Release Notes
2.10.1 (Upcoming)
Bug fixes
Fixed copy-paste error in
VoltageClampSeries.capacitance_slowunit attribute doc, which incorrectly referencedcapacitance_fast.Fixed
IntervalSeries.dataresolution and unit attribute docs, which were verbatim copy-paste fromAnnotationSeriesand incorrectly described the field as storing annotations.Fixed
IndexSeries.indexed_imageslink doc, which referenced the non-existent dataset name'ordered_images'; corrected to'order_of_images'to match the actual field inImages.Fixed
ImagingPlane.devicelink doc, which incorrectly described the device as being used to “record from this electrode”; updated to reflect optical physiology imaging context.Fixed
RoiResponseSeries.roisdoc, which referenced the non-existent typeROITable; corrected toPlaneSegmentationto match the actual type used for ROI segmentation results.
Documentation improvements
Corrected grammar, spelling, and punctuation errors across all core schema doc strings, including typos, broken syntax, missing terminal periods, inconsistent
DEPRECATED.tag formatting, informal and improper abbreviations, missing words and wrong words, subject-verb disagreement, and missing articles. (#704)
2.10.0 (June 18, 2026)
Major changes
Implemented NWBEP001 – Added new neurodata types
EventsTable,TimestampVectorData, andDurationVectorData. (#645)Incorporated HDMF Common Schema 1.9.0 which added new data type
MeaningsTableand support forMeaningsTableinDynamicTable, and promotedHERDfrom the HDMF-experimental namespace to a stable data type in HDMF-common.Added support for an optional
HERDobject at/general/external_resources. (#646)Deprecated
BehavioralEventsandAnnotationSeriesin favor ofEventsTable. AllEventsTableinstances for a session belong in the top-level/eventsgroup of theNWBFile, regardless of provenance; the optionalsource_descriptionattribute on each table captures where the events came from (e.g.,"Acquisition system","Thresholding of analog signal ANALOG1 at 3 V","Manual video review"). ForBehavioralEvents: eachTimeSeriesformerly stored underBehavioralEventsbecomes oneEventsTable, withtimestampsmapping to thetimestampcolumn and any per-event metadata mapping to additional columns. ForAnnotationSeries:timestampsmaps to thetimestampcolumn anddata(annotation strings) maps to the newannotationcolumn. See the schema docs FAQ for details. (#688, #690)
Minor changes
Added optional
num_samplesdataset (uint32) toImageSeriesto store the total number of frames across all external files. This is needed whenformat='external'and timing is described usingstarting_timeandrate, sincedatais empty and its first dimension cannot be used to determine the number of frames. (#561, #543, #677, #678)Improved documentation of
ElectrodeGroupto clarify its purpose as a physical grouping of electrodes that are typically used together for analysis, such as spike sorting. (#659)Specified that units for
ElectrodesTablecoordinate fields (x,y,z,rel_x,rel_y,rel_z) should be in microns. (#658)Expanded documentation for the
Subject‘age’ dataset, including details on ISO 8601 Duration format and age range representation. (#669)Clarified
Units.spike_timesandUnits.obs_intervalsdocumentation to specify that times are relative to the session reference time and that values should be stored in ascending order. (#676)Improved documentation of
Units.spike_times.resolutionto clarify that it represents the temporal resolution (sampling period) of the spike times. (#666)Harmonized
/intervals/*group docstrings; rewroteTimeIntervalsandEventsTabletype docstrings; replaced the placeholder docstring on the/eventsgroup and its innerEventsTableslot; added a FAQ entry on routing time-anchored experimental data. (#688)Improved documentation for
OnePhotonSeriesandTwoPhotonSeries: addeddatadataset specification with an ASCII diagram clarifying the meaning of theheightandwidthdimensions; clarified that for raster-based microscopy, width (columns) is the fast scan direction; contrasted this convention with standard matrix notation where the first array dimension slices through rows. (#649)
2.9.0 (June 26, 2025)
Major changes
Deprecated
Device.model_number,Device.model_name,Device.manufacturer. UseDevice.modellink and newDeviceModelneurodata type instead. The oldDevice.model_namecorresponds to the newDeviceModel.name. (#608)Added
DeviceModelneurodata type to represent the model of a device instead of a specific instance of a device. This deduplicates information when a session involves multiple instances of the same device model, and it helps combine data across sessions and experiments when the model is the same. See https://github.com/NeurodataWithoutBorders/nwb-schema/issues/607 for details. (#608)Added
BaseImageandExternalImageas new neurodata types. The first so bothImageandExternalImagecan inherit from it. The second to store external images (#604, #623, #627)Changed
NWBFile.electrodesfrom a genericDynamicTablewith added columns to a newElectrodesTableneurodata type that extendsDynamicTablewith added columns. (#539, #624)Changed
DecompositionSeries.bandsfrom a genericDynamicTablewith added columns to a newFrequencyBandsTableneurodata type that extendsDynamicTablewith added columns. (#610)Made
SpikeEventSeries.timestampsexplicitly required as described in the documentation. (#629)Allowed
EventDetectionto have shape (num_events, 2) to store the channel index of the detected event. (#620)
Minor changes
Made group quantities consistent (“1 or more”) across data interfaces / wrapper types (#613)
Fixed typo and removed HTML tag from doc of behavioral neurodata types. (#600)
Improved the documentation of
IndexSeries. (#614)Made
EventDetection.timesoptional and deprecated. Use source_idx instead. (#620)Clarified documentation of
PlaneSegmentationthat at least one ofimage_mask,pixel_mask, andvoxel_maskis required. (#636)
2.8.0 (November 24, 2024)
Major changes
Deprecated
EventWaveformneurodata type. (#584)Deprecated
ImageMaskSeriesneurodata type. (#583)
Minor changes
Added optional
was_generated_byattribute toNWBFileto store provenance information. (#578)Made
band_meanandband_stdinDecompositionSeriesoptional. (#593)Added
Device.model_number,Device.model_name,Device.serial_number. (#594)
2.7.0 (February 7, 2024)
Minor changes
Fixed typos in docstrings. (#560)
Deprecated
ImagingRetinotopyneurodata type. (#565)Modified
OptogeneticSeriesto allow 2D data, primarily in extensions ofOptogeneticSeries. (#564)Added optional
stimulus_templatecolumn toIntracellularStimuliTableas part of theIntracellularRecordingsTable. (#545)Added support for
NWBDataInterfaceandDynamicTableinNWBFile.stimulus. (#559)
2.6.0 (January 17, 2023)
Minor changes
Added OnePhotonSeries. (#523)
Subject.agehas a new optional attribute,reference, which can take a value of “birth” (default) or “gestational”. (#525)Added “in seconds” to the doc of Units.spike_times. (#530)
2.5.0 (June 14, 2022)
Major changes
Shape of SpatialSeries.data is more restrictive to prevent > 3 columns. (#510)
Minor changes
The elements x, y, z, imp and filtering are now optional instead of required. (#506)
Added an
offsetattribute to allTimeSeriesobjects to allow enhanced translation to scientific units. (#494)Allowed
NWBFile/stimulus/templatesto containImagesobjects. (#459)Added new optional “order_of_images” dataset to
Imagesthat contains an ordered list of object references toImageobjects stored in the sameImagesobject. This dataset must be used if the images are referred to by index, e.g., from anIndexSeriesobject. Created new neurodata typeImageReferenceswhich should be used for this dataset. (#459, #518, #519, #520)Overhauled
IndexSeriestype (#459): - Fixed dtype ofdatadataset ofIndexSeries(int32 -> uint32). - Updatedunitattribute ofdatato have fixed value “N/A”. - Updated docstrings for theconversion,resolution, andoffsetattributes ofdatato indicate that these fields are not used. - Added link to anImagesobject, which contains an ordered collection of images. - Discouraged use of theindexed_timeserieslink to anImageSeries.Updated
TimeIntervalsto use the newTimeSeriesReferenceVectorDatatype. This does not alter the overall structure ofTimeIntervalsin a major way aside from changing the value of theneurodata_typeattribute in the file fromVectorDatato`TimeSeriesReferenceVectorData. This change replaces the existingTimeIntervals.timeseriescolumn with aTimeSeriesReferenceVectorDatatype column of the same name and overall schema. This change facilitates creating common functionality aroundTimeSeriesReferenceVectorData. This change affects all existingTimeIntervalstables as part of theintervals/group, i.e.,intervals/epochs,intervals/trials, andintervals/invalid_times. (#486)Clarified the doc string for the
referencecolumn of the electrodes table. (#498)Added
cell_idfield toIntracellularElectrode. (#512)
2.4.0 (Aug. 11, 2021)
Major changes
Added new
TimeSeriesReferenceVectorDatatype for referencing ranges ofTimeSeriesfrom aVectorDatacolumn (#470)Integrated the intracellular electrophysiology experiment metadata table structure developed as part of the ndx-icephys-meta extension project with NWB (#470). This includes the following new types:
IntracellularRecordingsTableis anAlignedDynamicTablefor managing individual intracellular recordings and to group together a stimulus and response from a single electrode recording. The table contains the following category tables:IntracellularElectrodesTable; aDynamicTablefor storing metadata about theIntracellularElectrodeusedIntracellularStimuliTable; aDynamicTablefor storing metadata about the recorded stimulusTimeSeriesusing the newTimeSeriesReferenceVectorDatatype to referenceTimeSeriesIntracellularResponsesTable; aDynamicTablefor storing metadata about the recorded responseTimeSeriesusing the newTimeSeriesReferenceVectorDatatype to referenceTimeSeries
SimultaneousRecordingsTableis aDynamicTablefor grouping different intracellular recordings from theIntracellularRecordingsTabletogether that were recorded simultaneously from different electrodes and for storing metadata about simultaneous recordingsSequentialRecordingsTableis aDynamicTablefor grouping different sequential recordings from theSimultaneousRecordingsTabletogether and storing metadata about sequential recordingsRepetitionsTableaDynamicTablefor grouping different sequential intracellular recordings from theSequentialRecordingsTabletogether and storing metadata about repetitionsExperimentalConditionsTableis aDynamicTablefor grouping different intracellular recording repetitions from theRepetitionsTabletogether and storing metadata about experimental conditions
Added the new intracellular electrophysiology metadata tables to
/general/intracellular_ephysas part ofNWBFile(#470)
Deprecations
SweepTablehas been deprecated in favor of the new intracellular electrophysiology metadata tables. Use ofSweepTableis still possible but no longer recommended. (#470)/general/intracellular_ephys/filteringhas been deprecated in favor ofIntracellularElectrode.filtering(#470)
Bug Fixes
Fixed incorrect dtype for electrodes table column “filtering” (float -> text) (#478)
Removed
quantity: *from the type definitions ofOptogeneticStimulusSiteandImagingPlane. This change improves clarity of the schema to follow best practices. It has no functional effect on the schema. (#472)Updated
ImageSeriesto have itsdatadataset be required. SinceImageSeriesis aTimeSeriesandTimeSeries.datais required,ImageSeries.datashould also be a required dataset. Otherwise this creates problems for inheritance and validation. IfImageSeriesdata are stored in an external file, thenImageSeries.datashould be set to an empty 3D array. (#481)
2.3.0 (May 12, 2021)
Add optional
waveformscolumn to theUnitstable.Add optional
strainfield toSubject.Add to
DecompositionSeriesan optionalDynamicTableRegioncalledsource_channels.Add to
ImageSeriesan optional link toDevice.Add optional
continuityfield toTimeSeries.Add optional
filteringattribute toElectricalSeries.Clarify documentation for electrode impedance and filtering.
Add description of extra fields.
Set the
stimulus_descriptionforIZeroCurrentClampto have the fixed valueN/A.Update hdmf-common-schema from 1.1.3 to version 1.5.0. - The HDMF-experimental namespace was added, which includes the
ExternalResourcesandEnumDatadata types. Schema in the HDMF-experimental namespace are experimental and subject to breaking changes at any time. - Added experimental data typeExternalResourcesfor storing ontology information / external resource references. - Added experimental data typeEnumDatato store data from a set of fixed values. - Changed dtype for datasets withinCSRMatrixfrom ‘int’ to ‘uint’ and added missingdata_type_inc: Containerto theCSRMatrixtype. - Added data typeSimpleMultiContainer, a Container for storing other Container and Data objects together. - Added data typeAlignedDynamicTable, a DynamicTable type with support for categories (or sub-headings) each described by a separate DynamicTable. - Fixed missing dtype forVectorIndex. -VectorIndexnow extendsVectorDatainstead ofIndex. - Removed unused and non-functionalIndexdata type. - See https://hdmf-common-schema.readthedocs.io/en/latest/format_release_notes.html for full release notes.
2.2.5 (May 29, 2020)
Add schema validation CI.
Fix incorrect dims and shape for
ImagingPlane.origin_coordsandImagingPlane.grid_spacing, and fix incorrect dims forTwoPhotonSeries.field_of_view.
2.2.4 (April 14, 2020)
Fix typo in
nwb.ophys.yamlthat prevents proper parsing of the schema.
2.2.3 (April 13, 2020)
Move nested type definitions to root of YAML files. This does not functionally change the schema but simplifies parsing of the schema and extensions by APIs.
Make
ImagingPlane.imaging_rateoptional to handle cases where an imaging plane is associated with multiple time series with different rates.Add release process documentation.
2.2.2 (March 2, 2020)
Fix shape and dims of
OpticalSeries.datafor color imagesAllow more than one
OpticalChannelobject inImagingPlaneUpdate hdmf-common-schema to 1.1.3. This fixes missing ‘shape’ and ‘dims’ key for types
VectorData,VectorIndex, andDynamicTableRegion.Revert changes to
nwb.retinotopy.yamlin 2.1.0 which break backward compatibility and were not supported by the APIs in any case. Changes will be revisited in a future version.
2.2.1 (January 14, 2020)
Fixed incorrect version numbers in
nwb.file.yamlandhdmf-common-schema/common/namespace.yaml.
2.2.0 (January 6, 2020)
Moved common data structures such as Container and DynamicTable to hdmf-common-schema.
The hdmf-common-schema repo is now included as a submodule
See https://github.com/NeurodataWithoutBorders/nwb-schema/pull/307 for details
Added “channel_conversion” dataset to ElectricalSeries to represent per-channel conversion factors.
Added “sampling_rate” and “unit” attributes to “waveform_mean” and “waveform_sd” datasets/columns in Units table.
Added “description” and “manufacturer” attributes to Device.
Deprecated ImagingPlane “manifold” in favor of “origin_coords” and “grid_spacing”
Use “text” data type for all DynamicTable “colnames”. Previously, only ASCII was allowed.
Use “text” data type for electrode table columns “location” and “group_name”. Previously, only ASCII was allowed.
Added to description to make electrode x,y,z consistent with CCF reference. https://allensdk.readthedocs.io/en/latest/reference_space.html
Added “position” dataset with compound data type x,y,z in ElectrodeGroup.
Avoid enforcing “uint64” for sweep numbers for better compatibility. Use uint instead which is 32bit.
Set dtype for Image and its subtypes to numeric. (note: technically this breaks backwards compatibility, in the schema, but the pynwb API has always enforced that Images have a numeric type, and realistically we do not think users are storing strings in an Image dataset.)
Added “resolution” attribute to “spike_times” column of Units.
Changed the “quantity” key of attribute Units.resolution to “required” for schema language compliance.
Removed “required” key from dataset ImageSeries.field_of_view for schema language compliance.
Replaced “required” keys with “quantity” keys for ImagingPlane.origin_coords and ImagingPlane.grid_spacing for schema language compliance.
Refactored ImagingRetinotopy type to reduce redundancy.
Added “doc” key to ImagingRetinotopy.axis_2_power_map for schema language compliance.
Fixed makefiles for generating documentation on Windows.
Added optional “reference” column in “electrodes” table.
Changed dims of ImageSeries from (frame, y, x) to (frame, x, y) and (frame, z, y, x) to (frame, x, y, z) to be consistent with the dimension ordering in PlaneSegmentation.
Changed dims of Image from (y, x) to (x, y). (note: as far as we know, users of NWB 2.0 that use the Image type encode their data as (x, y)) to be consistent with the dimension ordering in ImageSeries.
Updated hdmf-common-schema to version 1.1.0 which includes:
The ‘colnames’ attribute of
DynamicTablechanged from data type ‘ascii’ to ‘text’.Improved documentation and type docstrings.
2.1.0 (September 2019)
Improved documentation in “doc” attribute of many types
Removed “help” attribute
Now that the schema is cached in an NWB file by default, this attribute is redundant, confusing, used inconsistently, clutters the file and documentation, and adds substantial boilerplate to writing extensions
See https://github.com/NeurodataWithoutBorders/nwb-schema/issues/270 for details
Removed static “description” attribute from some types
These were intended to be a “help” attribute, which has now been removed
For example, TimeIntervals dataset “start_time” attribute “description” had a fixed value that is now removed
Reordered keys
This standardizes the order of keys across types and makes the schema more readable
See https://github.com/NeurodataWithoutBorders/nwb-schema/issues/274 for details
Added “dims” attribute for datasets where “shape” was specified without “dims”
The “dims” attribute describes the data along each dimension of the dataset and is helpful to provide alongside “shape”
For example, NWBFile dataset “keywords” has attribute “shape” has one entry: “null”. The attribute “dims” was added with one entry: “num_keywords”
Removed redundant specifications that are inherited from a parent type
ElectrodeGroup link “device”: optional -> required
This was previously required by PyNWB
See https://github.com/NeurodataWithoutBorders/pynwb/issues/1025 for details
Matched default and fixed values of datasets and attributes with the documentation and intended use
IZeroClampSeries dataset “bias_current” unspecified value -> fixed value 0.0
IZeroClampSeries dataset “bridge_balance” unspecified value -> fixed value 0.0
IZeroClampSeries dataset “capacitance_compensation” unspecified value -> fixed value 0.0
TimeSeries dataset “resolution” default value: 0.0 -> -1.0
ImagingRetinotopy dataset “axis_descriptions” attribute “shape”: null -> 2
DecompositionSeries dataset “data” attribute “unit” default value unspecified -> default value “no unit”
VoltageClampStimulusSeries, CurrentClampSeries, IZeroClampSeries attribute “unit” has fixed value “volts”
CurrentClampStimulusSeries, VoltageClampSeries, attribute “unit” has fixed value “amperes”
NWBFile dataset “experimenter” and “related_publications” change from scalar to 1-D, unlimited arrays
This allows the “experimenter” and “related_publications” dataset to encode multiple values
See https://github.com/NeurodataWithoutBorders/pynwb/issues/985 and https://github.com/NeurodataWithoutBorders/nwb-schema/issues/299 for details
Standardized units to be plural, lower-case, SI units
TimeSeries dataset “starting_time” attribute “unit” fixed value: “Seconds” -> “seconds”
TimeSeries dataset “timestamps” attribute “unit” fixed value: “Seconds” -> “seconds”
ElectricalSeries dataset “data” attribute “unit” default value (previously optional): “volt” -> fixed value “volts”
SpikeEventSeries dataset “data” attribute “unit” default value (previously optional): “volt” -> fixed value “volts”
SpikeEventSeries dataset “timestamps” attribute “unit” fixed value (previously optional): “Seconds” -> fixed value “seconds”
EventDetection dataset “times” attribute “unit” default value: “Seconds” -> “seconds”
VoltageClampSeries dataset “capacitance_fast” attribute “unit” default value “Farad” -> fixed value “farads”
VoltageClampSeries dataset “capacitance_slow” attribute “unit” default value “Farad” -> fixed value “farads”
VoltageClampSeries dataset “resistance_comp_bandwidth” attribute “unit” default value “Hz” -> fixed value “hertz”
VoltageClampSeries dataset “resistance_comp_correction” attribute “unit” default value “percent” -> fixed value “percent”
VoltageClampSeries dataset “resistance_comp_prediction” attribute “unit” default value “percent” -> fixed value “percent”
VoltageClampSeries dataset “whole_cell_capacitance_comp” attribute “unit” default value “Farad” -> fixed value “farads”
VoltageClampSeries dataset “whole_cell_series_resistance_comp” attribute “unit” default value “Ohm” -> fixed value “ohms”
OptogeneticSeries dataset “data” attribute “unit” default value “watt” -> fixed value “watts”
ImagingPlane dataset “manifold” attribute “unit” default value “Meter” -> default value “meters”
see https://github.com/NeurodataWithoutBorders/nwb-schema/issues/277 for details
Made Units table column “waveform_mean” and “waveform_sd” have shape num_units x num_samples x num_electrodes
See https://github.com/NeurodataWithoutBorders/pynwb/pull/1008 for details
Made CorrectedImageStack and ImagingRetinotopy inherit from the more specific NWBDataInterface instead of NWBContainer
Added a scratch space for saving arbitrary datasets to an NWBFile
NWB is cumbersome as a format for day-to-day work. There is a lot of overheard to save one-off analysis results to an NWB file. To save new datasets, a user has write an extension. This is a lot of work for a result that may just be tossed out.
“scratch” is now an optional top-level group under NWBFile that can hold NWBContainer groups and ScratchData datasets
The scratch space is explicitly for non-standardized data that is not intended for reuse by others. Standard NWB types, and extensions if required, should always be used for any data that you intend to share. As such, published data should not include scratch data and a user should be able to ignore any data stored in scratch to use a file.
See https://github.com/NeurodataWithoutBorders/nwb-schema/issues/286 for details
Set the default value for the dataset “format” to “raw” and clarified the documentation for ImageSeries
Add required attribute
object_idto all NWB Groups and Datasets with an assigned neurodata_type
Backwards compatibility: The PyNWB and MatNWB APIs can read 2.0 files with the 2.1 schema.
2.0.2 (June 2019)
Updated authors
Removed NWBFile subgroup “specifications” because schema is now cached
See https://github.com/NeurodataWithoutBorders/pynwb/pull/953 for details
Made DecompositionSeries link “source_timeseries” optional
See https://github.com/NeurodataWithoutBorders/pynwb/pull/955 for details
2.0.1 (March 2019)
Change: Added doc and title descriptions for the individual source files included in the main namespace.
Reason: Enhance documentation of the namespace and facilitate presentation of types in autogenerated docs by
making it easier to sort neurodata_types into meaningful categories (i.e., sections) with approbriate tiles and
descriptions.
Backwards compatibility: No changes to the actual specification of the format are made. 2.0.1 is fully compatible with 2.0.0.
2.0.0 (January 2019)
Main release: November 2017 (Beta), November 2018 (RC), January 2019 (final)
Added new base data types: NWBContainer, NWBData, NWBDataInterface
Change: Added common base types for Groups, Datasets, and for Groups storing primary experiment data
Reason Collect common functionality and ease future evolution of the standard
Specific Changes
NWBContainer defines a common base type for all Groups with a
neurodata_typeand is now the base type of all main data group types in the NWB format, including TimeSeries. This also means that all group types now inherit the requiredhelpandsourceattribute fromNWBContainer. A number of neurodata_types have been updated to add the missinghelp(see https://github.com/NeurodataWithoutBorders/nwb-schema/pull/37/files for details)NWBDataInterface extends NWBContainer and replaces
Interfacefrom NWB 1.x. It has been renamed to ease intuition. NWBDataInterface serves as base type for primary data (e.g., experimental or analysis data) and is used to distinguish in the schema between non-metadata data containers and metadata containers. (see https://github.com/NeurodataWithoutBorders/nwb-schema/pull/116/files for details)NWBData defines a common base type for all Datasets with a
neurodata_typeand serves a similar function to NWBContainer only for Datasets instead of Groups.
Support general data structures for data tables and vector data
Support row-based and column-based tables
Change: Add support for storing tabular data via row-based and column-based table structures.
Reason: Simplify storage of complex metadata. Simplify storage of dynamic and variable-length metadata.
Format Changes:
Row-based tables: are implemented via a change in the specification language through support for compound data types The advantage of row-based tables is that they 1) allow referencing of sets of rows via region-references to a single dataset (e.g., a set of electrodes), 2) make it easy to add rows by appending to a single dataset, 3) make it easy to read individual rows of a table (but require reading the full table to extract the data of a single column). Row-based tables are used to simplify, e.g., the organization of electrode-metadata in NWB 2 (see above). (See the specification language release notes for details about the addition of compound data types in the schema).
Referencing rows in a row-based tables: Subsets of rows can referenced directly via a region-reference to the row-based table. Subsets
Referencing columns in a row-based table: This is currently not directly supported, but could be implemented via a combination of an object-reference to the table and a list of the labels of columns.
Column-based tables: are implemented via the new neurodata_type DynamicTable. A DynamicTable is simplified-speaking just a collection of an arbitrary number of VectorData table column datasets (all with equal length) and a dataset storing row ids and a dataset storing column names. The advantage of the column-based store is that it 1) makes it easy to add new columns to the table without the need for extensions and 2) the column-based storage makes it easy to read individual columns efficiently (while reading full rows requires reading from multiple datasets). DynamicTable is used, e.g., to enhance storage of trial data. (See https://github.com/NeurodataWithoutBorders/pynwb/pull/536/files )
Referencing rows in column-based tables: As DynamicTable consist of multiple datasets (compared to row-based tables which consists of a single 1D dataset with a compound datatype) is not possible to reference a set of rows with a single region reference. To address this issue, NWB defines DynamicTableRegion (added later in PR634 (PyNWB)) dataset type, which stores a list of integer indices (row index) and also has an attribute
tablewith the object reference to the corresponding DynamicTable.Referencing columns in a columns-based table: As each column is a separate dataset, columns of a column-based DynamicTable can be directly references via links, object-references and region-references.
Enable efficient storage of large numbers of vector data elements
Change Introduce neurodata_types VectorData , VectorIndex, ElementIdentifiers
Reason To efficiently store spike data as part of UnitTimes a new, more efficient data structure was required. This builds the general, reusable types to define efficient data storage for large numbers of data vectors in efficient, consolidated arrays, which enable more efficient read, write, and search (see Improved storage of unit-based data).
Format Changes
VectorData : Data values from a series of data elements are concatenated into a single array. This allows all elements to be stored efficiently in a single data array.
VectorIndex : 1D dataset of exclusive stop-indices selecting subranges in VectorData. In addition, the
targetattribute stores an object reference to the corresponding VectorData dataset. With this we can efficiently access single sub-vectors associated with single elements from the VectorData collection. An alternative approach would be store region-references as part of the VectorIndex. We opted for stop-indices mainly because they are more space-efficient and are easier to use for introspection of index values than region references.ElementIdentifiers : 1D array for storing unique identifiers for the elements in a VectorIndex.
See Improved storage of unit-based data for an illustration and specific example use in practice. See also I116 (nwb-schema) and PR382 (PyNWB) for further details.
Use new table and vector data structures to improve data organization
Improved organization of electrode metadata in /general/extracellular_ephys
Change: Consolidate metadata from related electrodes (e.g., from a single device) in a single location.
Example: Previous versions of the format specified in /general/extracellular_ephys for each electrode a
group <electrode_group_X> that stores 3 text datasets with a description, device name, and location, respectively.
The main /general/extracellular_ephys group then contained in addition the following datasets:
electrode_grouptext array describing for each electrode_group (implicitly referenced by index) which device (shank, probe, tetrode, etc.) was used,
electrode_maparray with the x,y,z locations of each electrode
filtering, i.e., a single string describing the filtering for all electrodes (even though each electrode might be from different devices), and iv),
impedance, i.e., a single text array for impedance (i.e., the user has to know which format the string has, e.g., a float or a tuple of floats for impedance ranges).
Reason:
Avoid explosion of the number of groups and datasets. For example, in the case of an ECoG grid with 128 channels one had to create 128 groups and corresponding datasets to store the required metadata about the electrodes using the original layout.
Simplify access to related metadata. E.g., access to metadata from all electrodes of a single device requires resolution of a potentially large number of implicit links and access to a large number of groups (one per electrode) and datasets.
Improve performance of metadata access operations. E.g., to access the
locationof all electrodes corresponding to a single recording in an<ElectricalSeries>in the original layout required iterating over a potentially large number of groups and datasets (one per electrode), hence, leading to a large number of small, independent read/write/seek operations, causing slow performance on common data accesses. Using the new layout, these kind of common data accesses can often be resolved via a single read/writeEase maintenance, use, and development through consolidation of related metadata
Format Changes
Added specification of a new neurodata type
<ElectrodeGroup>group. Each<ElectrodeGroup>contains the following datasets to describe the metadata of a set of related electrodes (e.g., all electrodes from a single device):
description: text dataset (for the group)
device: Soft link to the device in/general/devices/
location: Text description of the location of the deviceAdded table-like dataset
electrodesthat consolidates all electrode-specific metadata. This is a DynamicTable describing for each electrode:
id: a user-specified unique identifier
x,y,z: The floating point coordinate for the electrode
imp: the impedance of the channel
location: The location of channel within the subject e.g. brain region
filtering: Description of hardware filtering
group: Object reference to theElectrodeGroupobject
group_name: The name of theElectrodeGroupUpdated
/general/extracellular_ephysas follows:
Replaced
/general/extracellular_ephys/<electrode_group_X>group (and all its contents) with the new<ElectrodeGroup>Removed
/general/extracellular_ephys/electrode_mapdataset. This information is now stored in theElectrodeTable.Removed
/general/extracellular_ephys/electrode_groupdataset. This information is now stored in<ElectrodeGroup>/device.Removed
/general/extracellular_ephys/impedanceThis information is now stored in theElectrodeTable.Removed
/general/extracellular_ephys/filteringThis information is now stored in theElectrodeTable.
Note
In NWB 2.0Beta the refactor originally used a row-based table for the ElectrodeTable based on a compound
data type as described in #I6 (new-schema), i.e.,
electrodes was a 1D compound dataset. This was later changed to a column-based DynamicTable
(see Support row-based and column-based tables). The main reason for this later change was mainly to avoid the need
for large numbers of user-extensions to add electrode metadata
(see #I623 (PyNWB) and
PR634 (PyNWB) for details.) This change
also removed the optional description column as it can be added easily by the user to the
DynamicTable if required.
Improved storage of lab-specific meta-data
Reason: Labs commonly have specific meta-data associated with sessions, and we need a good way to organize this within NWB.
Changes: The datatype LabMetaData has been added to the schema within /general so that an extension can be added to /general by inheriting from LabMetaData.
For further details see I19 (nwb-schema) and PR751 (PyNWB).
Improved storage of Spectral Analyses (Signal Decomposition)
Reason: Labs commonly use analyses that involve frequency decomposition or bandpass filtering of neural or behavioral data, and it is difficult to standardize this data and meta-data across labs.
Changes: A new datatype, DecompositionSeries has been introduced to offer a common interface for labs to exchange the result of time-frequency analysis. The new type offers a DynamicTable to allow users to flexibly add features of bands, and a place to directly link to the TimeSeries that was used.
For further details see #I46 (nwb-schema) and #PR764 (PyNWB)
Improved storage of Images
Reason:
Improve consistency of schema: Previously there was a reference to
ImagefromImageSeries, howeverImagewas not defined in the schemaSupport different static image types
Changes: Image was added as a base type, and subtypes were defined: GrayscaleImage, RGBImage, and RGBAImage (The “A” in “RGBA” is for alpha, i.e., opacity).
Improved storage of ROIs
Reason:
Improve efficiency: Similar to epochs, in NWB 1.x ROIs were stored as a single group per ROI. This structure is inefficient for storing large numbers of ROIs.
Make links explicit: The relationship of
RoiResponseSeriestoROIobjects was implicit (i.e. ROI was specified by a string), so one had to know a priori whichImageSegmentationandImagingPlanewas used to produce the ROIs.Support 3D ROIs: Allow users to add 3D ROIs collected from a multi-plane image.
Changes: The main types for storing ROIs in NWB 2 are ImageSegmentation which stores 0 or more PlaneSegmentation. PlaneSegmentation is a DynamicTable for managing image segmentation results of a specific imaging plane. The ROIs are referenced by RoiResponseSeries which stores the ROI responses over an imaging plane. During the development of NWB 2 the management of ROIs has been improved several times. Here we outline the main changes (several of which were ultimately merged together in the PlaneSegmentation type).
Added neurodata_type
ImageMasksreplacingROI.img_mask(from NWB 1.x) with (a) a 3D dataset with shape [num_rois, num_x_pixels, num_y_pixels] (i.e. an array of planar image masks) or (b) a 4D dataset with shape [num_rois, num_x_pixels, num_y_pixels, num_z_pixels] (i.e. an array of volumetric image masks)ImageMaskswas subsequently merged with PlaneSegmentation and is represented by the VectorData table columnimage_maskin the table.Added neurodata_type
PixelMaskswhich replaces ROI.pix_mask/ROI.pix_mask_weight (from NWB 1.x) with a table that has columns “x”, “y”, and “weight” (i.e. combining ROI.pix_mask and ROI.pix_mask_weight into a single table).PixelMaskswas subsequently merged with PlaneSegmentation and is represented by the VectorData datasetpixel__maskthat is referenced from the table via the VectorIndex columnpixel_mask_index.Added analogous neurodata_type
VoxelMaskswith a table that has columns “x”, “y”, “z”, and “weight” for 3D ROIs.VoxelMaskswas subsequently merged with PlaneSegmentation and is represented by the VectorData datasetvoxel_maskthat is referenced from the table via the VectorIndex columnvoxel_mask_index.Added neurodata_type
ROITablewhich defines a table for storing references to the image mask and pixel mask for each ROI (see item 1,2). TheROITabletype was subsequently merged with the PlaneSegmentation type and as such does no longer appear as a separate type in the NWB 2 schema but PlaneSegmentation takes the function ofROITable.Added neurodata_type
ROITableRegionfor referencing a subset of elements in an ROITable. SubsequentlyROITableRegionhas been replaced by DynamicTableRegion as theROITablechanged to a DynamicTable and was merged with PlaneSegmentation (see 8.)Replaced
RoiResponseSeries.roi_nameswithRoiResponseSeries.rois, which is a DynamicTableRegion into the PlaneSegmentation table of ROIs (see items 3,4). (Before ROITable was converted from a row-based to a column-based table, RoiResponseSeries.rois` had been changed to aROITableRegionwhich was then subsequently changed to a corresponding DynamicTableRegion)Removed
RoiResponseSeries.segmentation_interface. This information is available throughRoiResponseSeries.rois(described above in 5.)Assigned neurodata_type PlaneSegmentation to the image_plan group in ImageSegmentation and updated it to use the
ROITable,ImageMasks,PixelMasks, and :VoxelMasks(see items 1-4 above). Specifically, PlaneSegmentation has been changed to be a DynamicTable andROITable,ImageMasks,PixelMasks, andVoxelMaskshave been merged into the PlaneSegmentation table, resulting in the removal of theROITable,ROITableRegion,ImageMasks,PixelMasks, andVoxelMaskstypes.
For additional details see also:
PR391 (PyNWB) and I118 (nwb-schema) for details on the main refactoring of ROI storage,
PR665 (PyNWB) and I663 (PyNWB) (and previous issue I643 (PyNWB)) for details on the subsequent refactor using DynamicTable, and
PR688 (PyNWB) and I554 (nwb-schema) for details on 3D ROIs,
Improved storage of unit-based data
In NWB 1.0.x data about spike units was stored across a number of different neurodata_types, specifically
UnitTimes, ClusterWaveforms, and Clustering. This structure had several critical shortcomings,
which were addressed in three main phases during the development of NWB 2.
Problem 1: Efficiency: In NWB 1.x each unit was stored as a separate group unit_n containing the times
and unit_description for unit with index n. In cases where users have a very large number of units, this
was problematic with regard to performance. To address this challenge UnitTimes has been
restructured in NWB 2 to use the new VectorData ,
VectorIndex, ElementIdentifiers data structures
(see Enable efficient storage of large numbers of vector data elements).Specifically, NWB 2 replaced unit_n (from NWB 1.x, also referred to
by neurodata_type SpikeUnit in NWB 2beta) groups in UnitTimes with the following data:
unit_ids: ElementIdentifiers dataset for storing unique ids for each element
spike_times_index: VectorIndex dataset with region references into the spike times dataset
spike_times: VectorData dataset storing the actual spike times data of all units in a single data array (for efficiency).
See also I116 (nwb-schema) and PR382 (PyNWB) for further details.

Fig. 1 Overview of the basic data structure for storing UnitTimes using the
VectorData (spike_times), VectorIndex (spike_times_index),
and ElementIdentifiers (unit_ids) data structures.
Problem 2: Dynamic Metadata: Users indicated that it was not easy to store user-defined metadata about units.
To address this challenge, NWB 2 added an optional top-level group units/ (which was subsequently moved to
/intervals/units) which is a DynamicTable
with id and description columns and optional additional user-defined table columns.
See PR597 on PyNWB for detailed code changes. See
the PyNWB docs for a
short tutorial on how to use unit metadata. See NWBFile Groups: /units for an overview of the
unit schema.
Problem 3: Usability: Finally, users found that storing unit data was
challenging due to the fact that the information was distributed across a number of different
types. To address this challenge, NWB 2.0 integrates UnitTimes, ClusterWaveforms, and Clustering (deprecated)
into the new column-based table units/ (i.e., intervals/units) (which still uses the optimized vector data
storage to efficiently store spike times). See for discussions and
I674 on PyNWB
(and related I239 on NWB Schema) and the pull
request PR684 on PyNWB for detailed changes.
Together these changes have resulted in the following improved structure for storing unit data and metadata in NWB 2.0.
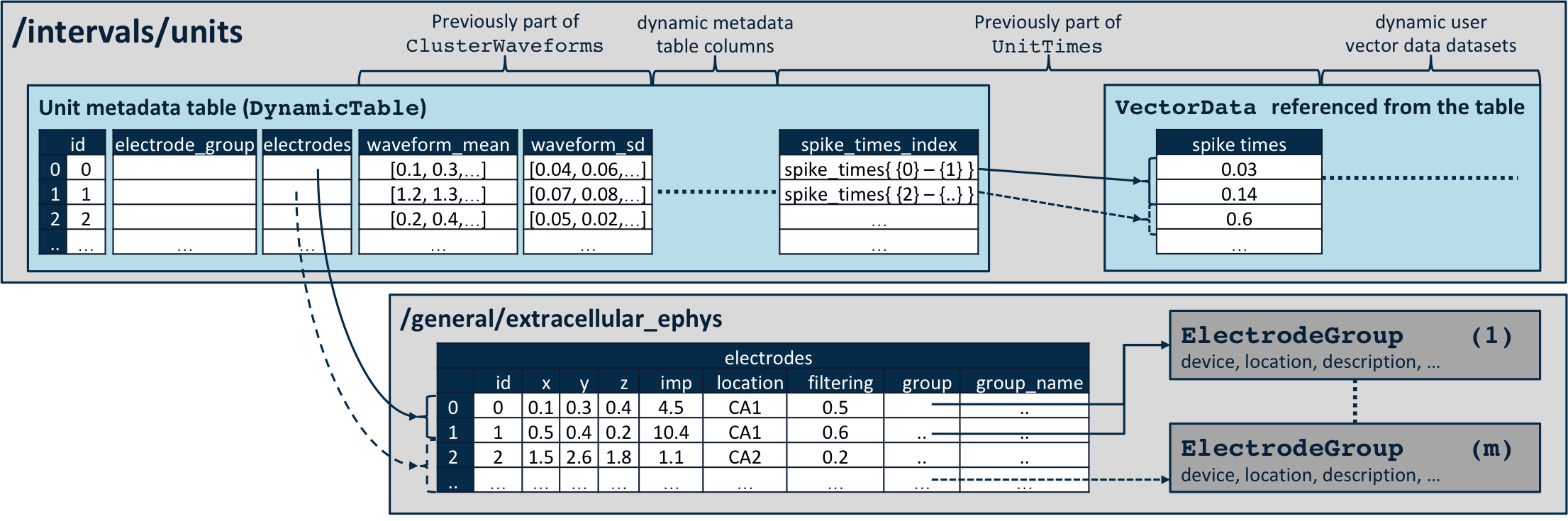
Fig. 2 Overview of the data structure for storing spiking unit data and metadata in NWB 2.0.
- In addition to
spike_times, the units table includes the following optional columns: obs_intervals: intervals indicating the time intervals over which this unit was recorded.electrodes: range references to the electrodes table indicating which electrodes from which this unit was recorded.electrode_group: may be used instead ofelectrodesif mutually exclusive electrode groups are sufficient.waveform_mean: mean waveform across all recorded spikes.waveform_sd: standard deviation from the mean across all recorded spikes.
Improved support for sweep-based information
Changes Added SweepTable type stored in /general/intracellular_ephys
Reason: In Icephys it is common to have sweeps (i.e., a group of PatchClampSeries belonging together, were up to two TimeSeries are from one electrode, including other TimeSeries not related to an electrode (aka TTL channels)). NWB 1.0.x did not support the concept of sweeps, so it was not possible to link different TimeSeries for sweeps. The goal of this change is to allow users to find the TimeSeries which are from one sweep without having to iterate over all present TimeSeries.
Format Changes Added neurodata_type SweepTable to /general/intracellular_ephys.
SweepTable is a DynamicTable <sec-DynamicTable> storing for each sweep a the sweep_number and the
series_index. The later is a VectorIndex pointing to a VectorData
dataset describing belonging PatchClampSeries to the sweeps.
See I499 (PyNWB) and
PR701 (PyNWB) for further details.
Improved specification of reference time stamp(s)
To improve the specification of reference time, NWB adopts ISO8061 for storing datetimes and adds
timestamps_reference_time as explicit zero for all timestamps in addition to the session_start_time.
Improve standardization of reference time specification using ISO8061
Changes: Modify session_start_time an file_create_date to enforce use of ISO 8601 datetime strings
Reason: Standardize the specification of timestamps to ensure consistent programmatic and human interpretation
Format Changes: Updated session_start_time and file_create_date to use dtype: isodatetime that was
added as dedicated dtype to the specification language. For details see
PR641 (PyNWB) and
I50 (nwb-schema).
Improved specification of reference time
Change: Add field timestamps_reference_time, allowing users to explicitly specify a date and time
corresponding to time zero for all timestamps in the nwb file.
Reason: Previously session_start_time served both as the indicator for the start time
of a session as well as the global reference time for a file. Decoupling the two makes the
global reference time explicit and enables users to use times relative to the session start as well
as other reference time frames, e.g., using POSIX time. This also makes the specification easier to
develop against, since this will explicitly specify the offset to obtain relative timestamps, eliminating
the need for APIs to guess based on range.
Format Changes: Added top-level field timestamps_reference_time.
See PR709 (PyNWB) and
I49 (nwb-schema)
for further details.
Improved storage of time intervals
Improved storage of epoch data
Change: Store epoch data as a table to improve efficiency, usability and extensibility.
Reason: In NWB 1.x Epochs are stored as a single group per Epoch. Within each Epoch, the index into each TimeSeries that the Epoch applies to was stored as a single group. This structure is inefficient for storing large numbers of Epochs.
Format Changes: In NWB 2 epochs are stored via a TimeIntervals table (i.e., a
DynamicTable for storing time intervals) that is stored in the group /intervals/epochs.
Over the course of the development of NWB 2 the epoch storage has been refined in several phases:
First, we create a new neurodata_type
Epochswhich was included in NWBFile as the groupepochs. This simplified the extension of the epochs structure./epochsat that point contained a compound (row-based) table with neurodata_typeEpochTablethat described the start/stop times, tags, and a region reference into theTimeSeriesIndexto identify the timeseries parts the epoch applies to. Note, the typesEpochs,EpochTableandTimeSeriesIndexhave been removed/superseded in subsequent changes. (See PR396 (PyNWB) and I119 (nwb-schema) ).Later, an additional DynamicTable for storing dynamic metadata about epochs was then added to the
Epochsneurodata_type to support storage of dynamic metadata about epochs without requiring users to create custom extensions (see PR536 (PyNWB)).Subsequently the epoch table was then fully converted to a DynamicTable (see PR682 (PyNWB) and I664 (PyNWB))
Finally, the EpochTable was then moved to
/intervals/epochsand the EpochTable type was replaced by the more general type TimeIntervals. This also led to removal of theEpochstype (see PR690 (PyNWB) and I683 (PyNWB))
Improved support for trial-based data
Change: Add dedicated concept for storing trial data.
Reason: Users indicated that it was not easy to store trial data in NWB 1.x.
Format Changes: Added optional group /intervals/trials/ which is a DynamicTable
with id, start_time, and stop_time columns and optional additional user-defined table columns.
See PR536 on PyNWB for detailed code changes. See
the PyNWB docs for a
short tutorial on how to use trials. See NWBFile Groups: /trials for an overview of the trial
schema. Note: Originally trials was added a top-level group trials which was then later moved to /intervals/trials
as part of the generalization of time interval storage as part of
PR690 (PyNWB) .
Generalized storage of time interval
Change: Create general type TimeIntervals (which is a generalization of the
previous EpochTable type) and create top-level group /intervals for organizing time interval data.
Reason: Previously all time interval data was stored in either epochs or trials. To facilitate reuse
and extensibility this has been generalized to enable users to create arbitrary types of intervals in
addition to the predefined types, i.e., epochs or trials.
Format Changes: See PR690 (PyNWB) and I683 (PyNWB) for details:
Renamed
EpochTabletype to the more general type TimeIntervals to facilitate reuse.Created top-level group
/intervalsfor organizing time interval data.
Moved
/epochsto/intervals/epochsand reused the TimeIntervals typeMoved
/trialsto/intervals/trialsand reused the TimeIntervals typeAllow users to add arbitrary TimeIntervals tables to
/intervalsAdd optional TimeIntervals object named
invalid_timesin ‘’/intervals``, which specifies time intervals that contain artifacts. See I224 (nwb-schema) and PR731 (PyNWB) for details.
Replaced Implicit Links/Data-Structures with Explicit Links
Change Replace implicit links with explicit soft-links to the corresponding HDF5 objects where possible, i.e., use explicit HDF5 mechanisms for expressing basic links between data rather than implicit ones that require users/developers to know how to use the specific data. In addition to links, NWB 2 adds support for object- and region references, enabling the creation of datasets (i.e., arrays) that store links to other data objects (groups or datasets) or regions (i.e., subsets) of datasets.
Reason: In several places datasets containing arrays of either 1) strings with object names, 2) strings with paths, or 3) integer indexes are used that implicitly point to other locations in the file. These forms of implicit links are not self-describing (e.g., the kind of linking, target location, implicit size and numbering assumptions are not easily identified). This hinders human interpretation of the data as well as programmatic resolution of these kind of links.
Format Changes:
Text dataset
image_planeof<TwoPhotonSeries>is now a link to the corresponding<ImagingPlane>(which is stored in/general/optophysiology)Text dataset
image_plane_nameof<ImageSegmentation>is now a link to the corresponding<ImagingPlane>(which is stored in/general/optophysiology). The dataset is also renamed toimage_planefor consistency with<TwoPhotonSeries>Text dataset
electrode_nameof<PatchClampSeries>is now a link to the corresponding<IntracellularElectrode>(which is stored in/general/intracellular_ephys). The dataset is also renamed toelectrodefor consistency.Text dataset
sitein<OptogeneticSeries>is now a link to the corresponding<StimulusSite>(which is stored in/general/optogenetics).Integer dataset
electrode_idxofFeatureExtractionis now a datasetelectrodesof type DynamicTableRegion pointing to a region of theElectrodeTablestored in/general/extracellular_ephys/electrodes.Integer array dataset
electrode_idxof<ElectricalSeries>is now a datasetelectrodesof type DynamicTableRegion pointing to a region of theElectrodeTablestored in/general/extracellular_ephys/electrodes.Text dataset
/general/extracellular_ephys/<electrode_group_X>/deviceis now a link<ElectrodeGroup>/deviceThe Epochs , Unit, Trial and other dynamic tables in NWB 2 also support (and use) region and object references to explicitly reference other data (e.g., vector data as part of the unit tables).
Improved consistency, identifiably, and readability
Improved identifiably of objects
Change: All groups and datasets are now required to either have a unique name or a unique neurodata_type defined.
Reason: This greatly simplifies the unique identification of objects with variable names.
Format Changes: Defined missing neurodata_types for a number of objects, e.g.,:
Group
/general/optophysiology/<imaging_plane_X>now has the neurodata typeImagingPlaneGroup
/general/intracellular_ephys/<electrode_X>now has the neurodata typeIntracellularElectrodeGroup
/general/optogenetics/<site_X>now has the neurodata typeStimulusSite…
To enable identification of the type of objects, the neurodata_type is stored in HDF5 files as an
attribute on the corresponding object (i.e., group or dataset). Also information about the namespace
(e.g., the name and version) are stored as attributed to allow unique identification of the specification
for storage objects.
Simplified extension of subject metadata
Specific Change: Assigned neurodata_type to /general/subject to enable extension of the subject container
directly without having to extend NWBFile itself. (see https://github.com/NeurodataWithoutBorders/nwb-schema/issues/120
and https://github.com/NeurodataWithoutBorders/nwb-schema/pull/121 for details)
Reduce requirement for potentially empty groups
Change: Make several previously required fields optional
Reason: Reduce need for empty groups.
Format Changes: The following groups/datasets have been made optional:
/epochs: not all experiments may require epochs.
/general/optogenetics: not all experiments may use optogenetic data
devicein IntracellularElectrode
Added missing metadata
Change: Add a few missing metadata attributes/datasets.
Reason: Ease data interpretation, improve format consistency, and enable storage of additional metadata
Format Changes:
/general/devicestext dataset becomes group with neurodata typeDeviceto enable storage of more complex and structured metadata about devices (rather than just a single string)Added attribute
unit=Secondsto<EventDetection>/timesdataset to explicitly describe time units and improve human and programmatic data interpretationAdded
filteringdataset to type<IntracellularElectrode>(i.e.,/general/intracellular_ephys/<electrode_X>) to enable specification of per-electrode filtering dataAdded default values for
<TimeSeries>/descriptionand<TimeSeries>/comments
Improved Consistency
Change: Rename objects, add missing objects, and refine types
Reason: Improve consistency in the naming of data objects that store similar types of information in different places and ensure that the same kind of information is available.
Format Changes:
Added missing
helpattribute for<BehavioralTimeSeries>to improve consistency with other types as well as human data interpretationRenamed dataset
image_plan_namein<ImageSegmentation>toimage_planeto ensure consistency in naming with<TwoPhotonSeries>Renamed dataset
electrode_namein<PatchClampSeries>toelectrodefor consistency (and since the dataset is now a link, rather than a text name).Renamed dataset
electrode_idxin<FeatureExtraction>toelectrode_groupfor consistency (and since the dataset is now a link to the<ElectrodeGroup>)Renamed dataset
electrode_idxin<ElectricalSeries>toelectrode_groupfor consistency (and since the dataset is now a link to the<ElectrodeGroup>)Changed
imaging_ratefield in ImagingPlane from text to float. See PR697 (PyNWB) and I136 (nwb-schema) for details
Added keywords field
Change: Added keywords fields to /general
Reason: Data archive and search tools often rely on user-defined keywords to facilitate discovery. This enables users to specify keywords for a file. (see PR620 (PyNWB))
Removed source field
Change: Remove required attribute source from all neurodata_types
Reason: In NWB 1.0.x the attribute source was defined as a free text entry
intended for storage of provenance information. In practice, however, this
attribute was often either ignored, contained no useful information, and/or
was misused to encode custom metadata (that should have been defined via extensions).
Specific Change: Removed attribute source from the core base neurodata_types
which effects a large number of the types throughout the NWB schema. For further
details see PR695 (PyNWB))
Removed ancestry field
Change: Removed the explicit specification of ancestry as an attribute as part of the format specification
Reason: 1) avoid redundant information as the ancestry is encoded in the inheritance of types, 2) ease maintenance, and 3) avoid possible inconsistencies between the ancestry attribute and the true ancestry (i.e., inheritance hierarchy) as defined by the spec.
Note The new specification API as part of PyNWB/HDMF makes the ancestry still easily accessible to users. As the ancestry can be easily extracted from the spec, we currently do not write a separate ancestry attribute but this could be easily added if needed. (see also PR707 (PyNWB), I24 (nwb-schema))
Improved organization of processed and acquisition data
Improved organization of processed data
Change: Relaxed requirements and renamed and refined core types used for storage of processed data.
Reason: Ease user intuition and provide greater flexibility for users.
Specific Changes: The following changes have been made to the organization of processed data:
- Module has been renamed to ProcessingModule to avoid possible confusion
and to clarify its purpose. Also ProcessingModule may now contain any NWBDataInterface.
With NWBDataInterface now being a general base class of TimeSeries, this means that it is now possible to define data processing types that directly inherit from TimeSeries, which was not possible in NWB 1.x.
Interface has been renamed to NWBDataInterface to avoid confusion and ease intuition (see above)
All Interface types in the original format had fixed names. The fixed names have been replaced by specification of corresponding default names. This change enables storage of multiple instances of the same analysis type in the same ProcessingModule by allowing users to customize the name of the data processing types, whereas in version 1.0.x only a single instance of each analysis could be stored in a ProcessingModule due to the requirement for fixed names.
Simplified organization of acquisition data
Specific Changes:
/acquisitionmay now store any primary data defined via an NWBDataInterface type (not just TimeSeries).
/acquisition/timeseriesand/acquisition/imageshave been removedCreated a new neurodata_type Images for storing a collection of images to replace
acquisition/imagesand provide a more general container for use elsewhere in NWB (i.e., this is not meant to replace ImageSeries)
Other changes:
- PR765 made the timestamps in
SpikeEventSeries required
Improved governance and accessibility
Change: Updated release and documentation mechanisms for the NWB format specification
Reason: Improve governance, ease-of-use, extensibility, and accessibility of the NWB format specification
Specific Changes
The NWB format specification is now released in separate Git repository
Format specifications are released as YAML files (rather than via Python .py file included in the API)
Organized core types into a set of smaller YAML files to ease overview and maintenance
Converted all documentation documents to Sphinx reStructuredText to improve portability, maintainability, deployment, and public access
Sphinx documentation for the format are auto-generated from the YAML sources to ensure consistency between the specification and documentation
The PyNWB API now provides dedicated data structured to interact with NWB specifications, enabling users to programmatically access and generate format specifications
Specification language changes
Change: Numerous changes have been made to the specification language itself in NWB 2.0. Most changes to the specification language effect mainly how the format is specified, rather than the actual structure of the format. The changes that have implications on the format itself are described next. For an overview and discussion of the changes to the specification language see specification language release notes.
Specification of dataset dimensions
Change: Updated the specification of the dimensions of dataset
Reason: To simplify the specification of dimension of datasets and attribute
Format Changes:
The shape of various dataset is now specified explicitly for several datasets via the new
shapekeyThe
unitfor values in a dataset are specified via an attribute on the dataset itself rather than viaunitdefinitions in structs that are available only in the specification itself but not the format.In some cases the length of a dimension was implicitly described by the length of structs describing the components of a dimension. This information is now explicitly described in the
shapeof a dataset.
Added Link type
Change Added new type for links
Reason:
Links are usually a different type than datasets on the storage backend (e.g., HDF5)
Make links more readily identifiable
Avoid special type specification in datasets
Format Changes: The format itself is not affected by this change aside from the fact that datasets that were links are now explicitly declared as links.
Removed datasets defined via autogen
Change Support for autogen has been removed from the specification language. After review
of all datasets that were produced via autogen it was decided that all autogen datasets should be
removed from the format.
Reason The main reasons for removal of autogen dataset is to ease use and maintenance of NWB files by 1) avoiding redundant storage of information (i.e., improve normalization of data) and 2) avoiding dependencies between data (i.e., datasets having to be updated due to changes in other locations in a file).
Format Changes
Datasets/Attributes that have been removed due to redundant storage of the path of links stored in the same group:
IndexSeries/indexed_timeseries_path
RoiResponseSeries/segmentation_interface_path
ImageMaskSeries/masked_imageseries_path
ClusterWaveforms/clustering_interface_path
EventDetection/source_electricalseries_path
MotionCorrection/image_stack_name/original_path
NWBFile/epochs/epoch_X.links
Datasets//Attributes that have been removed because they stored only a list of groups/datasets (of a given type or property) in the current group.
Module.interfaces (now ProcessingModule)
ImageSegmentation/image_plane/roi_list
UnitTimes/unit_list
TimeSeries.extern_fields
TimeSeries.data_link
TimeSeries.timestamp_link
TimeSeries.missing_fields
Other datasets/attributes that have been removed to ease use and maintenance because the data stored is redundant and can be easily extracted from the file:
NWBFile/epochs.tags
TimeSeries/num_samples
Clustering/cluster_nums
Removed 'neurodata\_type=Custom'
Change The 'neurodata\_type=Custom' has been removed.
Reason All additions of data should be governed by extensions. Custom datasets can be identified based on the specification, i.e., any objects that are not part of the specification are custom.
1.0.x (09/2015 - 04/2017)
NWB 1.0.x has been deprecated. For documents relating to the 1.0.x schema please see https://github.com/NeurodataWithoutBorders/specification_nwbn_1_0_x.
1.0.6, April 8, 2017
Minor fixes:
Modify <IntervalSeries>/ documentation to use html entities for < and >.
Fix indentation of unit attribute data_type, and conversion attribute description in
/general/optophysiology/<imaging_plane_X>/manifold.Fix typos in
<AnnotationSeries>/conversion, resolution and unit attributes.Update documentation for
IndexSeriesto reflect more general usage.Change to all numerical version number to remove warning message when installing using setuptools.
1.0.5i_beta, Dec 6, 2016
Removed some comments. Modify author string in info section.
1.0.5h_beta, Nov 30, 2016
Add dimensions to /acquisition/images/<image_X>
1.0.5g_beta, Oct 7, 2016
Replace group options:
autogen: {"type": "create"}and"closed": Truewith"\_properties": {"create": True}and"\_properties": {"closed": True}. This was done to make the specification language more consistent by having these group properties specified in one place ("\_properties"dictionary).
1.0.5f_beta, Oct 3, 2016
Minor fixes to allow validation of schema using json-schema specification in file
meta-schema.pyusing utilitycheck\_schema.py.
1.0.5e_beta, Sept 22, 2016
Moved definition of
<Module>/out of/processinggroup to allow creating subclasses of Module. This is useful for making custom Module types that specified required interfaces. Example of this is inpython-api/examples/create\_scripts/module-e.pyand the extension it uses (extensions/e-module.py).Fixed malformed html in
nwb\_core.pydocumentation.Changed html generated by
doc\_tools.pyto html5 and fixed so passes validation at https://validator.w3.org.
1.0.5d_beta, Sept 6, 2016
Changed ImageSeries img_mask dimensions to:
"dimensions": ["num\_y","num\_x"]to match description.
1.0.5c_beta, Aug 17, 2016
Change IndexSeries to allow linking to any form of TimeSeries, not just an
ImageSeries
1.0.5b_beta, Aug 16, 2016
Make
'manifold'and'reference\_frame'(under/general/optophysiology) recommended rather than required.In all cases, allow subclasses of a TimeSeries to fulfill validation requirements when an instance of TimeSeries is required.
Change unit attributes in
VoltageClampSeriesseries datasets from required to recommended.Remove
'const'=TruefromTimeSeriesattributes inAnnotationSeriesandIntervalSeries.Allow the base
TimeSeriesclass to store multi-dimensional arrays in'data'. A user is expected to describe the contents of ‘data’ in the comments and/or description fields.
1.0.5a_beta, Aug 10, 2016
Expand class of Ids allowed in TimeSeries missing\_fields attribute to
allow custom uses.
1.0.5_beta Aug 2016
Allow subclasses to be used for merges instead of base class (specified by
'merge+'in format specification file).Use
'neurodata\_type=Custom'to flag additions that are not describe by a schema.Exclude TimeSeries timestamps and starting time from under
/stimulus/templates
1.0.4_beta June 2016
Generate documentation directly from format specification file.”
Change ImageSeries
external\_fileto an array.Made TimeSeries description and comments recommended.
1.0.3 April, 2016
Renamed
"ISI\_Retinotopy"to"ISIRetinotopy"Change
ImageSeriesexternal\_fileto an array. Added attributestarting\_frame.Added
IZeroClampSeries.
1.0.2 February, 2016
Fixed documentation error, updating
'neurodata\_version'to'nwb\_version'Created
ISI\_RetinotopyinterfaceIn
ImageSegmentationmodule, movedpix\_mask::weightattribute to be its own dataset, namedpix\_mask\_weight. Attribute proved inadequate for storing sufficiently large array data for some segmentsMoved
'gain'field fromCurrent/VoltageClampSeriesto parentPatchClampSeries, due need of stimuli to sometimes store gainAdded Ken Harris to the Acknowledgements section
1.0.1 October 7th, 2015
Added
'required'field to tables in the documentation, to indicate ifgroup/dataset/attributeis required, standard or optionalObsoleted
'file\_create\_date'attribute'modification\_time'and madefile\_create\_datea text arrayRemoved
'resistance\_compensation'fromCurrentClampSeriesdue being duplicate of another fieldUpgraded
TwoPhotonSeries::imaging\_planeto be a required valueRemoved
'tags'attribute to group ‘epochs’ as it was fully redundant with the'epoch/tags'datasetAdded text to the documentation stating that specified sizes for integer values are recommended sizes, while sizes for floats are minimum sizes
Added text to the documentation stating that, if the
TimeSeries::data::resolutionattribute value is unknown then store aNaNDeclaring the following groups as required (this was implicit before)
acquisition/
\_ images/
\_ timeseries/
analysis/
epochs/
general/
processing/
stimulus/
\_ presentation/
\_ templates/
This is to ensure consistency between .nwb files, to provide a minimum
expected structure, and to avoid confusion by having someone expect time
series to be in places they’re not. I.e., if 'acquisition/timeseries' is
not present, someone might reasonably expect that acquisition time
series might reside in 'acquisition/'. It is also a subtle reminder
about what the file is designed to store, a sort of built-in
documentation. Subfolders in 'general/' are only to be included as
needed. Scanning 'general/' should provide the user a quick idea what
the experiment is about, so only domain-relevant subfolders should be
present (e.g., 'optogenetics' and 'optophysiology'). There should always
be a 'general/devices', but it doesn’t seem worth making it mandatory
without making all subfolders mandatory here.
1.0.0 September 28th, 2015
Convert document to .html
TwoPhotonSeries::imaging\_planewas upgraded to mandatory to help enforce inclusion of important metadata in the file.