
29 - - frame
30 - x
31 - y
32 - r, g, b
33 shape:
34 - - null
35 - null
36 - null
37 - - null
38 - null
39 - null
40 - 3
41 doc: Images presented to subject, either grayscale or RGB
42- name: orientation
43 dtype: text
44 doc: Description of image relative to some reference frame (e.g., which way is
45 up). Must also specify frame of reference.
46 quantity: '?'
3.6.7. IndexSeries
Extends: TimeSeries
Description: see Section 2.5.7
YAML Specification:
1neurodata_type_def: IndexSeries
2neurodata_type_inc: TimeSeries
3doc: Stores indices that reference images defined in other containers. The
4 primary purpose of the IndexSeries is to allow images stored in an Images
5 container to be referenced in a specific sequence through the 'indexed_images'
6 link. This approach avoids duplicating image data when the same image needs to
7 be presented multiple times or when images need to be shown in a different
8 order than they are stored. Since images in an Images container do not have an
9 inherent order, the Images container needs to include an 'order_of_images'
10 dataset (of type ImageReferences) whenever it is referenced by an IndexSeries.
11 This dataset establishes the ordered sequence that the indices in IndexSeries
12 refer to. The 'data' field stores the index into this ordered sequence, and
13 the 'timestamps' array indicates the precise presentation time of each indexed
14 image during an experiment. This can be used for displaying individual images
15 or creating movie segments by referencing a sequence of images with the
16 appropriate timestamps. While IndexSeries can also reference frames from an
17 ImageSeries through the 'indexed_timeseries' link, this usage is discouraged
18 and will be deprecated in favor of using Images containers with
19 'order_of_images'.
20datasets:
21- name: data
22 dtype: uint32
23 dims:
24 - num_times
25 shape:
26 - null
27 doc: Index of the image (using zero-indexing) in the linked Images object.
28 attributes:
29 - name: conversion
30 dtype: float32
31 doc: This field is unused by IndexSeries.
32 required: false
33 - name: resolution
34 dtype: float32
35 doc: This field is unused by IndexSeries.
36 required: false
37 - name: offset
38 dtype: float32
39 doc: This field is unused by IndexSeries.
40 required: false
41 - name: unit
42 dtype: text
43 value: N/A
44 doc: This field is unused by IndexSeries and has the value N/A.
45links:
46- name: indexed_timeseries
47 target_type: ImageSeries
48 doc: Link to ImageSeries object containing images that are indexed. Use of
49 this link is discouraged and will be deprecated. Link to an Images type
50 instead.
51 quantity: '?'
52- name: indexed_images
53 target_type: Images
54 doc: Link to Images object containing an ordered set of images that are
55 indexed. The Images object must contain an 'order_of_images' dataset
56 specifying the order of the images in the Images type.
57 quantity: '?'
3.7. NWB file
Main NWB file specification.
3.7.1. ScratchData
Extends: NWBData
Description: see Section 2.6.1
YAML Specification:
1neurodata_type_def: ScratchData
2neurodata_type_inc: NWBData
3doc: Any one-off datasets
4attributes:
5- name: notes
6 dtype: text
7 doc: Any notes the user has about the dataset being stored
3.7.2. NWBFile
Extends: NWBContainer
Description: see Section 2.6.2
YAML Specification:
1neurodata_type_def: NWBFile
2neurodata_type_inc: NWBContainer
3name: root
4doc: An NWB file storing cellular-based neurophysiology data from a single
5 experimental session.
6attributes:
7- name: nwb_version
8 dtype: text
9 value: 2.10.1-alpha
10 doc: File version string. Use semantic versioning, e.g., 1.2.1. This will be
11 the name of the format with trailing major, minor and patch numbers.
12datasets:
13- name: file_create_date
14 dtype: isodatetime
15 dims:
16 - num_modifications
17 shape:
18 - null
19 doc: 'A record of the date the file was created and of subsequent modifications.
20 The date is stored in UTC with local timezone offset as ISO 8601 extended formatted
21 strings: 2018-09-28T14:43:54.123+02:00. Dates stored in UTC end in "Z" with no
22 timezone offset. Date accuracy is up to milliseconds. The file can be created
23 after the experiment was run, so this may differ from the experiment start time.
24 Each modification to the nwb file adds a new entry to the array.'
25- name: identifier
26 dtype: text
27 doc: A unique text identifier for the file. For example, concatenated lab
28 name, file creation date/time and experimentalist, or a hash of these and/or
29 other values. The goal is that the string should be unique to all other
30 files.
31- name: session_description
32 dtype: text
33 doc: A description of the experimental session and data in the file.
34- name: session_start_time
35 dtype: isodatetime
36 doc: 'Date and time of the experiment/session start. The date is stored in UTC with
37 local timezone offset as ISO 8601 extended formatted string: 2018-09-28T14:43:54.123+02:00.
38 Dates stored in UTC end in "Z" with no timezone offset. Date accuracy is up to
39 milliseconds.'
40- name: timestamps_reference_time
41 dtype: isodatetime
42 doc: 'Date and time corresponding to time zero of all timestamps. The date is stored
43 in UTC with local timezone offset as ISO 8601 extended formatted string: 2018-09-28T14:43:54.123+02:00.
44 Dates stored in UTC end in "Z" with no timezone offset. Date accuracy is up to
45 milliseconds. All times stored in the file use this time as reference (i.e., time
46 zero).'
47groups:
48- name: acquisition
49 doc: Data streams recorded from the system, including ephys, ophys, tracking,
50 etc. This group should be read-only after the experiment is completed and
51 timestamps are corrected to a common timebase. The data stored here may be
52 links to raw data stored in external NWB files. This will allow keeping
53 bulky raw data out of the file while preserving the option of keeping
54 some/all in the file. Acquired data includes tracking and experimental data
55 streams (i.e., everything measured from the system). If bulky data is stored
56 in the /acquisition group, the data can exist in a separate NWB file that is
57 linked to by the file being used for processing and analysis.
58 groups:
59 - neurodata_type_inc: NWBDataInterface
60 doc: Acquired, raw data.
61 quantity: '*'
62 - neurodata_type_inc: DynamicTable
63 doc: Tabular data that is relevant to acquisition
64 quantity: '*'
65- name: analysis
66 doc: Lab-specific and custom scientific analysis of data. There is no defined
67 format for the content of this group - the format is up to the individual
68 user/lab. To facilitate sharing analysis data between labs, the contents
69 here should be stored in standard types (e.g., neurodata_types) and
70 appropriately documented. The file can store lab-specific and custom data
71 analysis without restriction on its form or schema, reducing data formatting
72 restrictions on end users. Such data should be placed in the analysis group.
73 The analysis data should be documented so that it could be shared with other
74 labs.
75 groups:
76 - neurodata_type_inc: NWBContainer
77 doc: Custom analysis results.
78 quantity: '*'
79 - neurodata_type_inc: DynamicTable
80 doc: Tabular data that is relevant to data stored in analysis
81 quantity: '*'
82- name: scratch
83 doc: A place to store one-off analysis results. Data placed here is not
84 intended for sharing. By placing data here, users acknowledge that there is
85 no guarantee that their data meets any standard.
86 quantity: '?'
87 datasets:
88 - neurodata_type_inc: ScratchData
89 doc: Any one-off datasets
90 quantity: '*'
91 groups:
92 - neurodata_type_inc: NWBContainer
93 doc: Any one-off containers
94 quantity: '*'
95 - neurodata_type_inc: DynamicTable
96 doc: Any one-off tables
97 quantity: '*'
98- name: processing
99 doc: The home for ProcessingModules. These modules perform intermediate
100 analysis of data that is necessary to perform before scientific analysis.
101 Examples include spike clustering, extracting position from tracking data,
102 stitching together image slices. ProcessingModules can be large and express
103 many data sets from relatively complex analysis (e.g., spike detection and
104 clustering) or small, representing extraction of position information from
105 tracking video, or even binary lick/no-lick decisions. Common software tools
106 (e.g., klustakwik, MClust) are expected to read/write data here.
107 'Processing' refers to intermediate analysis of the acquired data to make it
108 more amenable to scientific analysis.
109 groups:
110 - neurodata_type_inc: ProcessingModule
111 doc: Intermediate analysis of acquired data.
112 quantity: '*'
113- name: stimulus
114 doc: Data pushed into the system (e.g., video stimulus, sound, voltage, etc.)
115 and secondary representations of that data (e.g., measurements of something
116 used as a stimulus). This group should be made read-only after the
117 experiment is complete and timestamps are corrected to a common timebase.
118 Stores both presented stimuli and stimulus templates, the latter in case the
119 same stimulus is presented multiple times, or is pulled from an external
120 stimulus library. Stimuli are here defined as any signal that is pushed into
121 the system as part of the experiment (e.g., sound, video, voltage, etc.).
122 Many different experiments can use the same stimuli, and stimuli can be
123 reused during an experiment. The stimulus group is organized so that one
124 version of template stimuli can be stored and these can be used multiple
125 times. These templates can exist in the present file or can be linked to a
126 remote library file.
127 groups:
128 - name: presentation
129 doc: Stimuli presented during the experiment.
130 groups:
131 - neurodata_type_inc: TimeSeries
132 doc: TimeSeries objects containing data of presented stimuli.
133 quantity: '*'
134 - neurodata_type_inc: NWBDataInterface
135 doc: Generic NWB data interfaces, usually from an extension, containing
136 data of presented stimuli.
137 quantity: '*'
138 - neurodata_type_inc: DynamicTable
139 doc: DynamicTable objects containing data of presented stimuli.
140 quantity: '*'
141 - name: templates
142 doc: Template stimuli. Timestamps in templates are based on stimulus design
143 and are relative to the beginning of the stimulus. When templates are
144 used, the stimulus instances must convert presentation times to the
145 experiment's time reference frame.
146 groups:
147 - neurodata_type_inc: TimeSeries
148 doc: TimeSeries objects containing template data of presented stimuli.
149 quantity: '*'
150 - neurodata_type_inc: Images
151 doc: Images objects containing images of presented stimuli.
152 quantity: '*'
153- name: general
154 doc: Experimental metadata, including protocol, notes and description of
155 hardware device(s). The metadata stored in this section should be used to
156 describe the experiment. Metadata necessary for interpreting the data is
157 stored with the data. General experimental metadata, including animal
158 strain, experimental protocols, experimenter, devices, etc. are stored under
159 'general'. Core metadata (e.g., that required to interpret data fields) is
160 stored with the data itself, and implicitly defined by the file
161 specification (e.g., time is in seconds). The strategy used here for storing
162 non-core metadata is to use free-form text fields, such as would appear in
163 sentences or paragraphs from a Methods section. Metadata fields are text to
164 enable them to be more general, for example to represent ranges instead of
165 numerical values. Machine-readable metadata is stored as attributes to these
166 free-form datasets. All entries in the below table are to be included when
167 data is present. Unused groups (e.g., intracellular_ephys in an
168 optophysiology experiment) should not be created unless there is data to
169 store within them.
170 datasets:
171 - name: data_collection
172 dtype: text
173 doc: Notes about data collection and analysis.
174 quantity: '?'
175 - name: experiment_description
176 dtype: text
177 doc: General description of the experiment.
178 quantity: '?'
179 - name: experimenter
180 dtype: text
181 dims:
182 - num_experimenters
183 shape:
184 - null
185 doc: Name of person(s) who performed the experiment. Can also specify roles
186 of different people involved.
187 quantity: '?'
188 - name: institution
189 dtype: text
190 doc: Institution(s) where experiment was performed.
191 quantity: '?'
192 - name: keywords
193 dtype: text
194 dims:
195 - num_keywords
196 shape:
197 - null
198 doc: Terms to search over.
199 quantity: '?'
200 - name: lab
201 dtype: text
202 doc: Laboratory where experiment was performed.
203 quantity: '?'
204 - name: notes
205 dtype: text
206 doc: Notes about the experiment.
207 quantity: '?'
208 - name: pharmacology
209 dtype: text
210 doc: Description of drugs used, including how and when they were
211 administered. Anesthesia(s), painkiller(s), etc., plus dosage,
212 concentration, etc.
213 quantity: '?'
214 - name: protocol
215 dtype: text
216 doc: Experimental protocol, if applicable. e.g., include IACUC protocol
217 number.
218 quantity: '?'
219 - name: related_publications
220 dtype: text
221 dims:
222 - num_publications
223 shape:
224 - null
225 doc: Publication information. PMID, DOI, URL, etc.
226 quantity: '?'
227 - name: session_id
228 dtype: text
229 doc: Lab-specific ID for the session.
230 quantity: '?'
231 - name: slices
232 dtype: text
233 doc: Description of slices, including information about preparation
234 thickness, orientation, temperature, and bath solution.
235 quantity: '?'
236 - name: source_script
237 dtype: text
238 doc: Script file or link to public source code used to create this NWB file.
239 quantity: '?'
240 attributes:
241 - name: file_name
242 dtype: text
243 doc: Name of script file.
244 - name: was_generated_by
245 dtype: text
246 dims:
247 - num_sources
248 - name, version
249 shape:
250 - null
251 - 2
252 doc: Name and version of software package(s) used to generate data contained
253 in this NWB file. For each software package or library, include the name
254 of the software as the first value and the version as the second value.
255 quantity: '?'
256 - name: stimulus
257 dtype: text
258 doc: Notes about stimuli, such as how and where they were presented.
259 quantity: '?'
260 - name: surgery
261 dtype: text
262 doc: Narrative description about surgery/surgeries, including date(s) and
263 who performed surgery.
264 quantity: '?'
265 - name: virus
266 dtype: text
267 doc: Information about virus(es) used in experiments, including virus ID,
268 source, date made, injection location, volume, etc.
269 quantity: '?'
270 groups:
271 - name: external_resources
272 neurodata_type_inc: HERD
273 doc: This is the HERD structure for this specific NWBFile, storing the
274 mapped external resources.
275 quantity: '?'
276 - neurodata_type_inc: LabMetaData
277 doc: Place-holder that can be extended so that lab-specific meta-data can be
278 placed in /general.
279 quantity: '*'
280 - name: devices
281 doc: Description of hardware devices used during experiment, e.g., monitors,
282 ADC boards, microscopes, etc.
283 quantity: '?'
284 groups:
285 - neurodata_type_inc: Device
286 doc: Data acquisition devices.
287 quantity: '*'
288 - name: models
289 doc: Collection of data acquisition device models.
290 quantity: '?'
291 groups:
292 - neurodata_type_inc: DeviceModel
293 doc: Data acquisition device models.
294 quantity: '*'
295 - name: subject
296 neurodata_type_inc: Subject
297 doc: Information about the animal or person from which the data was
298 measured.
299 quantity: '?'
300 - name: extracellular_ephys
301 doc: Metadata related to extracellular electrophysiology.
302 quantity: '?'
303 groups:
304 - neurodata_type_inc: ElectrodeGroup
305 doc: Physical group of electrodes.
306 quantity: '*'
307 - name: electrodes
308 neurodata_type_inc: ElectrodesTable
309 doc: A table of all electrodes (i.e., channels) used for recording.
310 Changed in NWB 2.9.0 to use the newly added ElectrodesTable neurodata
311 type instead of a DynamicTable with added columns.
312 quantity: '?'
313 - name: intracellular_ephys
314 doc: Metadata related to intracellular electrophysiology.
315 quantity: '?'
316 datasets:
317 - name: filtering
318 dtype: text
319 doc: '[DEPRECATED] Use IntracellularElectrode.filtering instead. Description
320 of filtering used. Includes filtering type and parameters, frequency fall-off,
321 etc. If this changes between TimeSeries, filter description should be stored
322 as a text attribute for each TimeSeries.'
323 quantity: '?'
324 groups:
325 - neurodata_type_inc: IntracellularElectrode
326 doc: An intracellular electrode.
327 quantity: '*'
328 - name: sweep_table
329 neurodata_type_inc: SweepTable
330 doc: '[DEPRECATED] Table used to group different PatchClampSeries. SweepTable
331 is being replaced by IntracellularRecordingsTable and SimultaneousRecordingsTable
332 tables. Additional SequentialRecordingsTable, RepetitionsTable and ExperimentalConditions
333 tables provide enhanced support for experiment metadata.'
334 quantity: '?'
335 - name: intracellular_recordings
336 neurodata_type_inc: IntracellularRecordingsTable
337 doc: A table to group together a stimulus and response from a single
338 electrode and a single simultaneous recording. Each row in the table
339 represents a single recording consisting typically of a stimulus and a
340 corresponding response. In some cases, however, only a stimulus or a
341 response are recorded as part of an experiment. In this case, both the
342 stimulus and response will point to the same TimeSeries while the
343 idx_start and count of the invalid column will be set to -1, thus,
344 indicating that no values have been recorded for the stimulus or
345 response, respectively. Note, a recording MUST contain at least a
346 stimulus or a response. Typically the stimulus and response are
347 PatchClampSeries. However, the use of AD/DA channels that are not
348 associated to an electrode is also common in intracellular
349 electrophysiology, in which case other TimeSeries may be used.
350 quantity: '?'
351 - name: simultaneous_recordings
352 neurodata_type_inc: SimultaneousRecordingsTable
353 doc: A table for grouping different intracellular recordings from the
354 IntracellularRecordingsTable table together that were recorded
355 simultaneously from different electrodes
356 quantity: '?'
357 - name: sequential_recordings
358 neurodata_type_inc: SequentialRecordingsTable
359 doc: A table for grouping different sequential recordings from the
360 SimultaneousRecordingsTable table together. This is typically used to
361 group together sequential recordings where a sequence of stimuli of the
362 same type with varying parameters have been presented in a sequence.
363 quantity: '?'
364 - name: repetitions
365 neurodata_type_inc: RepetitionsTable
366 doc: A table for grouping different sequential intracellular recordings
367 together. With each SequentialRecording typically representing a
368 particular type of stimulus, the RepetitionsTable table is typically
369 used to group sets of stimuli applied in sequence.
370 quantity: '?'
371 - name: experimental_conditions
372 neurodata_type_inc: ExperimentalConditionsTable
373 doc: A table for grouping different intracellular recording repetitions
374 together that belong to the same experimental conditions.
375 quantity: '?'
376 - name: optogenetics
377 doc: Metadata describing optogenetic stimulation.
378 quantity: '?'
379 groups:
380 - neurodata_type_inc: OptogeneticStimulusSite
381 doc: An optogenetic stimulation site.
382 quantity: '*'
383 - name: optophysiology
384 doc: Metadata related to optophysiology.
385 quantity: '?'
386 groups:
387 - neurodata_type_inc: ImagingPlane
388 doc: An imaging plane.
389 quantity: '*'
390- name: intervals
391 doc: Experimental intervals, whether these are logically distinct
392 sub-experiments having a particular scientific goal, trials (see trials
393 subgroup) during an experiment, or epochs (see epochs subgroup) derived from
394 analysis of data.
395 quantity: '?'
396 groups:
397 - name: epochs
398 neurodata_type_inc: TimeIntervals
399 doc: Time intervals marking coarse-grained experimental phases or
400 subdivisions of a recording session, such as baseline, task, rest, or
401 sleep stages.
402 quantity: '?'
403 - name: trials
404 neurodata_type_inc: TimeIntervals
405 doc: Time intervals corresponding to repeated experimental units with
406 consistent structure, such as individual stimulus-response-reward cycles.
407 quantity: '?'
408 - name: invalid_times
409 neurodata_type_inc: TimeIntervals
410 doc: Time intervals that should be removed from analysis.
411 quantity: '?'
412 - neurodata_type_inc: TimeIntervals
413 doc: Optional additional table(s) for describing other experimental time
414 intervals.
415 quantity: '*'
416- name: events
417 doc: Experimental event tables for the session, stored as `EventsTable`
418 instances. This is the recommended location for all event tables in the
419 file, regardless of whether the events were emitted directly by the
420 acquisition system (TTL edges, hardware event channels), derived by user
421 processing (filtering, detection algorithms), or added as post-hoc
422 annotations. The provenance of each table can be recorded in the
423 `source_description` attribute of the `EventsTable` and described in more
424 detail in its `description`. Each `EventsTable` should hold events of a
425 single type (i.e., events sharing the same per-event metadata columns). For
426 periods with required start and stop times, see `/intervals/`. For
427 continuous acquired signals or stimulus templates from which events may have
428 been derived, see `/acquisition/` or `/stimulus/`.
429 quantity: '?'
430 groups:
431 - neurodata_type_inc: EventsTable
432 doc: An EventsTable holding a collection of event times of a particular type
433 (e.g., licks, rewards, stimulus presentations) along with their per-event
434 metadata.
435 quantity: '*'
436- name: units
437 neurodata_type_inc: Units
438 doc: Data about sorted spike units.
439 quantity: '?'
3.7.3. LabMetaData
Extends: NWBContainer
Description: see Section 2.6.3
YAML Specification:
1neurodata_type_def: LabMetaData
2neurodata_type_inc: NWBContainer
3doc: Lab-specific meta-data.
3.7.4. Subject
Extends: NWBContainer
Description: see Section 2.6.4
YAML Specification:
1neurodata_type_def: Subject
2neurodata_type_inc: NWBContainer
3doc: Information about the animal or person from which the data was measured.
4datasets:
5- name: age
6 dtype: text
7 doc: Age of subject. Can be supplied instead of 'date_of_birth'. The ISO 8601
8 Duration format is recommended, e.g., 'P90D' for 90 days old. If the precise
9 age is unknown, an age range can be given by '[lower bound]/[upper bound]'
10 e.g. 'P10D/P20D' would mean that the age is in between 10 and 20 days. If
11 only the lower bound is known, then including only the slash after that
12 lower bound can be used to indicate a missing bound. For instance, 'P90Y/'
13 would indicate that the age is 90 years or older.
14 quantity: '?'
15 attributes:
16 - name: reference
17 dtype: text
18 default_value: birth
19 doc: Age is with reference to this event. Can be 'birth' or 'gestational'.
20 If reference is omitted, 'birth' is implied.
21 required: false
22- name: date_of_birth
23 dtype: isodatetime
24 doc: Date of birth of subject. Can be supplied instead of 'age'.
25 quantity: '?'
26- name: description
27 dtype: text
28 doc: Description of subject and where subject came from (e.g., breeder, if
29 animal).
30 quantity: '?'
31- name: genotype
32 dtype: text
33 doc: Genetic strain. If absent, assume Wild Type (WT).
34 quantity: '?'
35- name: sex
36 dtype: text
37 doc: Biological sex of subject.
38 quantity: '?'
39- name: species
40 dtype: text
41 doc: Species of subject.
42 quantity: '?'
43- name: strain
44 dtype: text
45 doc: Strain of subject.
46 quantity: '?'
47- name: subject_id
48 dtype: text
49 doc: ID of animal/person used/participating in experiment (lab convention).
50 quantity: '?'
51- name: weight
52 dtype: text
53 doc: Weight at time of experiment, at time of surgery and at other important
54 times.
55 quantity: '?'
3.8. Miscellaneous neurodata_types.
Miscellaneous types.
3.8.1. AbstractFeatureSeries
Extends: TimeSeries
Description: see Section 2.7.1
YAML Specification:
1neurodata_type_def: AbstractFeatureSeries
2neurodata_type_inc: TimeSeries
3doc: Abstract features, such as quantitative descriptions of sensory stimuli.
4 The TimeSeries::data field is a 2-D array, storing those features (e.g., for a
5 visual grating stimulus this might be orientation, spatial frequency and
6 contrast). Null stimuli (e.g., uniform gray) can be marked as being an
7 independent feature (e.g., 1.0 for gray, 0.0 for actual stimulus) or by
8 storing NaNs for feature values, or through use of the TimeSeries::control
9 fields. A set of features is considered to persist until the next set of
10 features is defined. The final set of features stored should be the null set.
11 This is useful when storing the raw stimulus is impractical.
12datasets:
13- name: data
14 dtype: numeric
15 dims:
16 - - num_times
17 - - num_times
18 - num_features
19 shape:
20 - - null
21 - - null
22 - null
23 doc: Values of each feature at each time.
24 attributes:
25 - name: unit
26 dtype: text
27 default_value: see 'feature_units'
28 doc: Since there can be different units for different features, store the
29 units in 'feature_units'. The default value for this attribute is "see
30 'feature_units'".
31 required: false
32- name: feature_units
33 dtype: text
34 dims:
35 - num_features
36 shape:
37 - null
38 doc: Units of each feature.
39 quantity: '?'
40- name: features
41 dtype: text
42 dims:
43 - num_features
44 shape:
45 - null
46 doc: Description of the features represented in TimeSeries::data.
3.8.2. AnnotationSeries
Extends: TimeSeries
Description: see Section 2.7.2
YAML Specification:
1neurodata_type_def: AnnotationSeries
2neurodata_type_inc: TimeSeries
3doc: 'DEPRECATED. Use an `EventsTable` instead, placed in the top-level `/events`
4 group of the `NWBFile`. The `timestamps` field maps to the `timestamp` column, and
5 the `data` field (annotation strings) maps to the `annotation` column on `EventsTable`.
6 Use the `source_description` attribute on the `EventsTable` to record where the
7 annotations came from (e.g., "Manual video review"). Original definition: Stores
8 user annotations made during an experiment. The data[] field stores a text array,
9 and timestamps are stored for each annotation (i.e., interval=1). This is largely
10 an alias to a standard TimeSeries storing a text array but that is identifiable
11 as storing annotations in a machine-readable way.'
12datasets:
13- name: data
14 dtype: text
15 dims:
16 - num_times
17 shape:
18 - null
19 doc: Annotations made during an experiment.
20 attributes:
21 - name: resolution
22 dtype: float32
23 value: -1.0
24 doc: Smallest meaningful difference between values in data. Annotations have
25 no units, so the value is fixed to -1.0.
26 - name: unit
27 dtype: text
28 value: n/a
29 doc: Base unit of measurement for working with the data. Annotations have no
30 units, so the value is fixed to 'n/a'.
3.8.3. IntervalSeries
Extends: TimeSeries
Description: see Section 2.7.3
YAML Specification:
1neurodata_type_def: IntervalSeries
2neurodata_type_inc: TimeSeries
3doc: Stores intervals of data. The timestamps field stores the beginning and end
4 of intervals. The data field stores whether the interval just started (>0
5 value) or ended (<0 value). Different interval types can be represented in the
6 same series by using multiple key values (e.g., 1 for feature A, 2 for feature
7 B, 3 for feature C, etc.). The field data stores an 8-bit integer. This is
8 largely an alias of a standard TimeSeries but that is identifiable as
9 representing time intervals in a machine-readable way.
10datasets:
11- name: data
12 dtype: int8
13 dims:
14 - num_times
15 shape:
16 - null
17 doc: Use values >0 if interval started, <0 if interval ended.
18 attributes:
19 - name: resolution
20 dtype: float32
21 value: -1.0
22 doc: Smallest meaningful difference between values in data. IntervalSeries
23 stores integer markers, so the value is fixed to -1.0.
24 - name: unit
25 dtype: text
26 value: n/a
27 doc: Base unit of measurement for working with the data. IntervalSeries
28 stores integer markers with no physical unit, so the value is fixed to
29 'n/a'.
3.8.4. FrequencyBandsTable
Extends: DynamicTable
Description: see Section 2.7.4
YAML Specification:
1neurodata_type_def: FrequencyBandsTable
2neurodata_type_inc: DynamicTable
3doc: Table for describing the bands that DecompositionSeries was generated from.
4 There should be one row in this table for each band.
5datasets:
6- name: band_name
7 neurodata_type_inc: VectorData
8 dtype: text
9 doc: Name of the band, e.g., theta.
10- name: band_limits
11 neurodata_type_inc: VectorData
12 dtype: float32
13 dims:
14 - num_bands
15 - low, high
16 shape:
17 - null
18 - 2
19 doc: Low and high limit of each band in Hz. If it is a Gaussian filter, use 2
20 SD on either side of the center.
21- name: band_mean
22 neurodata_type_inc: VectorData
23 dtype: float32
24 dims:
25 - num_bands
26 shape:
27 - null
28 doc: The center frequency (mean) of each Gaussian filter, in Hz.
29 quantity: '?'
30- name: band_stdev
31 neurodata_type_inc: VectorData
32 dtype: float32
33 dims:
34 - num_bands
35 shape:
36 - null
37 doc: The standard deviation (bandwidth) of each Gaussian filter, in Hz.
38 quantity: '?'
3.8.5. DecompositionSeries
Extends: TimeSeries
Description: see Section 2.7.5
YAML Specification:
1neurodata_type_def: DecompositionSeries
2neurodata_type_inc: TimeSeries
3doc: Spectral analysis of a time series, e.g., of an LFP or a speech signal.
4datasets:
5- name: data
6 dtype: numeric
7 dims:
8 - num_times
9 - num_channels
10 - num_bands
11 shape:
12 - null
13 - null
14 - null
15 doc: Data decomposed into frequency bands.
16 attributes:
17 - name: unit
18 dtype: text
19 default_value: no unit
20 doc: Base unit of measurement for working with the data. Actual stored
21 values are not necessarily stored in these units. To access the data in
22 these units, multiply 'data' by 'conversion'.
23 required: false
24- name: metric
25 dtype: text
26 doc: The metric used, e.g., phase, amplitude, power.
27- name: source_channels
28 neurodata_type_inc: DynamicTableRegion
29 doc: DynamicTableRegion pointer to the channels that this decomposition series
30 was generated from.
31 quantity: '?'
32groups:
33- name: bands
34 neurodata_type_inc: FrequencyBandsTable
35 doc: Table for describing the bands that this series was generated from.
36 quantity: '?'
37links:
38- name: source_timeseries
39 target_type: TimeSeries
40 doc: Link to TimeSeries object that this data was calculated from. Metadata
41 about electrodes and their position can be read from that ElectricalSeries
42 so it is not necessary to store that information here.
43 quantity: '?'
3.8.6. Units
Extends: DynamicTable
Description: see Section 2.7.6
YAML Specification:
1neurodata_type_def: Units
2neurodata_type_inc: DynamicTable
3default_name: Units
4doc: Data about spiking units. Event times of observed units (e.g., cell,
5 synapse, etc.) should be concatenated and stored in spike_times.
6datasets:
7- name: spike_times_index
8 neurodata_type_inc: VectorIndex
9 doc: Index into the spike_times dataset.
10 quantity: '?'
11- name: spike_times
12 neurodata_type_inc: VectorData
13 dtype: float64
14 doc: Spike times for each unit, in seconds, relative to the session reference
15 time (i.e., session_start_time or, if defined, timestamps_reference_time).
16 Times should be stored in ascending order.
17 quantity: '?'
18 attributes:
19 - name: resolution
20 dtype: float64
21 doc: The temporal resolution of the spike times, in seconds. This is
22 typically the sampling period (1/sampling_rate) of the acquisition data
23 from which spikes were extracted. If the acquisition data was downsampled
24 before spike sorting, the resolution should be based on the downsampled
25 sampling rate (lower sampling rate, larger resolution value). If
26 interpolation was applied during spike sorting, then spike times may fall
27 between samples of the acquisition data, so the resolution should be the
28 interpolation step size (higher sampling rate, smaller resolution value).
29 required: false
30- name: obs_intervals_index
31 neurodata_type_inc: VectorIndex
32 doc: Index into the obs_intervals dataset.
33 quantity: '?'
34- name: obs_intervals
35 neurodata_type_inc: VectorData
36 dtype: float64
37 dims:
38 - num_intervals
39 - start|end
40 shape:
41 - null
42 - 2
43 doc: Observation intervals for each unit, in seconds, relative to the session
44 reference time (i.e., session_start_time or, if defined,
45 timestamps_reference_time). Intervals should be in ascending order and
46 non-overlapping.
47 quantity: '?'
48- name: electrodes_index
49 neurodata_type_inc: VectorIndex
50 doc: Index into electrodes.
51 quantity: '?'
52- name: electrodes
53 neurodata_type_inc: DynamicTableRegion
54 doc: Electrode that each spike unit came from, specified using a
55 DynamicTableRegion.
56 quantity: '?'
57- name: electrode_group
58 neurodata_type_inc: VectorData
59 dtype:
60 target_type: ElectrodeGroup
61 reftype: object
62 doc: Electrode group that each spike unit came from.
63 quantity: '?'
64- name: waveform_mean
65 neurodata_type_inc: VectorData
66 dtype: float32
67 dims:
68 - - num_units
69 - num_samples
70 - - num_units
71 - num_samples
72 - num_electrodes
73 shape:
74 - - null
75 - null
76 - - null
77 - null
78 - null
79 doc: Spike waveform mean for each spike unit.
80 quantity: '?'
81 attributes:
82 - name: sampling_rate
83 dtype: float32
84 doc: Sampling rate, in hertz.
85 required: false
86 - name: unit
87 dtype: text
88 value: volts
89 doc: Unit of measurement. This value is fixed to 'volts'.
90- name: waveform_sd
91 neurodata_type_inc: VectorData
92 dtype: float32
93 dims:
94 - - num_units
95 - num_samples
96 - - num_units
97 - num_samples
98 - num_electrodes
99 shape:
100 - - null
101 - null
102 - - null
103 - null
104 - null
105 doc: Spike waveform standard deviation for each spike unit.
106 quantity: '?'
107 attributes:
108 - name: sampling_rate
109 dtype: float32
110 doc: Sampling rate, in hertz.
111 required: false
112 - name: unit
113 dtype: text
114 value: volts
115 doc: Unit of measurement. This value is fixed to 'volts'.
116- name: waveforms
117 neurodata_type_inc: VectorData
118 dtype: numeric
119 dims:
120 - num_waveforms
121 - num_samples
122 shape:
123 - null
124 - null
125 doc: Individual waveforms for each spike on each electrode. This is a doubly
126 indexed column. The 'waveforms_index' column indexes which waveforms in this
127 column belong to the same spike event for a given unit, where each waveform
128 was recorded from a different electrode. The 'waveforms_index_index' column
129 indexes the 'waveforms_index' column to indicate which spike events belong
130 to a given unit. For example, if the 'waveforms_index_index' column has
131 values [2, 5, 6], then the first 2 elements of the 'waveforms_index' column
132 correspond to the 2 spike events of the first unit, the next 3 elements of
133 the 'waveforms_index' column correspond to the 3 spike events of the second
134 unit, and the next 1 element of the 'waveforms_index' column corresponds to
135 the 1 spike event of the third unit. If the 'waveforms_index' column has
136 values [3, 6, 8, 10, 12, 13], then the first 3 elements of the 'waveforms'
137 column contain the 3 spike waveforms that were recorded from 3 different
138 electrodes for the first spike time of the first unit. See
139 https://nwb-schema.readthedocs.io/en/stable/format_description.html#doubly-ragged-arrays
140 for a graphical representation of this example. When there is only one
141 electrode for each unit (i.e., each spike time is associated with a single
142 waveform), then the 'waveforms_index' column will have values 1, 2, ..., N,
143 where N is the number of spike events. The number of electrodes for each
144 spike event should be the same within a given unit. The 'electrodes' column
145 should be used to indicate which electrodes are associated with each unit,
146 and the order of the waveforms within a given unit x spike event should be
147 the same as the order of the electrodes referenced in the 'electrodes'
148 column of this table. The number of samples for each waveform must be the
149 same.
150 quantity: '?'
151 attributes:
152 - name: sampling_rate
153 dtype: float32
154 doc: Sampling rate, in hertz.
155 required: false
156 - name: unit
157 dtype: text
158 value: volts
159 doc: Unit of measurement. This value is fixed to 'volts'.
160- name: waveforms_index
161 neurodata_type_inc: VectorIndex
162 doc: Index into the 'waveforms' dataset. One value for every spike event. See
163 'waveforms' for more detail.
164 quantity: '?'
165- name: waveforms_index_index
166 neurodata_type_inc: VectorIndex
167 doc: Index into the 'waveforms_index' dataset. One value for every unit (row
168 in the table). See 'waveforms' for more detail.
169 quantity: '?'
3.9. Behavior
This source module contains neurodata_types for behavior data.
3.9.1. SpatialSeries
Extends: TimeSeries
Description: see Section 2.8.1
YAML Specification:
1neurodata_type_def: SpatialSeries
2neurodata_type_inc: TimeSeries
3doc: "Direction, e.g., of gaze or travel, or position. The TimeSeries::data field
4 is a 2-D array storing position or direction relative to some reference frame. Array
5 structure: [num measurements] [num dimensions]. Each SpatialSeries has a text dataset
6 reference_frame that indicates the zero-position, or the zero-axes for direction.
7 For example, if representing gaze direction, 'straight-ahead' might be a specific
8 pixel on the monitor, or some other point in space. For position data, the 0,0 point
9 might be the top-left corner of an enclosure, as viewed from the tracking camera.
10 The unit of data will indicate how to interpret SpatialSeries values."
11datasets:
12- name: data
13 dtype: numeric
14 dims:
15 - - num_times
16 - - num_times
17 - x
18 - - num_times
19 - x,y
20 - - num_times
21 - x,y,z
22 shape:
23 - - null
24 - - null
25 - 1
26 - - null
27 - 2
28 - - null
29 - 3
30 doc: 1-D or 2-D array storing position or direction relative to some reference
31 frame.
32 attributes:
33 - name: unit
34 dtype: text
35 default_value: meters
36 doc: Base unit of measurement for working with the data. The default value
37 is 'meters'. Actual stored values are not necessarily stored in these
38 units. To access the data in these units, multiply 'data' by 'conversion'
39 and add 'offset'.
40 required: false
41- name: reference_frame
42 dtype: text
43 doc: Description defining what exactly 'straight-ahead' means.
44 quantity: '?'
3.9.2. BehavioralEpochs
Extends: NWBDataInterface
Description: see Section 2.8.2
YAML Specification:
1neurodata_type_def: BehavioralEpochs
2neurodata_type_inc: NWBDataInterface
3default_name: BehavioralEpochs
4doc: TimeSeries for storing behavioral epochs. The objective of this and the
5 other two Behavioral interfaces (e.g., BehavioralEvents and
6 BehavioralTimeSeries) is to provide generic hooks for software tools/scripts.
7 This allows a tool/script to take the output of one specific interface (e.g.,
8 UnitTimes) and plot that data relative to another data modality (e.g.,
9 behavioral events) without having to define all possible modalities in
10 advance. Declaring one of these interfaces means that one or more TimeSeries
11 of the specified type are published. These TimeSeries should reside in a group
12 having the same name as the interface. For example, if a BehavioralTimeSeries
13 interface is declared, the module will have one or more TimeSeries defined in
14 the module sub-group 'BehavioralTimeSeries'. BehavioralEpochs should use
15 IntervalSeries. BehavioralEvents is used for irregular events.
16 BehavioralTimeSeries is for continuous data.
17groups:
18- neurodata_type_inc: IntervalSeries
19 doc: IntervalSeries object containing start and stop times of epochs.
20 quantity: +
3.9.3. BehavioralEvents
Extends: NWBDataInterface
Description: see Section 2.8.3
YAML Specification:
1neurodata_type_def: BehavioralEvents
2neurodata_type_inc: NWBDataInterface
3default_name: BehavioralEvents
4doc: 'DEPRECATED. Use an `EventsTable` instead, placed in the top-level `/events`
5 group of the `NWBFile`. Each `TimeSeries` formerly stored under `BehavioralEvents`
6 becomes one `EventsTable`. The `timestamps` field maps to the `timestamp` column,
7 and the `data` field maps to an additional column named after the event marker (e.g.,
8 `reward_magnitude`, `port_number`); for multi-dimensional `data`, use one column
9 per field. Any other per-event metadata becomes additional columns. Use the `source_description`
10 attribute on the `EventsTable` to record where the events came from (e.g., "Acquisition
11 system", "Thresholding of analog signal ANALOG1 at 3 V", "Manual video review").
12 Original definition: TimeSeries for storing behavioral events. See description of
13 BehavioralEpochs for more details.'
14groups:
15- neurodata_type_inc: TimeSeries
16 doc: TimeSeries object containing behavioral events.
17 quantity: +
3.9.4. BehavioralTimeSeries
Extends: NWBDataInterface
Description: see Section 2.8.4
YAML Specification:
1neurodata_type_def: BehavioralTimeSeries
2neurodata_type_inc: NWBDataInterface
3default_name: BehavioralTimeSeries
4doc: TimeSeries for storing behavioral time series data. See description of
5 BehavioralEpochs for more details.
6groups:
7- neurodata_type_inc: TimeSeries
8 doc: TimeSeries object containing continuous behavioral data.
9 quantity: +
3.9.5. PupilTracking
Extends: NWBDataInterface
Description: see Section 2.8.5
YAML Specification:
1neurodata_type_def: PupilTracking
2neurodata_type_inc: NWBDataInterface
3default_name: PupilTracking
4doc: Eye-tracking data, representing pupil size.
5groups:
6- neurodata_type_inc: TimeSeries
7 doc: TimeSeries object containing time series data on pupil size.
8 quantity: +
3.9.6. EyeTracking
Extends: NWBDataInterface
Description: see Section 2.8.6
YAML Specification:
1neurodata_type_def: EyeTracking
2neurodata_type_inc: NWBDataInterface
3default_name: EyeTracking
4doc: Eye-tracking data, representing direction of gaze.
5groups:
6- neurodata_type_inc: SpatialSeries
7 doc: SpatialSeries object containing data measuring direction of gaze.
8 quantity: +
3.9.7. CompassDirection
Extends: NWBDataInterface
Description: see Section 2.8.7
YAML Specification:
1neurodata_type_def: CompassDirection
2neurodata_type_inc: NWBDataInterface
3default_name: CompassDirection
4doc: With a CompassDirection interface, a module publishes a SpatialSeries
5 object representing a floating point value for theta. The
6 SpatialSeries::reference_frame field should indicate what direction
7 corresponds to 0 and which is the direction of rotation (this should be
8 clockwise). The unit for the SpatialSeries should be radians or degrees.
9groups:
10- neurodata_type_inc: SpatialSeries
11 doc: SpatialSeries object containing direction of gaze travel.
12 quantity: +
3.9.8. Position
Extends: NWBDataInterface
Description: see Section 2.8.8
YAML Specification:
1neurodata_type_def: Position
2neurodata_type_inc: NWBDataInterface
3default_name: Position
4doc: Position data, whether along the x, x/y, or x/y/z axes.
5groups:
6- neurodata_type_inc: SpatialSeries
7 doc: SpatialSeries object containing position data.
8 quantity: +
3.10. Extracellular electrophysiology
This source module contains neurodata_types for extracellular electrophysiology data.
3.10.1. ElectricalSeries
Extends: TimeSeries
Description: see Section 2.9.1
YAML Specification:
1neurodata_type_def: ElectricalSeries
2neurodata_type_inc: TimeSeries
3doc: A time series of acquired voltage data from extracellular recordings. The
4 data field is an int or float array storing data in volts. The first dimension
5 should always represent time. The second dimension, if present, should
6 represent channels.
7attributes:
8- name: filtering
9 dtype: text
10 doc: Filtering applied to all channels of the data. For example, if this
11 ElectricalSeries represents high-pass-filtered data (also known as AP Band),
12 then this value could be "High-pass 4-pole Bessel filter at 500 Hz". If this
13 ElectricalSeries represents low-pass-filtered LFP data and the type of
14 filter is unknown, then this value could be "Low-pass filter at 300 Hz". If
15 a non-standard filter type is used, provide as much detail about the filter
16 properties as possible.
17 required: false
18datasets:
19- name: data
20 dtype: numeric
21 dims:
22 - - num_times
23 - - num_times
24 - num_channels
25 - - num_times
26 - num_channels
27 - num_samples
28 shape:
29 - - null
30 - - null
31 - null
32 - - null
33 - null
34 - null
35 doc: Recorded voltage data.
36 attributes:
37 - name: unit
38 dtype: text
39 value: volts
40 doc: Base unit of measurement for working with the data. This value is fixed
41 to 'volts'. Actual stored values are not necessarily stored in these
42 units. To access the data in these units, multiply 'data' by 'conversion',
43 followed by 'channel_conversion' (if present), and then add 'offset'.
44- name: electrodes
45 neurodata_type_inc: DynamicTableRegion
46 doc: DynamicTableRegion pointer to the electrodes that this time series was
47 generated from.
48- name: channel_conversion
49 dtype: float32
50 dims:
51 - num_channels
52 shape:
53 - null
54 doc: Channel-specific conversion factor. Multiply the data in the 'data'
55 dataset by these values along the channel axis (as indicated by axis
56 attribute) AND by the global conversion factor in the 'conversion' attribute
57 of 'data' to get the data values in Volts, i.e., data in Volts = data *
58 data.conversion * channel_conversion. This approach allows for both global
59 and per-channel data conversion factors needed to support the storage of
60 electrical recordings as native values generated by data acquisition
61 systems. If this dataset is not present, then there is no channel-specific
62 conversion factor, i.e., it is 1 for all channels.
63 quantity: '?'
64 attributes:
65 - name: axis
66 dtype: int32
67 value: 1
68 doc: The zero-indexed axis of the 'data' dataset that the channel-specific
69 conversion factor corresponds to. This value is fixed to 1.
3.10.2. SpikeEventSeries
Extends: ElectricalSeries
Description: see Section 2.9.2
YAML Specification:
1neurodata_type_def: SpikeEventSeries
2neurodata_type_inc: ElectricalSeries
3doc: 'Stores snapshots/snippets of recorded spike events (i.e., threshold crossings).
4 This may also be raw data, as reported by ephys hardware. If so, the TimeSeries::description
5 field should describe how events were detected. All events span the same recording
6 channels and store snapshots of equal duration. TimeSeries::data array structure:
7 [num events] [num channels] [num samples] (or [num events] [num samples] for single
8 electrode).'
9datasets:
10- name: data
11 dtype: numeric
12 dims:
13 - - num_events
14 - num_samples
15 - - num_events
16 - num_channels
17 - num_samples
18 shape:
19 - - null
20 - null
21 - - null
22 - null
23 - null
24 doc: Spike waveforms.
25 attributes:
26 - name: unit
27 dtype: text
28 value: volts
29 doc: Unit of measurement for waveforms, which is fixed to 'volts'.
30- name: timestamps
31 dtype: float64
32 dims:
33 - num_times
34 shape:
35 - null
36 doc: Timestamps for samples stored in data, in seconds, relative to the common
37 experiment master-clock stored in NWBFile.timestamps_reference_time.
38 Timestamps are required for the events. Unlike for TimeSeries, timestamps
39 are required for SpikeEventSeries and are thus re-specified here.
40 attributes:
41 - name: interval
42 dtype: int32
43 value: 1
44 doc: Value is '1'
45 - name: unit
46 dtype: text
47 value: seconds
48 doc: Unit of measurement for timestamps, which is fixed to 'seconds'.
3.10.3. FeatureExtraction
Extends: NWBDataInterface
Description: see Section 2.9.3
YAML Specification:
1neurodata_type_def: FeatureExtraction
2neurodata_type_inc: NWBDataInterface
3default_name: FeatureExtraction
4doc: Features, such as PC1 and PC2, that are extracted from signals stored in a
5 SpikeEventSeries or other source.
6datasets:
7- name: description
8 dtype: text
9 dims:
10 - num_features
11 shape:
12 - null
13 doc: Description of features (e.g., ''PC1'') for each of the extracted
14 features.
15- name: features
16 dtype: float32
17 dims:
18 - num_events
19 - num_channels
20 - num_features
21 shape:
22 - null
23 - null
24 - null
25 doc: Multi-dimensional array of features extracted from each event.
26- name: times
27 dtype: float64
28 dims:
29 - num_events
30 shape:
31 - null
32 doc: Times of events that features correspond to (can be a link).
33- name: electrodes
34 neurodata_type_inc: DynamicTableRegion
35 doc: DynamicTableRegion pointer to the electrodes that this time series was
36 generated from.
3.10.4. EventDetection
Extends: NWBDataInterface
Description: see Section 2.9.4
YAML Specification:
1neurodata_type_def: EventDetection
2neurodata_type_inc: NWBDataInterface
3default_name: EventDetection
4doc: Detected spike events from voltage trace(s).
5datasets:
6- name: detection_method
7 dtype: text
8 doc: Description of how events were detected, such as voltage threshold, or
9 dV/dT threshold, as well as relevant values.
10- name: source_idx
11 dtype: int32
12 dims:
13 - - num_events
14 - - num_events
15 - time_index, channel_index
16 shape:
17 - - null
18 - - null
19 - 2
20 doc: Indices (zero-based) into the linked source ElectricalSeries::data array
21 corresponding to the time of each event, or the time and channel of each
22 event. ''description'' should define what is meant by time of event (e.g.,
23 .25 ms before action potential peak, zero-crossing time, etc.). The index
24 points to each event from the raw data.
25- name: times
26 dtype: float64
27 dims:
28 - num_events
29 shape:
30 - null
31 doc: DEPRECATED. Timestamps of events, in seconds.
32 quantity: '?'
33 attributes:
34 - name: unit
35 dtype: text
36 value: seconds
37 doc: Unit of measurement for event times, which is fixed to 'seconds'.
38links:
39- name: source_electricalseries
40 target_type: ElectricalSeries
41 doc: Link to the ElectricalSeries that this data was calculated from. Metadata
42 about electrodes and their position can be read from that ElectricalSeries
43 so it is not necessary to include that information here.
3.10.5. EventWaveform
Extends: NWBDataInterface
Description: see Section 2.9.5
YAML Specification:
1neurodata_type_def: EventWaveform
2neurodata_type_inc: NWBDataInterface
3default_name: EventWaveform
4doc: DEPRECATED. Represents either the waveforms of detected events, as
5 extracted from a raw data trace in /acquisition, or the event waveforms that
6 were stored during experiment acquisition.
7groups:
8- neurodata_type_inc: SpikeEventSeries
9 doc: SpikeEventSeries object(s) containing detected spike event waveforms.
10 quantity: +
3.10.6. FilteredEphys
Extends: NWBDataInterface
Description: see Section 2.9.6
YAML Specification:
1neurodata_type_def: FilteredEphys
2neurodata_type_inc: NWBDataInterface
3default_name: FilteredEphys
4doc: Electrophysiology data from one or more channels that has been subjected to
5 filtering. Examples of filtered data include Theta and Gamma (LFP has its own
6 interface). FilteredEphys modules publish an ElectricalSeries for each
7 filtered channel or set of channels. The name of each ElectricalSeries is
8 arbitrary but should be informative. The source of the filtered data, whether
9 this is from analysis of another time series or as acquired by hardware,
10 should be noted in the TimeSeries::description field of each ElectricalSeries.
11 There is no assumed 1:1 correspondence between filtered ephys signals and
12 electrodes, as a single signal can apply to many nearby electrodes, and one
13 electrode may have different filtered (e.g., theta and/or gamma) signals
14 represented. Filter properties should be noted in the ElectricalSeries
15 'filtering' attribute.
16groups:
17- neurodata_type_inc: ElectricalSeries
18 doc: ElectricalSeries object(s) containing filtered electrophysiology data.
19 quantity: +
3.10.7. LFP
Extends: NWBDataInterface
Description: see Section 2.9.7
YAML Specification:
1neurodata_type_def: LFP
2neurodata_type_inc: NWBDataInterface
3default_name: LFP
4doc: LFP data from one or more channels. The electrode map in each published
5 ElectricalSeries will identify which channels are providing LFP data. Filter
6 properties should be noted in the ElectricalSeries 'filtering' attribute.
7groups:
8- neurodata_type_inc: ElectricalSeries
9 doc: ElectricalSeries object(s) containing LFP data for one or more channels.
10 quantity: +
3.10.8. ElectrodeGroup
Extends: NWBContainer
Description: see Section 2.9.8
YAML Specification:
1neurodata_type_def: ElectrodeGroup
2neurodata_type_inc: NWBContainer
3doc: A physical grouping of electrodes, e.g., a shank of an array. An electrode
4 group is typically used to describe electrodes that are physically connected
5 on a single device and are often (but not always) used together for analysis,
6 such as for spike sorting. Note that this is descriptive metadata; electrodes
7 from different groups can still be spike-sorted together if needed.
8attributes:
9- name: description
10 dtype: text
11 doc: Description of this electrode group.
12- name: location
13 dtype: text
14 doc: Location of electrode group. Specify the area, layer, comments on
15 estimation of area/layer, etc. Use standard atlas names for anatomical
16 regions when possible.
17datasets:
18- name: position
19 dtype:
20 - name: x
21 dtype: float32
22 doc: x coordinate
23 - name: y
24 dtype: float32
25 doc: y coordinate
26 - name: z
27 dtype: float32
28 doc: z coordinate
29 doc: Stereotaxic or common framework coordinates of the electrode group
30 position.
31 quantity: '?'
32links:
33- name: device
34 target_type: Device
35 doc: Link to the device that was used to record from this electrode group.
3.10.9. ElectrodesTable
Extends: DynamicTable
Description: see Section 2.9.9
YAML Specification:
1neurodata_type_def: ElectrodesTable
2neurodata_type_inc: DynamicTable
3doc: A table of all electrodes (i.e., channels) used for recording. Introduced
4 in NWB 2.8.0. Replaces the "electrodes" table (neurodata_type_inc
5 DynamicTable, no neurodata_type_def) that is part of NWBFile.
6datasets:
7- name: location
8 neurodata_type_inc: VectorData
9 dtype: text
10 doc: Location of the electrode (channel). Specify the area, layer, comments on
11 estimation of area/layer, stereotaxic coordinates if in vivo, etc. Use
12 standard atlas names for anatomical regions when possible.
13- name: group
14 neurodata_type_inc: VectorData
15 dtype:
16 target_type: ElectrodeGroup
17 reftype: object
18 doc: Reference to the ElectrodeGroup this electrode is a part of.
19- name: group_name
20 neurodata_type_inc: VectorData
21 dtype: text
22 doc: Name of the ElectrodeGroup this electrode is a part of.
23 quantity: '?'
24- name: x
25 neurodata_type_inc: VectorData
26 dtype: float32
27 doc: x coordinate of the channel location in the brain (+x is posterior).
28 Units should be specified in microns.
29 quantity: '?'
30- name: y
31 neurodata_type_inc: VectorData
32 dtype: float32
33 doc: y coordinate of the channel location in the brain (+y is inferior). Units
34 should be specified in microns.
35 quantity: '?'
36- name: z
37 neurodata_type_inc: VectorData
38 dtype: float32
39 doc: z coordinate of the channel location in the brain (+z is right). Units
40 should be specified in microns.
41 quantity: '?'
42- name: imp
43 neurodata_type_inc: VectorData
44 dtype: float32
45 doc: Impedance of the channel, in ohms.
46 quantity: '?'
47- name: filtering
48 neurodata_type_inc: VectorData
49 dtype: text
50 doc: Description of hardware filtering, including the filter name and
51 frequency cutoffs.
52 quantity: '?'
53- name: rel_x
54 neurodata_type_inc: VectorData
55 dtype: float32
56 doc: x coordinate in electrode group. Units should be specified in microns.
57 quantity: '?'
58- name: rel_y
59 neurodata_type_inc: VectorData
60 dtype: float32
61 doc: y coordinate in electrode group. Units should be specified in microns.
62 quantity: '?'
63- name: rel_z
64 neurodata_type_inc: VectorData
65 dtype: float32
66 doc: z coordinate in electrode group. Units should be specified in microns.
67 quantity: '?'
68- name: reference
69 neurodata_type_inc: VectorData
70 dtype: text
71 doc: Description of the reference electrode and/or reference scheme used for
72 this electrode, e.g., "stainless steel skull screw" or "online common
73 average referencing".
74 quantity: '?'
3.10.10. ClusterWaveforms
Extends: NWBDataInterface
Description: see Section 2.9.10
YAML Specification:
1neurodata_type_def: ClusterWaveforms
2neurodata_type_inc: NWBDataInterface
3default_name: ClusterWaveforms
4doc: DEPRECATED. The mean waveform shape, including standard deviation, of the
5 different clusters. Ideally, the waveform analysis should be performed on data
6 that is only high-pass filtered. This is a separate module because it is
7 expected to require updating. For example, IMEC probes may require different
8 storage requirements to store/display mean waveforms, requiring a new
9 interface or an extension of this one.
10datasets:
11- name: waveform_filtering
12 dtype: text
13 doc: Filtering applied to data before generating mean/sd
14- name: waveform_mean
15 dtype: float32
16 dims:
17 - num_clusters
18 - num_samples
19 shape:
20 - null
21 - null
22 doc: The mean waveform for each cluster, using the same indices for each wave
23 as cluster numbers in the associated Clustering module (i.e., cluster 3 is
24 in array slot [3]). Waveforms corresponding to gaps in cluster sequence
25 should be empty (e.g., zero-filled).
26- name: waveform_sd
27 dtype: float32
28 dims:
29 - num_clusters
30 - num_samples
31 shape:
32 - null
33 - null
34 doc: Stdev of waveforms for each cluster, using the same indices as in mean.
35links:
36- name: clustering_interface
37 target_type: Clustering
38 doc: Link to Clustering interface that was the source of the clustered data.
3.10.11. Clustering
Extends: NWBDataInterface
Description: see Section 2.9.11
YAML Specification:
1neurodata_type_def: Clustering
2neurodata_type_inc: NWBDataInterface
3default_name: Clustering
4doc: DEPRECATED. Clustered spike data, whether from automatic clustering tools
5 (e.g., klustakwik) or as a result of manual sorting.
6datasets:
7- name: description
8 dtype: text
9 doc: Description of clusters or clustering (e.g., cluster 0 is noise, clusters
10 curated using Klusters, etc.).
11- name: num
12 dtype: int32
13 dims:
14 - num_events
15 shape:
16 - null
17 doc: Cluster number of each event
18- name: peak_over_rms
19 dtype: float32
20 dims:
21 - num_clusters
22 shape:
23 - null
24 doc: Maximum ratio of waveform peak to RMS on any channel in the cluster
25 (provides a basic clustering metric).
26- name: times
27 dtype: float64
28 dims:
29 - num_events
30 shape:
31 - null
32 doc: Times of clustered events, in seconds. This may be a link to times field
33 in associated FeatureExtraction module.
3.11. Intracellular electrophysiology
This source module contains neurodata_types for intracellular electrophysiology data.
3.11.1. PatchClampSeries
Extends: TimeSeries
Description: see Section 2.10.1
YAML Specification:
1neurodata_type_def: PatchClampSeries
2neurodata_type_inc: TimeSeries
3doc: An abstract base class for patch-clamp data - stimulus or response, current
4 or voltage.
5attributes:
6- name: stimulus_description
7 dtype: text
8 doc: Protocol/stimulus name for this patch-clamp dataset.
9- name: sweep_number
10 dtype: uint32
11 doc: Sweep number, allows users to group different PatchClampSeries together.
12 required: false
13datasets:
14- name: data
15 dtype: numeric
16 dims:
17 - num_times
18 shape:
19 - null
20 doc: Recorded voltage or current.
21 attributes:
22 - name: unit
23 dtype: text
24 doc: Base unit of measurement for working with the data. Actual stored
25 values are not necessarily stored in these units. To access the data in
26 these units, multiply 'data' by 'conversion' and add 'offset'.
27- name: gain
28 dtype: float32
29 doc: Gain of the recording, in units Volt/Amp (v-clamp) or Volt/Volt
30 (c-clamp).
31 quantity: '?'
32links:
33- name: electrode
34 target_type: IntracellularElectrode
35 doc: Link to IntracellularElectrode object that describes the electrode that
36 was used to apply or record this data.
3.11.2. CurrentClampSeries
Extends: PatchClampSeries
Description: see Section 2.10.2
YAML Specification:
1neurodata_type_def: CurrentClampSeries
2neurodata_type_inc: PatchClampSeries
3doc: Voltage data from an intracellular current-clamp recording. A corresponding
4 CurrentClampStimulusSeries (stored separately as a stimulus) is used to store
5 the current injected.
6datasets:
7- name: data
8 doc: Recorded voltage.
9 attributes:
10 - name: unit
11 dtype: text
12 value: volts
13 doc: Base unit of measurement for working with the data, which is fixed to
14 'volts'. Actual stored values are not necessarily stored in these units.
15 To access the data in these units, multiply 'data' by 'conversion' and add
16 'offset'.
17- name: bias_current
18 dtype: float32
19 doc: Bias current, in amperes.
20 quantity: '?'
21- name: bridge_balance
22 dtype: float32
23 doc: Bridge balance, in ohms.
24 quantity: '?'
25- name: capacitance_compensation
26 dtype: float32
27 doc: Capacitance compensation, in farads.
28 quantity: '?'
3.11.3. IZeroClampSeries
Extends: CurrentClampSeries
Description: see Section 2.10.3
YAML Specification:
1neurodata_type_def: IZeroClampSeries
2neurodata_type_inc: CurrentClampSeries
3doc: Voltage data from an intracellular recording when all current and amplifier
4 settings are off (i.e., CurrentClampSeries fields will be zero). There is no
5 CurrentClampStimulusSeries associated with an IZero series because the
6 amplifier is disconnected and no stimulus can reach the cell.
7attributes:
8- name: stimulus_description
9 dtype: text
10 value: N/A
11 doc: An IZeroClampSeries has no stimulus, so this attribute is automatically
12 set to "N/A".
13datasets:
14- name: bias_current
15 dtype: float32
16 value: 0.0
17 doc: Bias current, in amperes, fixed to 0.0.
18- name: bridge_balance
19 dtype: float32
20 value: 0.0
21 doc: Bridge balance, in ohms, fixed to 0.0.
22- name: capacitance_compensation
23 dtype: float32
24 value: 0.0
25 doc: Capacitance compensation, in farads, fixed to 0.0.
3.11.4. CurrentClampStimulusSeries
Extends: PatchClampSeries
Description: see Section 2.10.4
YAML Specification:
1neurodata_type_def: CurrentClampStimulusSeries
2neurodata_type_inc: PatchClampSeries
3doc: Stimulus current applied during current clamp recording.
4datasets:
5- name: data
6 doc: Stimulus current applied.
7 attributes:
8 - name: unit
9 dtype: text
10 value: amperes
11 doc: Base unit of measurement for working with the data, which is fixed to
12 'amperes'. Actual stored values are not necessarily stored in these units.
13 To access the data in these units, multiply 'data' by 'conversion' and add
14 'offset'.
3.11.5. VoltageClampSeries
Extends: PatchClampSeries
Description: see Section 2.10.5
YAML Specification:
1neurodata_type_def: VoltageClampSeries
2neurodata_type_inc: PatchClampSeries
3doc: Current data from an intracellular voltage-clamp recording. A corresponding
4 VoltageClampStimulusSeries (stored separately as a stimulus) is used to store
5 the voltage injected.
6datasets:
7- name: data
8 doc: Recorded current.
9 attributes:
10 - name: unit
11 dtype: text
12 value: amperes
13 doc: Base unit of measurement for working with the data, which is fixed to
14 'amperes'. Actual stored values are not necessarily stored in these units.
15 To access the data in these units, multiply 'data' by 'conversion' and add
16 'offset'.
17- name: capacitance_fast
18 dtype: float32
19 doc: Fast capacitance, in farads.
20 quantity: '?'
21 attributes:
22 - name: unit
23 dtype: text
24 value: farads
25 doc: Unit of measurement for capacitance_fast, which is fixed to 'farads'.
26- name: capacitance_slow
27 dtype: float32
28 doc: Slow capacitance, in farads.
29 quantity: '?'
30 attributes:
31 - name: unit
32 dtype: text
33 value: farads
34 doc: Unit of measurement for capacitance_slow, which is fixed to 'farads'.
35- name: resistance_comp_bandwidth
36 dtype: float32
37 doc: Resistance compensation bandwidth, in hertz.
38 quantity: '?'
39 attributes:
40 - name: unit
41 dtype: text
42 value: hertz
43 doc: Unit of measurement for resistance_comp_bandwidth, which is fixed to
44 'hertz'.
45- name: resistance_comp_correction
46 dtype: float32
47 doc: Resistance compensation correction, in percent.
48 quantity: '?'
49 attributes:
50 - name: unit
51 dtype: text
52 value: percent
53 doc: Unit of measurement for resistance_comp_correction, which is fixed to
54 'percent'.
55- name: resistance_comp_prediction
56 dtype: float32
57 doc: Resistance compensation prediction, in percent.
58 quantity: '?'
59 attributes:
60 - name: unit
61 dtype: text
62 value: percent
63 doc: Unit of measurement for resistance_comp_prediction, which is fixed to
64 'percent'.
65- name: whole_cell_capacitance_comp
66 dtype: float32
67 doc: Whole cell capacitance compensation, in farads.
68 quantity: '?'
69 attributes:
70 - name: unit
71 dtype: text
72 value: farads
73 doc: Unit of measurement for whole_cell_capacitance_comp, which is fixed to
74 'farads'.
75- name: whole_cell_series_resistance_comp
76 dtype: float32
77 doc: Whole cell series resistance compensation, in ohms.
78 quantity: '?'
79 attributes:
80 - name: unit
81 dtype: text
82 value: ohms
83 doc: Unit of measurement for whole_cell_series_resistance_comp, which is
84 fixed to 'ohms'.
3.11.6. VoltageClampStimulusSeries
Extends: PatchClampSeries
Description: see Section 2.10.6
YAML Specification:
1neurodata_type_def: VoltageClampStimulusSeries
2neurodata_type_inc: PatchClampSeries
3doc: Stimulus voltage applied during a voltage clamp recording.
4datasets:
5- name: data
6 doc: Stimulus voltage applied.
7 attributes:
8 - name: unit
9 dtype: text
10 value: volts
11 doc: Base unit of measurement for working with the data, which is fixed to
12 'volts'. Actual stored values are not necessarily stored in these units.
13 To access the data in these units, multiply 'data' by 'conversion' and add
14 'offset'.
3.11.7. IntracellularElectrode
Extends: NWBContainer
Description: see Section 2.10.7
YAML Specification:
1neurodata_type_def: IntracellularElectrode
2neurodata_type_inc: NWBContainer
3doc: An intracellular electrode and its metadata.
4datasets:
5- name: cell_id
6 dtype: text
7 doc: Unique identifier of the cell.
8 quantity: '?'
9- name: description
10 dtype: text
11 doc: Description of electrode (e.g., whole-cell, sharp, etc.).
12- name: filtering
13 dtype: text
14 doc: Electrode specific filtering.
15 quantity: '?'
16- name: initial_access_resistance
17 dtype: text
18 doc: Initial access resistance.
19 quantity: '?'
20- name: location
21 dtype: text
22 doc: Location of the electrode. Specify the area, layer, comments on
23 estimation of area/layer, stereotaxic coordinates if in vivo, etc. Use
24 standard atlas names for anatomical regions when possible.
25 quantity: '?'
26- name: resistance
27 dtype: text
28 doc: Electrode resistance, in ohms.
29 quantity: '?'
30- name: seal
31 dtype: text
32 doc: Information about seal used for recording.
33 quantity: '?'
34- name: slice
35 dtype: text
36 doc: Information about slice used for recording.
37 quantity: '?'
38links:
39- name: device
40 target_type: Device
41 doc: Device that was used to record from this electrode.
3.11.8. SweepTable
Extends: DynamicTable
Description: see Section 2.10.8
YAML Specification:
1neurodata_type_def: SweepTable
2neurodata_type_inc: DynamicTable
3doc: '[DEPRECATED] Table used to group different PatchClampSeries. SweepTable is being
4 replaced by IntracellularRecordingsTable and SimultaneousRecordingsTable tables.
5 Additional SequentialRecordingsTable, RepetitionsTable, and ExperimentalConditions
6 tables provide enhanced support for experiment metadata.'
7datasets:
8- name: sweep_number
9 neurodata_type_inc: VectorData
10 dtype: uint32
11 doc: Sweep number of the PatchClampSeries in that row.
12- name: series
13 neurodata_type_inc: VectorData
14 dtype:
15 target_type: PatchClampSeries
16 reftype: object
17 doc: The PatchClampSeries with the sweep number in that row.
18- name: series_index
19 neurodata_type_inc: VectorIndex
20 doc: Index for series.
3.11.9. IntracellularElectrodesTable
Extends: DynamicTable
Description: see Section 2.10.9
YAML Specification:
1neurodata_type_def: IntracellularElectrodesTable
2neurodata_type_inc: DynamicTable
3doc: Table for storing intracellular electrode related metadata.
4attributes:
5- name: description
6 dtype: text
7 value: Table for storing intracellular electrode related metadata.
8 doc: Description of what is in this dynamic table.
9datasets:
10- name: electrode
11 neurodata_type_inc: VectorData
12 dtype:
13 target_type: IntracellularElectrode
14 reftype: object
15 doc: Column for storing the reference to the intracellular electrode.
3.11.10. IntracellularStimuliTable
Extends: DynamicTable
Description: see Section 2.10.10
YAML Specification:
1neurodata_type_def: IntracellularStimuliTable
2neurodata_type_inc: DynamicTable
3doc: Table for storing intracellular stimulus related metadata.
4attributes:
5- name: description
6 dtype: text
7 value: Table for storing intracellular stimulus related metadata.
8 doc: Description of what is in this dynamic table.
9datasets:
10- name: stimulus
11 neurodata_type_inc: TimeSeriesReferenceVectorData
12 doc: Column storing the reference to the recorded stimulus for the recording
13 (rows).
14- name: stimulus_template
15 neurodata_type_inc: TimeSeriesReferenceVectorData
16 doc: Column storing the reference to the stimulus template for the recording
17 (rows).
18 quantity: '?'
3.11.11. IntracellularResponsesTable
Extends: DynamicTable
Description: see Section 2.10.11
YAML Specification:
1neurodata_type_def: IntracellularResponsesTable
2neurodata_type_inc: DynamicTable
3doc: Table for storing intracellular response related metadata.
4attributes:
5- name: description
6 dtype: text
7 value: Table for storing intracellular response related metadata.
8 doc: Description of what is in this dynamic table.
9datasets:
10- name: response
11 neurodata_type_inc: TimeSeriesReferenceVectorData
12 doc: Column storing the reference to the recorded response for the recording
13 (rows).
3.11.12. IntracellularRecordingsTable
Extends: AlignedDynamicTable
Description: see Section 2.10.12
YAML Specification:
1neurodata_type_def: IntracellularRecordingsTable
2neurodata_type_inc: AlignedDynamicTable
3name: intracellular_recordings
4doc: A table to group together a stimulus and response from a single electrode
5 and a single simultaneous recording. Each row in the table represents a single
6 recording consisting typically of a stimulus and a corresponding response. In
7 some cases, however, only a stimulus or a response is recorded as part of an
8 experiment. In this case, both the stimulus and response will point to the
9 same TimeSeries while the idx_start and count of the invalid column will be
10 set to -1, thus, indicating that no values have been recorded for the stimulus
11 or response, respectively. Note, a recording MUST contain at least a stimulus
12 or a response. Typically the stimulus and response are PatchClampSeries.
13 However, the use of AD/DA channels that are not associated to an electrode is
14 also common in intracellular electrophysiology, in which case other TimeSeries
15 may be used.
16attributes:
17- name: description
18 dtype: text
19 value: A table to group together a stimulus and response from a single
20 electrode and a single simultaneous recording and for storing metadata about
21 the intracellular recording.
22 doc: Description of the contents of this table. Inherited from
23 AlignedDynamicTable and overwritten here to fix the value of the attribute.
24groups:
25- name: electrodes
26 neurodata_type_inc: IntracellularElectrodesTable
27 doc: Table for storing intracellular electrode related metadata.
28- name: stimuli
29 neurodata_type_inc: IntracellularStimuliTable
30 doc: Table for storing intracellular stimulus related metadata.
31- name: responses
32 neurodata_type_inc: IntracellularResponsesTable
33 doc: Table for storing intracellular response related metadata.
3.11.13. SimultaneousRecordingsTable
Extends: DynamicTable
Description: see Section 2.10.13
YAML Specification:
1neurodata_type_def: SimultaneousRecordingsTable
2neurodata_type_inc: DynamicTable
3name: simultaneous_recordings
4doc: A table for grouping different intracellular recordings from the
5 IntracellularRecordingsTable table together that were recorded simultaneously
6 from different electrodes.
7datasets:
8- name: recordings
9 neurodata_type_inc: DynamicTableRegion
10 doc: A reference to one or more rows in the IntracellularRecordingsTable
11 table.
12 attributes:
13 - name: table
14 dtype:
15 target_type: IntracellularRecordingsTable
16 reftype: object
17 doc: Reference to the IntracellularRecordingsTable table that this table
18 region applies to. This specializes the attribute inherited from
19 DynamicTableRegion to fix the type of table that can be referenced here.
20- name: recordings_index
21 neurodata_type_inc: VectorIndex
22 doc: Index dataset for the recordings column.
3.11.14. SequentialRecordingsTable
Extends: DynamicTable
Description: see Section 2.10.14
YAML Specification:
1neurodata_type_def: SequentialRecordingsTable
2neurodata_type_inc: DynamicTable
3name: sequential_recordings
4doc: A table for grouping different sequential recordings from the
5 SimultaneousRecordingsTable table together. This is typically used to group
6 together sequential recordings where a sequence of stimuli of the same type
7 with varying parameters have been presented in a sequence.
8datasets:
9- name: simultaneous_recordings
10 neurodata_type_inc: DynamicTableRegion
11 doc: A reference to one or more rows in the SimultaneousRecordingsTable table.
12 attributes:
13 - name: table
14 dtype:
15 target_type: SimultaneousRecordingsTable
16 reftype: object
17 doc: Reference to the SimultaneousRecordingsTable table that this table
18 region applies to. This specializes the attribute inherited from
19 DynamicTableRegion to fix the type of table that can be referenced here.
20- name: simultaneous_recordings_index
21 neurodata_type_inc: VectorIndex
22 doc: Index dataset for the simultaneous_recordings column.
23- name: stimulus_type
24 neurodata_type_inc: VectorData
25 dtype: text
26 doc: The type of stimulus used for the sequential recording.
3.11.15. RepetitionsTable
Extends: DynamicTable
Description: see Section 2.10.15
YAML Specification:
1neurodata_type_def: RepetitionsTable
2neurodata_type_inc: DynamicTable
3name: repetitions
4doc: A table for grouping different sequential intracellular recordings
5 together. With each SequentialRecording typically representing a particular
6 type of stimulus, the RepetitionsTable table is typically used to group sets
7 of stimuli applied in sequence.
8datasets:
9- name: sequential_recordings
10 neurodata_type_inc: DynamicTableRegion
11 doc: A reference to one or more rows in the SequentialRecordingsTable table.
12 attributes:
13 - name: table
14 dtype:
15 target_type: SequentialRecordingsTable
16 reftype: object
17 doc: Reference to the SequentialRecordingsTable table that this table region
18 applies to. This specializes the attribute inherited from
19 DynamicTableRegion to fix the type of table that can be referenced here.
20- name: sequential_recordings_index
21 neurodata_type_inc: VectorIndex
22 doc: Index dataset for the sequential_recordings column.
3.11.16. ExperimentalConditionsTable
Extends: DynamicTable
Description: see Section 2.10.16
YAML Specification:
1neurodata_type_def: ExperimentalConditionsTable
2neurodata_type_inc: DynamicTable
3name: experimental_conditions
4doc: A table for grouping different intracellular recording repetitions together
5 that belong to the same experimental condition.
6datasets:
7- name: repetitions
8 neurodata_type_inc: DynamicTableRegion
9 doc: A reference to one or more rows in the RepetitionsTable table.
10 attributes:
11 - name: table
12 dtype:
13 target_type: RepetitionsTable
14 reftype: object
15 doc: Reference to the RepetitionsTable table that this table region applies
16 to. This specializes the attribute inherited from DynamicTableRegion to
17 fix the type of table that can be referenced here.
18- name: repetitions_index
19 neurodata_type_inc: VectorIndex
20 doc: Index dataset for the repetitions column.
3.12. Optogenetics
This source module contains neurodata_types for optogenetics data.
3.12.1. OptogeneticSeries
Extends: TimeSeries
Description: see Section 2.11.1
YAML Specification:
1neurodata_type_def: OptogeneticSeries
2neurodata_type_inc: TimeSeries
3doc: An optogenetic stimulus.
4datasets:
5- name: data
6 dtype: numeric
7 dims:
8 - - num_times
9 - - num_times
10 - num_rois
11 shape:
12 - - null
13 - - null
14 - null
15 doc: Applied power for optogenetic stimulus, in watts. Shape can be 1-D or
16 2-D. 2-D data is meant to be used in an extension of OptogeneticSeries that
17 defines what the second dimension represents.
18 attributes:
19 - name: unit
20 dtype: text
21 value: watts
22 doc: Unit of measurement for data, which is fixed to 'watts'.
23links:
24- name: site
25 target_type: OptogeneticStimulusSite
26 doc: Link to OptogeneticStimulusSite object that describes the site to which
27 this stimulus was applied.
3.12.2. OptogeneticStimulusSite
Extends: NWBContainer
Description: see Section 2.11.2
YAML Specification:
1neurodata_type_def: OptogeneticStimulusSite
2neurodata_type_inc: NWBContainer
3doc: A site of optogenetic stimulation.
4datasets:
5- name: description
6 dtype: text
7 doc: Description of stimulation site.
8- name: excitation_lambda
9 dtype: float32
10 doc: Excitation wavelength, in nm.
11- name: location
12 dtype: text
13 doc: Location of the stimulation site. Specify the area, layer, comments on
14 estimation of area/layer, stereotaxic coordinates if in vivo, etc. Use
15 standard atlas names for anatomical regions when possible.
16links:
17- name: device
18 target_type: Device
19 doc: Device that generated the stimulus.
3.13. Optical physiology
This source module contains neurodata_types for optical physiology data.
3.13.1. OnePhotonSeries
Extends: ImageSeries
Description: see Section 2.12.1
YAML Specification:
1neurodata_type_def: OnePhotonSeries
2neurodata_type_inc: ImageSeries
3doc: Image stack recorded over time from 1-photon microscope.
4attributes:
5- name: pmt_gain
6 dtype: float32
7 doc: Photomultiplier gain.
8 required: false
9- name: scan_line_rate
10 dtype: float32
11 doc: Lines imaged per second. This is also stored in /general/optophysiology
12 but is kept here as it is useful information for analysis, and is therefore
13 stored with the actual data.
14 required: false
15- name: exposure_time
16 dtype: float32
17 doc: Exposure time of the sample; often the inverse of the frequency.
18 required: false
19- name: binning
20 dtype: uint8
21 doc: Amount of pixels combined into 'bins'; could be 1, 2, 4, 8, etc.
22 required: false
23- name: power
24 dtype: float32
25 doc: Power of the excitation in mW, if known.
26 required: false
27- name: intensity
28 dtype: float32
29 doc: Intensity of the excitation in mW/mm^2, if known.
30 required: false
31datasets:
32- name: data
33 dtype: numeric
34 dims:
35 - - time
36 - width
37 - height
38 - - time
39 - width
40 - height
41 - depth
42 shape:
43 - - null
44 - null
45 - null
46 - - null
47 - null
48 - null
49 - null
50 doc: "Time-series of microscopy data indexed as data[time, width, height].\n\nIndexing
51 convention:\n - width: first spatial axis (horizontal direction, columns)\n \
52 \ - height: second spatial axis (vertical direction, rows)\n\nFor raster-scanning
53 systems (two-photon, confocal, one-photon laser scanning):\n - width: fast scan
54 direction (horizontal)\n - height: slow scan direction (vertical)\n\nCoordinate
55 system diagram::\n\n height ^\n (slow) |\n | +-----------------+\n\
56 \ | | |\n | | Image plane |\n \
57 \ | | |\n | +-----------------+\n \
58 \ |\n 0 ----------------------> width (fast)\n\n\nFor non-raster systems
59 (wide-field, light-sheet, random-access), width and height\nare arbitrary coordinates
60 of the image plane.\n\nNote: This indexing convention conflicts with standard
61 matrix[row, column] notation\nfor array access where the first index moves vertically
62 through rows and the second moves horizontally\nthrough columns. In the schema,
63 data[time, width, height] means that the first spatial\nindex moves horizontally
64 (width) through columns and the second spatial index moves\nvertically (height)
65 through rows. In summary, incrementing the first spatial index\nmoves you horizontally
66 across the image, while in matrix notation it would move you\nvertically across
67 the rows of the image.\n"
68links:
69- name: imaging_plane
70 target_type: ImagingPlane
71 doc: Link to ImagingPlane object from which this TimeSeries data was
72 generated.
3.13.2. TwoPhotonSeries
Extends: ImageSeries
Description: see Section 2.12.2
YAML Specification:
1neurodata_type_def: TwoPhotonSeries
2neurodata_type_inc: ImageSeries
3doc: Image stack recorded over time from 2-photon microscope.
4attributes:
5- name: pmt_gain
6 dtype: float32
7 doc: Photomultiplier gain.
8 required: false
9- name: scan_line_rate
10 dtype: float32
11 doc: Lines imaged per second. This is also stored in /general/optophysiology
12 but is kept here as it is useful information for analysis, and is therefore
13 stored with the actual data.
14 required: false
15datasets:
16- name: data
17 dtype: numeric
18 dims:
19 - - time
20 - width
21 - height
22 - - time
23 - width
24 - height
25 - depth
26 shape:
27 - - null
28 - null
29 - null
30 - - null
31 - null
32 - null
33 - null
34 doc: "Time-series of microscopy data indexed as data[time, width, height].\n\nIndexing
35 convention:\n - width: first spatial axis (horizontal direction, columns)\n \
36 \ - height: second spatial axis (vertical direction, rows)\n\nFor raster-scanning
37 systems (two-photon, confocal, one-photon laser scanning):\n - width: fast scan
38 direction (horizontal)\n - height: slow scan direction (vertical)\n\nCoordinate
39 system diagram::\n\n height ^\n (slow) |\n | +-----------------+\n\
40 \ | | |\n | | Image plane |\n \
41 \ | | |\n | +-----------------+\n \
42 \ |\n 0 ----------------------> width (fast)\n\n\nFor non-raster systems
43 (wide-field, light-sheet, random-access), width and height\nare arbitrary coordinates
44 of the image plane.\n\nNote: This indexing convention conflicts with standard
45 matrix[row, column] notation\nfor array access where the first index moves vertically
46 through rows and the second moves horizontally\nthrough columns. In the schema,
47 data[time, width, height] means that the first spatial\nindex moves horizontally
48 (width) through columns and the second spatial index moves\nvertically (height)
49 through rows.\n"
50- name: field_of_view
51 dtype: float32
52 dims:
53 - - width|height
54 - - width|height|depth
55 shape:
56 - - 2
57 - - 3
58 doc: Physical dimensions of the imaging field of view in width, height, and
59 optionally depth directions, in meters. The width dimension corresponds to
60 the faster scanning axis, and the height dimension corresponds to the slower
61 scanning axis.
62 quantity: '?'
63links:
64- name: imaging_plane
65 target_type: ImagingPlane
66 doc: Link to ImagingPlane object from which this TimeSeries data was
67 generated.
3.13.3. RoiResponseSeries
Extends: TimeSeries
Description: see Section 2.12.3
YAML Specification:
1neurodata_type_def: RoiResponseSeries
2neurodata_type_inc: TimeSeries
3doc: ROI responses over an imaging plane. The first dimension represents time.
4 The second dimension, if present, represents ROIs.
5datasets:
6- name: data
7 dtype: numeric
8 dims:
9 - - num_times
10 - - num_times
11 - num_ROIs
12 shape:
13 - - null
14 - - null
15 - null
16 doc: Signals from ROIs.
17- name: rois
18 neurodata_type_inc: DynamicTableRegion
19 doc: DynamicTableRegion referencing into a PlaneSegmentation table containing
20 information on the ROIs stored in this TimeSeries.
3.13.4. DfOverF
Extends: NWBDataInterface
Description: see Section 2.12.4
YAML Specification:
1neurodata_type_def: DfOverF
2neurodata_type_inc: NWBDataInterface
3default_name: DfOverF
4doc: dF/F information about a region of interest (ROI). Storage hierarchy of
5 dF/F should be the same as for segmentation (i.e., same names for ROIs and for
6 image planes).
7groups:
8- neurodata_type_inc: RoiResponseSeries
9 doc: RoiResponseSeries object(s) containing dF/F for a ROI.
10 quantity: +
3.13.5. Fluorescence
Extends: NWBDataInterface
Description: see Section 2.12.5
YAML Specification:
1neurodata_type_def: Fluorescence
2neurodata_type_inc: NWBDataInterface
3default_name: Fluorescence
4doc: Fluorescence information about a region of interest (ROI). Storage
5 hierarchy of fluorescence should be the same as for segmentation (i.e., same
6 names for ROIs and for image planes).
7groups:
8- neurodata_type_inc: RoiResponseSeries
9 doc: RoiResponseSeries object(s) containing fluorescence data for a ROI.
10 quantity: +
3.13.6. ImageSegmentation
Extends: NWBDataInterface
Description: see Section 2.12.6
YAML Specification:
1neurodata_type_def: ImageSegmentation
2neurodata_type_inc: NWBDataInterface
3default_name: ImageSegmentation
4doc: Stores pixels in an image that represent different regions of interest
5 (ROIs) or masks. All segmentation for a given imaging plane is stored
6 together, with storage for multiple imaging planes (masks) supported. Each ROI
7 is stored in its own subgroup, with the ROI group containing both a 2-D mask
8 and a list of pixels that make up this mask. Segments can also be used for
9 masking neuropil. If segmentation is allowed to change with time, a new
10 imaging plane (or module) is required and ROI names should remain consistent
11 between them.
12groups:
13- neurodata_type_inc: PlaneSegmentation
14 doc: Results from image segmentation of a specific imaging plane.
15 quantity: +
3.13.7. PlaneSegmentation
Extends: DynamicTable
Description: see Section 2.12.7
YAML Specification:
1neurodata_type_def: PlaneSegmentation
2neurodata_type_inc: DynamicTable
3doc: Results from image segmentation of a specific imaging plane. At least one
4 of `image_mask`, `pixel_mask`, or `voxel_mask` is required.
5datasets:
6- name: image_mask
7 neurodata_type_inc: VectorData
8 dims:
9 - - num_roi
10 - num_x
11 - num_y
12 - - num_roi
13 - num_x
14 - num_y
15 - num_z
16 shape:
17 - - null
18 - null
19 - null
20 - - null
21 - null
22 - null
23 - null
24 doc: ROI masks for each ROI. Each image mask is the size of the original
25 imaging plane (or volume) and members of the ROI are finite non-zero. At
26 least one of `image_mask`, `pixel_mask`, or `voxel_mask` is required.
27 quantity: '?'
28- name: pixel_mask_index
29 neurodata_type_inc: VectorIndex
30 doc: Index into pixel_mask.
31 quantity: '?'
32- name: pixel_mask
33 neurodata_type_inc: VectorData
34 dtype:
35 - name: x
36 dtype: uint32
37 doc: Pixel x-coordinate.
38 - name: y
39 dtype: uint32
40 doc: Pixel y-coordinate.
41 - name: weight
42 dtype: float32
43 doc: Weight of the pixel.
44 doc: 'Pixel masks for each ROI: a list of indices and weights for the ROI. Pixel
45 masks are concatenated and parsing of this dataset is maintained by the PlaneSegmentation.
46 At least one of `image_mask`, `pixel_mask`, or `voxel_mask` is required.'
47 quantity: '?'
48- name: voxel_mask_index
49 neurodata_type_inc: VectorIndex
50 doc: Index into voxel_mask.
51 quantity: '?'
52- name: voxel_mask
53 neurodata_type_inc: VectorData
54 dtype:
55 - name: x
56 dtype: uint32
57 doc: Voxel x-coordinate.
58 - name: y
59 dtype: uint32
60 doc: Voxel y-coordinate.
61 - name: z
62 dtype: uint32
63 doc: Voxel z-coordinate.
64 - name: weight
65 dtype: float32
66 doc: Weight of the voxel.
67 doc: 'Voxel masks for each ROI: a list of indices and weights for the ROI. Voxel
68 masks are concatenated and parsing of this dataset is maintained by the PlaneSegmentation.
69 At least one of `image_mask`, `pixel_mask`, or `voxel_mask` is required.'
70 quantity: '?'
71groups:
72- name: reference_images
73 doc: Image stacks that the segmentation masks apply to.
74 groups:
75 - neurodata_type_inc: ImageSeries
76 doc: One or more image stacks that the masks apply to (can be one-element
77 stack).
78 quantity: '*'
79links:
80- name: imaging_plane
81 target_type: ImagingPlane
82 doc: Link to ImagingPlane object from which this data was generated.
3.13.8. ImagingPlane
Extends: NWBContainer
Description: see Section 2.12.8
YAML Specification:
1neurodata_type_def: ImagingPlane
2neurodata_type_inc: NWBContainer
3doc: An imaging plane and its metadata.
4datasets:
5- name: description
6 dtype: text
7 doc: Description of the imaging plane.
8 quantity: '?'
9- name: excitation_lambda
10 dtype: float32
11 doc: Excitation wavelength, in nm.
12- name: imaging_rate
13 dtype: float32
14 doc: Rate that images are acquired, in Hz. If the corresponding TimeSeries is
15 present, the rate should be stored there instead.
16 quantity: '?'
17- name: indicator
18 dtype: text
19 doc: Calcium indicator.
20- name: location
21 dtype: text
22 doc: Location of the imaging plane. Specify the area, layer, comments on
23 estimation of area/layer, stereotaxic coordinates if in vivo, etc. Use
24 standard atlas names for anatomical regions when possible.
25- name: manifold
26 dtype: float32
27 dims:
28 - - height
29 - width
30 - x, y, z
31 - - height
32 - width
33 - depth
34 - x, y, z
35 shape:
36 - - null
37 - null
38 - 3
39 - - null
40 - null
41 - null
42 - 3
43 doc: DEPRECATED. Physical position of each pixel. 'xyz' represents the
44 position of the pixel relative to the defined coordinate space. Deprecated
45 in favor of origin_coords and grid_spacing.
46 quantity: '?'
47 attributes:
48 - name: conversion
49 dtype: float32
50 default_value: 1.0
51 doc: Scalar to multiply each element in data to convert it to the specified
52 'unit'. If the data are stored in acquisition system units or other units
53 that require a conversion to be interpretable, multiply the data by
54 'conversion' to convert the data to the specified 'unit'. For example, if
55 the data acquisition system stores values in this object as pixels from x
56 = -500 to 499, y = -500 to 499 that correspond to a 2 m x 2 m range, then
57 the 'conversion' multiplier to get from raw data acquisition pixel units
58 to meters is 2/1000.
59 required: false
60 - name: unit
61 dtype: text
62 default_value: meters
63 doc: Base unit of measurement for working with the data. The default value
64 is 'meters'.
65 required: false
66- name: origin_coords
67 dtype: float32
68 dims:
69 - - x, y
70 - - x, y, z
71 shape:
72 - - 2
73 - - 3
74 doc: Physical location of the first element of the imaging plane (0, 0) for
75 2-D data or (0, 0, 0) for 3-D data. See also reference_frame for what the
76 physical location is relative to (e.g., bregma).
77 quantity: '?'
78 attributes:
79 - name: unit
80 dtype: text
81 default_value: meters
82 doc: Measurement units for origin_coords. The default value is 'meters'.
83 required: false
84- name: grid_spacing
85 dtype: float32
86 dims:
87 - - x, y
88 - - x, y, z
89 shape:
90 - - 2
91 - - 3
92 doc: Space between pixels in (x, y) or voxels in (x, y, z) directions, in the
93 specified unit. Assumes imaging plane is a regular grid. See also
94 reference_frame to interpret the grid.
95 quantity: '?'
96 attributes:
97 - name: unit
98 dtype: text
99 default_value: meters
100 doc: Measurement units for grid_spacing. The default value is 'meters'.
101 required: false
102- name: reference_frame
103 dtype: text
104 doc: Describes reference frame of origin_coords and grid_spacing. For example,
105 this can be a text description of the anatomical location and orientation of
106 the grid defined by origin_coords and grid_spacing or the vectors needed to
107 transform or rotate the grid to a common anatomical axis (e.g., AP/DV/ML).
108 This field is necessary to interpret origin_coords and grid_spacing. If
109 origin_coords and grid_spacing are not present, then this field is not
110 required. For example, if the microscope takes 10 x 10 x 2 images, where the
111 first value of the data matrix (index (0, 0, 0)) corresponds to (-1.2, -0.6,
112 -2) mm relative to bregma, the spacing between pixels is 0.2 mm in x, 0.2 mm
113 in y and 0.5 mm in z, and larger numbers in x mean more anterior, larger
114 numbers in y mean more rightward, and larger numbers in z mean more ventral,
115 then enter the following -- origin_coords = (-1.2, -0.6, -2) grid_spacing =
116 (0.2, 0.2, 0.5) reference_frame = "Origin coordinates are relative to
117 bregma. First dimension corresponds to anterior-posterior axis (larger index
118 = more anterior). Second dimension corresponds to medial-lateral axis
119 (larger index = more rightward). Third dimension corresponds to
120 dorsal-ventral axis (larger index = more ventral)."
121 quantity: '?'
122groups:
123- neurodata_type_inc: OpticalChannel
124 doc: An optical channel used to record from an imaging plane.
125 quantity: +
126links:
127- name: device
128 target_type: Device
129 doc: Link to the Device object (e.g., microscope) used to acquire images from
130 this imaging plane.
3.13.9. OpticalChannel
Extends: NWBContainer
Description: see Section 2.12.9
YAML Specification:
1neurodata_type_def: OpticalChannel
2neurodata_type_inc: NWBContainer
3doc: An optical channel used to record from an imaging plane.
4datasets:
5- name: description
6 dtype: text
7 doc: Description or other notes about the channel.
8- name: emission_lambda
9 dtype: float32
10 doc: Emission wavelength for channel, in nm.
3.13.10. MotionCorrection
Extends: NWBDataInterface
Description: see Section 2.12.10
YAML Specification:
1neurodata_type_def: MotionCorrection
2neurodata_type_inc: NWBDataInterface
3default_name: MotionCorrection
4doc: 'An image stack where all frames are shifted (registered) to a common coordinate
5 system, to account for movement and drift between frames. Note: each frame at each
6 point in time is assumed to be 2-D (has only x and y dimensions).'
7groups:
8- neurodata_type_inc: CorrectedImageStack
9 doc: Results from motion correction of an image stack.
10 quantity: +
3.13.11. CorrectedImageStack
Extends: NWBDataInterface
Description: see Section 2.12.11
YAML Specification:
1neurodata_type_def: CorrectedImageStack
2neurodata_type_inc: NWBDataInterface
3doc: Results from motion correction of an image stack.
4groups:
5- name: corrected
6 neurodata_type_inc: ImageSeries
7 doc: Image stack with frames shifted to the common coordinates.
8- name: xy_translation
9 neurodata_type_inc: TimeSeries
10 doc: Stores the x,y delta necessary to align each frame to the common
11 coordinates, for example, to align each frame to a reference image.
12links:
13- name: original
14 target_type: ImageSeries
15 doc: Link to ImageSeries object that is being registered.
3.14. Retinotopy
This source module contains neurodata_type for retinotopy data.
3.14.1. ImagingRetinotopy
Extends: NWBDataInterface
Description: see Section 2.13.1
YAML Specification:
1neurodata_type_def: ImagingRetinotopy
2neurodata_type_inc: NWBDataInterface
3default_name: ImagingRetinotopy
4doc: 'DEPRECATED. Intrinsic signal optical imaging or widefield imaging for measuring
5 retinotopy. Stores orthogonal maps (e.g., altitude/azimuth; radius/theta) of responses
6 to specific stimuli and a combined polarity map from which to identify visual areas.
7 This group does not store the raw responses imaged during retinotopic mapping or
8 the stimuli presented, but rather the resulting phase and power maps after applying
9 a Fourier transform on the averaged responses. Note: for data consistency, all images
10 and arrays are stored in the format [row][column] and [row, col], which equates
11 to [y][x]. Field of view and dimension arrays may appear backward (i.e., y before
12 x).'
13datasets:
14- name: axis_1_phase_map
15 dtype: float32
16 dims:
17 - num_rows
18 - num_cols
19 shape:
20 - null
21 - null
22 doc: Phase response to stimulus on the first measured axis.
23 attributes:
24 - name: dimension
25 dtype: int32
26 dims:
27 - num_rows, num_cols
28 shape:
29 - 2
30 doc: 'Number of rows and columns in the image. NOTE: row, column representation
31 is equivalent to height, width.'
32 - name: field_of_view
33 dtype: float32
34 dims:
35 - height, width
36 shape:
37 - 2
38 doc: Size of viewing area, in meters.
39 - name: unit
40 dtype: text
41 doc: Unit that axis data is stored in (e.g., degrees).
42- name: axis_1_power_map
43 dtype: float32
44 dims:
45 - num_rows
46 - num_cols
47 shape:
48 - null
49 - null
50 doc: Power response on the first measured axis. Response is scaled so 0.0 is
51 no power in the response and 1.0 is maximum relative power.
52 quantity: '?'
53 attributes:
54 - name: dimension
55 dtype: int32
56 dims:
57 - num_rows, num_cols
58 shape:
59 - 2
60 doc: 'Number of rows and columns in the image. NOTE: row, column representation
61 is equivalent to height, width.'
62 - name: field_of_view
63 dtype: float32
64 dims:
65 - height, width
66 shape:
67 - 2
68 doc: Size of viewing area, in meters.
69 - name: unit
70 dtype: text
71 doc: Unit that axis data is stored in (e.g., degrees).
72- name: axis_2_phase_map
73 dtype: float32
74 dims:
75 - num_rows
76 - num_cols
77 shape:
78 - null
79 - null
80 doc: Phase response to stimulus on the second measured axis.
81 attributes:
82 - name: dimension
83 dtype: int32
84 dims:
85 - num_rows, num_cols
86 shape:
87 - 2
88 doc: 'Number of rows and columns in the image. NOTE: row, column representation
89 is equivalent to height, width.'
90 - name: field_of_view
91 dtype: float32
92 dims:
93 - height, width
94 shape:
95 - 2
96 doc: Size of viewing area, in meters.
97 - name: unit
98 dtype: text
99 doc: Unit that axis data is stored in (e.g., degrees).
100- name: axis_2_power_map
101 dtype: float32
102 dims:
103 - num_rows
104 - num_cols
105 shape:
106 - null
107 - null
108 doc: Power response on the second measured axis. Response is scaled so 0.0 is
109 no power in the response and 1.0 is maximum relative power.
110 quantity: '?'
111 attributes:
112 - name: dimension
113 dtype: int32
114 dims:
115 - num_rows, num_cols
116 shape:
117 - 2
118 doc: 'Number of rows and columns in the image. NOTE: row, column representation
119 is equivalent to height, width.'
120 - name: field_of_view
121 dtype: float32
122 dims:
123 - height, width
124 shape:
125 - 2
126 doc: Size of viewing area, in meters.
127 - name: unit
128 dtype: text
129 doc: Unit that axis data is stored in (e.g., degrees).
130- name: axis_descriptions
131 dtype: text
132 dims:
133 - axis_1, axis_2
134 shape:
135 - 2
136 doc: Two-element array describing the contents of the two response axis
137 fields. Description should be something like ['altitude', 'azimuth'] or
138 ['radius', 'theta'].
139- name: focal_depth_image
140 dtype: uint16
141 dims:
142 - num_rows
143 - num_cols
144 shape:
145 - null
146 - null
147 doc: 'Gray-scale image taken with the same settings/parameters (e.g., focal depth,
148 wavelength) as data collection. Array format: [rows][columns].'
149 quantity: '?'
150 attributes:
151 - name: bits_per_pixel
152 dtype: int32
153 doc: Number of bits used to represent each value. This is necessary to
154 determine maximum (white) pixel value.
155 - name: dimension
156 dtype: int32
157 dims:
158 - num_rows, num_cols
159 shape:
160 - 2
161 doc: 'Number of rows and columns in the image. NOTE: row, column representation
162 is equivalent to height, width.'
163 - name: field_of_view
164 dtype: float32
165 dims:
166 - height, width
167 shape:
168 - 2
169 doc: Size of viewing area, in meters.
170 - name: focal_depth
171 dtype: float32
172 doc: Focal depth offset, in meters.
173 - name: format
174 dtype: text
175 doc: Format of image. Currently only 'raw' is supported.
176- name: sign_map
177 dtype: float32
178 dims:
179 - num_rows
180 - num_cols
181 shape:
182 - null
183 - null
184 doc: Sine of the angle between the direction of the gradient in axis_1 and
185 axis_2.
186 quantity: '?'
187 attributes:
188 - name: dimension
189 dtype: int32
190 dims:
191 - num_rows, num_cols
192 shape:
193 - 2
194 doc: 'Number of rows and columns in the image. NOTE: row, column representation
195 is equivalent to height, width.'
196 - name: field_of_view
197 dtype: float32
198 dims:
199 - height, width
200 shape:
201 - 2
202 doc: Size of viewing area, in meters.
203- name: vasculature_image
204 dtype: uint16
205 dims:
206 - num_rows
207 - num_cols
208 shape:
209 - null
210 - null
211 doc: 'Gray-scale anatomical image of cortical surface. Array structure: [rows][columns]'
212 attributes:
213 - name: bits_per_pixel
214 dtype: int32
215 doc: Number of bits used to represent each value. This is necessary to
216 determine maximum (white) pixel value.
217 - name: dimension
218 dtype: int32
219 dims:
220 - num_rows, num_cols
221 shape:
222 - 2
223 doc: 'Number of rows and columns in the image. NOTE: row, column representation
224 is equivalent to height, width.'
225 - name: field_of_view
226 dtype: float32
227 dims:
228 - height, width
229 shape:
230 - 2
231 doc: Size of viewing area, in meters.
232 - name: format
233 dtype: text
234 doc: Format of image. Currently only 'raw' is supported.